
标签: 非关系型数据库
非关系型数据库简介
在 奥尔胡斯 Goto 大会 上,我们有一个关于非关系型数据库实践经验的专题讨论。我被邀请做一个开场演讲,解释非关系型数据库的基本原理。我谈到了非关系型数据库的起源、非关系型数据库数据模型的形式、许多非关系型数据库如何看待一致性问题,以及多语言持久化的重要性。
无模式数据结构

近年来,关于无模式数据的优势的讨论越来越多。无模式是人们对 非关系型数据库 感兴趣的主要原因之一。但是,无模式涉及许多微妙之处,无论是在数据库还是在内存数据结构方面都是如此。这些微妙之处既体现在无模式的含义上,也体现在使用无模式方法的优缺点上。
《非关系型数据库精粹》要点
在我们设计《非关系型数据库精粹》这本书时,我们在大多数章节的结尾都总结了一些要点,以便读者在重读时能够快速回顾。我们在网站上也包含了这些要点,以便读者能够以另一种方式提醒自己。
人们 vs. 非关系型数据库:小组讨论
奥尔胡斯 Goto 大会 上的一个专题讨论为非关系型数据库供应商提供了一个机会,让他们可以谈论各自的工具。在专题讨论结束时,各位演讲者被安排在一个小组中,讨论一些与非关系型数据库有关的常见问题。虽然我没有参与这个专题讨论(我的演讲 是在几天后进行的),但我参与了小组讨论。
不断演变的数据全景
我们在 2012 年伦敦 QCon 大会上的主题演讲探讨了数据在我们生活中所扮演的角色(它不仅仅是在变得越来越大)。我们首先看一下数据世界是如何变化的:它正在增长,变得更加分布式和互联。然后,我们来看看行业的反应:非关系型数据库的兴起、向服务集成的转变、事件溯源的出现、云计算的影响以及更加注重可视化的新分析方法。我们快速地看一下数据是如何被使用的,Rebecca 特别强调了发展中国家的数据。最后,我们考虑了所有这一切对我们作为软件专业人员的个人责任意味着什么。
未来不是非关系型数据库,而是多语言持久化
这是一篇关于企业数据存储未来的信息图,主要面向那些参与应用程序开发管理的人员。它解释了为什么关系型数据库一直占据主导地位,为什么非关系型数据库正在挑战这一假设,并概述了多语言持久化的未来,即根据应用程序的不同需求,将使用多种数据存储技术。
数据库解冻
几年前,我听到编程语言界的人谈论 Java 造成的语言“核冬天”。他们感觉,每个人都对 Java 的计算模型(当时 C# 被视为山寨货)趋之若鹜,以至于编程语言的创造力已经消失殆尽。这种感觉现在正在消退,但也许更重要的是,关于数据库的思考——这种更长久、更深层次的冻结——可能正在开始解冻。
没有数据库管理员

在许多组织中,人们期望将所有持久性数据存储在由中央数据库管理组管理的关系型数据库中。这种集中控制的原因有很多,通常是为了使用 集成数据库。中央数据组担心的是防止格式错误的数据、可能降低重要共享资源速度的查询,以及确保整个企业的数据模型一致。
这些目标可能是值得追求的,但它们的一个后果是存储数据需要相当多的繁文缛节。我经常听到人们抱怨说,仅仅为了在数据库中添加一列,就需要花费数周时间来处理变更单。对于习惯于短周期演进式设计的现代应用程序开发人员来说,这种繁文缛节太慢了,更不用说太烦人了。
因此,应用程序开发团队告诉我,他们使用 非关系型数据库 来绕过数据库管理员。他们在这种情况下使用的是“仅仅是数据存储”,而不是“真正的数据库”,这很有帮助。这样一来,数据库管理员就可以置身事外,他们通常不知道,或者乐于不去关心。
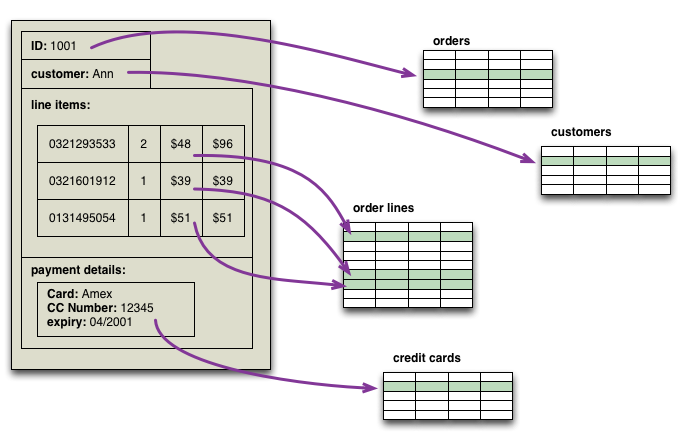
非关系型数据库的定义
在我们开始编写《非关系型数据库精粹》这本书时,我们就面临着一个棘手的难题——我们要写的是什么?究竟什么是“非关系型数据库”?这个概念没有明确的定义,没有商标,没有标准组织,甚至没有宣言。
多语言持久化
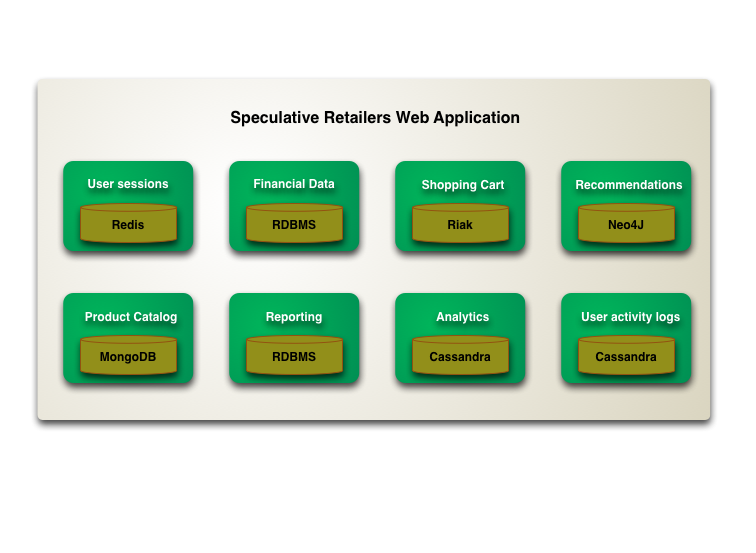
2006 年,我的同事 Neal Ford 首次提出了 多语言编程 一词,以表达应用程序应该用多种语言编写的想法,以便利用不同语言适合解决不同问题的优势。复杂的应用程序会结合不同类型的问题,因此,为工作选择合适的语言可能比试图将所有方面都塞进一种语言更有效率。
在过去的几年里,人们对新语言(尤其是函数式语言)的兴趣激增,我经常想花些时间研究一下 Clojure、Scala、Erlang 等语言。但我的时间有限,我正在优先考虑另一个更重大的转变,那就是 数据库解冻。最初的迹象已经从客户和其他联系人那里传来,前景十分诱人。我可以自信地说,如果你要开始开发一个新的战略性企业应用程序,就不应该再想当然地认为你的持久化应该是关系型的。关系型数据库可能是正确的选择——但你应该认真考虑其他选择。