
面向聚合的数据库
2012年1月19日

在我们编写Nosql Distilled时,最先想到的主题之一是 NoSQL 数据库使用与关系模型不同的数据模型。我所查看的大多数资料都提到了至少四组数据模型:键值对、文档、列族和图。查看这个列表,前三者之间存在很大的相似性 - 它们都具有一个基本存储单元,该单元是紧密相关数据的丰富结构:对于键值对存储,它是值,对于文档存储,它是文档,对于列族存储,它是列族。用 DDD 的术语来说,这组数据是一个DDD_Aggregate。
NoSQL 数据库的兴起主要受制于对在大型集群(如 Google 和 Amazon 使用的设置)上有效存储数据的渴望。关系数据库并非为集群而设计,这就是人们四处寻找替代方案的原因。将聚合作为基本单元存储对于在集群上运行非常有意义。聚合为分片等分布策略提供了自然的单元,因为您拥有一个预计将一起访问的大块数据。
聚合对于应用程序程序员来说也很有意义。如果您正在捕获一屏幕信息并将其存储在关系数据库中,则必须将该信息分解成行才能将其存储起来。
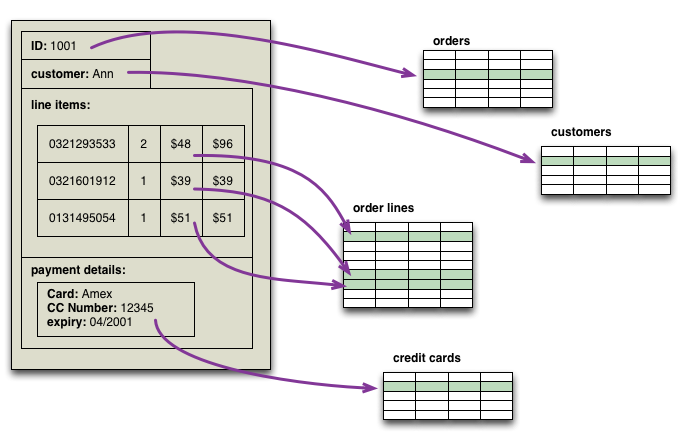
聚合使映射变得更加简单 - 这就是为什么许多 NoSQL 数据库的早期采用者报告说它是一个更简单的编程模型。
编程模型和分布模型之间的这种协同作用非常宝贵。它允许数据库利用其对应用程序程序员如何对数据进行聚类的了解来帮助提高整个集群的性能。
存在一个明显的缺点 - 当数据访问与聚合一致时,整个方法效果很好,但如果您想以不同的方式查看数据怎么办?订单输入自然地将订单存储为聚合,但分析产品销售额会跨越聚合结构。在数据库中不使用聚合结构的优势在于,它允许您以不同的方式为不同的受众切片和切块数据。
这就是为什么面向聚合的存储如此重视 map-reduce - 这是一个非常适合在集群上运行的编程模式。Map-reduce 作业可以将数据重新组织成不同的组,以供不同的读者使用 - 许多人称之为物化视图。但这比使用关系模型要多做一些工作。
这是对PolyglotPersistence的论据的一部分 - 当您正在操作明确的聚合时(尤其是当您在集群上运行时)使用面向聚合的数据库,而当您想以不同的方式操作该数据时使用关系数据库(或图数据库)。