
标签: 数据分析
数据网格原则和逻辑架构
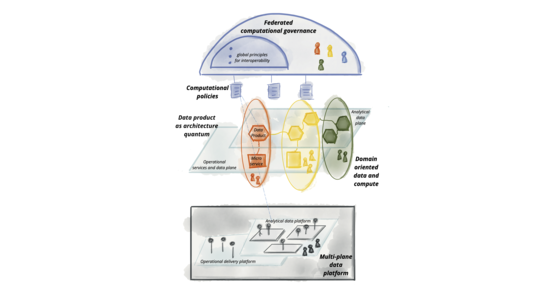
我们渴望通过数据增强和改进商业和生活的方方面面,这需要我们改变大规模管理数据的方式。 过去十年的技术进步解决了数据量和数据处理计算的规模问题,但它们未能解决其他方面的规模问题:数据环境的变化、数据源的激增、数据用例和用户的多样性,以及对变化的响应速度。 数据网格解决了这些维度问题,它基于四个原则:面向领域的去中心化数据所有权和架构、数据即产品、自助数据基础设施即平台,以及联邦计算治理。 每个原则都推动了对技术架构和组织结构的新逻辑视图。
如何从单体数据湖迁移到分布式数据网格
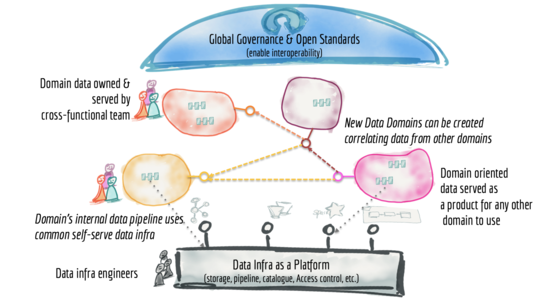
许多企业正在投资于他们的下一代数据湖,希望大规模地实现数据民主化,以提供业务洞察力,并最终做出自动化的智能决策。 基于数据湖架构的数据平台具有常见的故障模式,这些故障模式会导致大规模无法兑现的承诺。 为了解决这些故障模式,我们需要从湖泊或其前身数据仓库的集中式范式转变。 我们需要转向一种借鉴现代分布式架构的范式:将领域视为一等公民,应用平台思维来创建自助数据基础设施,并将数据视为产品。
不要比较平均值
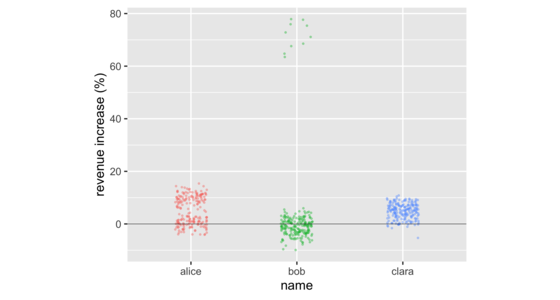
在商务会议中,通常通过比较平均值来比较几组数字。 但这样做往往会隐藏这些组中数字分布的重要信息。 有许多数据可视化可以揭示这些信息。 这些包括条形图、直方图、密度图、箱线图和小提琴图。 这些都很容易用免费软件制作,可以处理小到十几组,大到几千组的数据。
隐私增强技术:面向技术人员的介绍
隐私增强技术 (PET) 是指为其数据由软件和系统处理、存储和/或收集的人员提供更多隐私或保密性的技术。 三种有价值且可供使用的 PET 是:差分隐私、分布式和联合分析与学习,以及加密计算。 它们为隐私提供了严格的保障,因此越来越受欢迎,可以在提供数据的同时最大限度地减少对私人数据的侵犯。
机器学习的持续交付
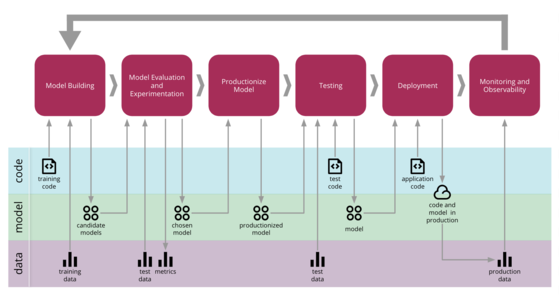
机器学习应用程序在我们的行业中越来越受欢迎,但是与更传统的软件(例如 Web 服务或移动应用程序)相比,开发、部署和持续改进机器学习应用程序的过程更加复杂。 它们在三个方面都会发生变化:代码本身、模型和数据。 它们的行为通常很复杂且难以预测,而且更难测试、更难解释和更难改进。 机器学习持续交付 (CD4ML) 是将持续交付原则和实践应用于机器学习应用程序的学科。
双时态历史
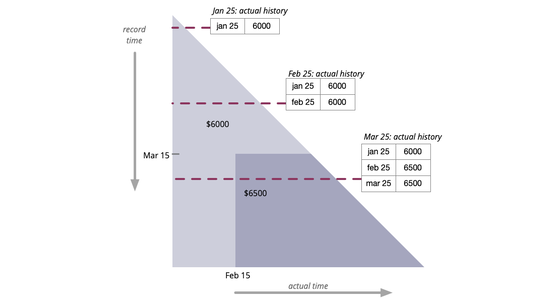
通常需要访问某些属性的历史值。 但有时,为了响应追溯更新,历史本身也需要修改。 双时态历史将时间视为两个维度:实际历史记录了在信息完美传输的情况下历史应该是什么样的,而记录历史则记录了我们对历史的了解是如何变化的。
数据网格加速研讨会

加速意味着更快地移动,获得速度。 有效地处理数据对于任何想要在现代世界中蓬勃发展的组织来说都是关键,而数据网格正在向组织展示如何大规模地从数据中实现价值。 数据网格加速研讨会通过了解团队和组织的当前状态并探索下一步将是什么样子,帮助他们加速数据网格转型。
不要将数据科学笔记本投入生产
我们遇到过许多客户,他们有兴趣采用数据科学家开发的计算笔记本,并将其直接放入生产应用程序的代码库中。 数据科学思想确实需要从笔记本中移出并投入生产,但试图将笔记本作为代码工件进行部署会破坏许多良好的软件实践。 可以预见,这会导致许多观察到的痛点。 这种行为是一个更深层次问题的症状:数据科学家和软件开发人员之间缺乏协作。
不断演变的数据全景
我们在 2012 年伦敦 QCon 大会上的主题演讲探讨了数据在我们生活中所扮演的角色(它所做的不仅仅是变得更大)。 我们首先来看看数据世界是如何变化的:它在不断增长,变得更加分散和互联。 然后我们转向行业的反应:NoSQL 的兴起、向服务集成的转变、事件溯源的出现、云的影响以及更加注重可视化的新分析。 我们快速了解一下数据目前的用途,Rebecca 特别强调了发展中国家的数据。 最后,我们考虑所有这一切对我们作为软件专业人员的个人责任意味着什么。
思考大数据
“大数据”已迅速跃升为我们行业中最炒作的术语之一,但这种炒作不应掩盖一个事实,即这是数据在世界中作用的真正重大转变。 数据源的数量、速度和价值都在迅速增加。 数据管理必须在五个方面发生变化:从更广泛的来源提取数据、采用新的数据库和集成方法改变数据管理的物流、在运行分析项目中使用敏捷原则、强调数据解释技术以区分信号和噪声,以及精心设计的可视化以使信号更易于理解。 总之,这意味着我们不需要大型分析项目,而是希望新的数据思维能够渗透到我们的日常工作中。
BigQuery 的概念验证
谷歌新的 BigQuery 服务能否在不需要昂贵软件或新基础设施的情况下为客户提供大数据分析能力? Thoughtworks 和 AutoTrader 使用海量数据集进行了一周的概念验证测试。 测试表明,在 7.5 亿行数据集上,查询性能始终保持在 7-10 秒的范围内。 我们将 REST API 与 Java、JavaScript 和 Google Charts 结合使用,创建了一个 Web 前端,其中包含查询结果的交互式可视化效果。 整个练习由三个人在五天内完成。 结论:BigQuery 表现良好,可以使拥有大数据和较少预算的组织受益,尤其是那些没有数据仓库或数据仓库使用受限的组织。
NoSQL 简介
在 goto Aarhus 大会上,我们有一个关于 NoSQL 实践经验的主题。 我被要求做一个开场演讲,解释 NoSQL 数据存储的基本原理。 我谈到了 NoSQL 的起源、NoSQL 数据模型的形式、许多 NoSQL 数据库考虑一致性问题的方式,以及多语言持久化的重要性。
与 Dave Farley 的工程室对话
我的老同事 Dave Farley 在 YouTube 上开设了一个关于软件开发的频道,该频道越来越受欢迎。 这是一个很好的素材,与我自己的观点非常一致,毕竟他的经验对我的思想有很大影响。 我们谈论了一系列关于软件工程当前角色的话题,特别关注我目前支持的三个大型写作项目:数据网格、分布式系统模式和遗留系统替换模式。
数据在软件开发中的演变角色
由于无法前往澳大利亚参加 2020 年的 XConf 大会,我改为与 Thoughtworks 澳大利亚技术负责人 Scott Shaw 进行了一次 Zoom 会议。 我们谈到了数据在现代应用程序开发中不断变化的作用:应用程序开发人员和数据库之间的鸿沟、由于大数据(和混乱数据)的出现而发生的变化、提高数据素养的需求,以及收集投机性数据的社会影响。
数据不同
Em Grasmeder,我们的欧洲“数据女巫”,和我原本计划在欧洲的 XConf 系列会议上发表主题演讲。 由于是 2020 年,我们改为使用 Zoom 进行了会议,并讨论了数据科学家的角色:这个角色究竟是什么、他们需要掌握的工具,以及他们与其他形式软件开发的关系。
使用 R 语言的 ggplot2 库绘制柔和的意面线图
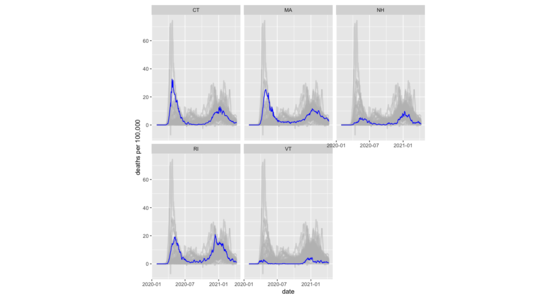
我如何使用 R 语言绘制柔和的意面线图,包括分面。
公共仪表板

随着人们对数据分析和可视化的兴趣日益浓厚,我们看到人们正在更加努力地创建有趣的可视化效果,以便人们能够从组织中流动的数据中获得洞察力。 这些仪表板大多面向个人使用,但越来越多地用于更公共的目的。
计算笔记本
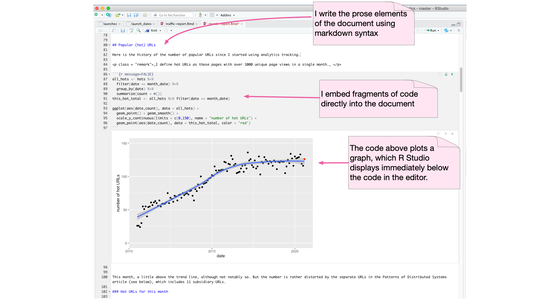
计算笔记本是一个用于编写散文文档的环境,它允许作者嵌入代码,这些代码可以轻松执行,结果也会合并到文档中。 这是一个特别适合数据科学工作的平台。 这样的环境包括 Jupyter Notebook、R Markdown、Mathematica 和 Emacs 的 org-mode。
数据湖
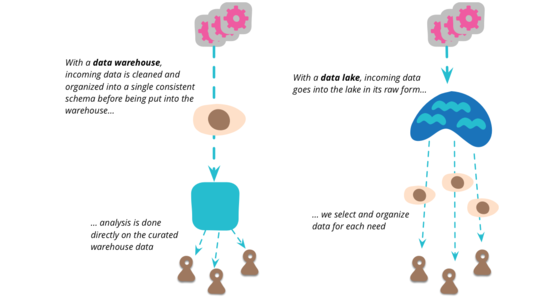
数据湖是近十年来出现的一个术语,用于描述大数据领域中数据分析管道的一个重要组成部分。其理念是为组织中任何可能需要分析的人提供一个存储所有原始数据的单一存储库。通常人们使用 Hadoop 来处理数据湖中的数据,但这个概念比 Hadoop 更广泛。
数据最小化原则(Datensparsamkeit)
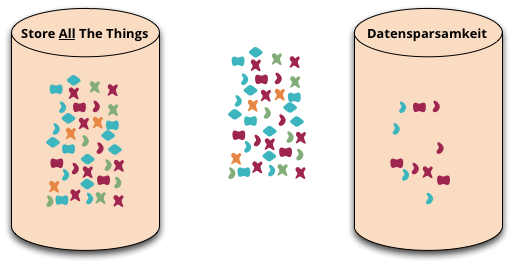
Datensparsamkeit 是一个德语单词,很难准确地翻译成英语。它是一种关于我们如何捕获和存储数据的态度,即我们应该只处理我们真正需要的数据。
机器辩护
我记得在我十几岁的时候,有人告诉我人工智能 (AI) 在未来几年将会做出的奇妙事情。几十年后的今天,其中一些似乎正在发生。最近的一次胜利是计算机通过互相博弈来学习围棋,并迅速变得比任何人类都更加精通,其策略人类专家几乎无法理解。人们很自然地会想知道未来几年会发生什么,计算机是否很快就会拥有比人类更高的智能?(鉴于最近的一些选举结果,这可能不是一个难以跨越的门槛。)
但当我听到这些时,我想起了巴勃罗·毕加索几十年前对计算机的评论:“计算机毫无用处。它们只能给你答案”。像机器学习这样的技术所能产生的推理能力,其结果确实令人印象深刻,并将对我们作为软件的用户和开发者有所帮助。但答案虽然有用,却并不总是完整的画面。我在学校的早期就学到了这一点——仅仅提供数学题的答案只能让我得到几分,要得到满分,我必须展示我是“如何”得到答案的。得出答案的推理过程比结果本身更有价值。这就是自学成才的围棋人工智能的局限性之一。虽然它们可以获胜,但它们无法解释自己的策略。
概率文盲
在我写这篇文章的时候,美国总统大选即将结束,关于Nate Silver做出的预测出现了一场附带的辩论。许多共和党人声称他是民主党的托儿,他对奥巴马获胜概率为 85% 的预测是假的。我的一部分人希望我认识更多不识数的共和党人,这样我就可以和他们打赌了。也许更好的愿望是民意调查结果相反,因为我认识更多倾向于民主党的的朋友。事实上,无论哪种方式,我都不会获得太多,因为我认识的大多数人都是识数的。可悲的是,这种情况并不普遍——这场闹剧说明了大多数人对概率的严重无知,这对整个社会,特别是软件开发,都有一些重要的影响。