
数据湖
2015年2月5日

数据湖是本世纪出现的术语,用于描述大数据世界中数据分析管道的重要组成部分。其理念是为组织中任何可能需要分析的人提供所有原始数据的单一存储库。通常人们使用 Hadoop 来处理数据湖中的数据,但这个概念比 Hadoop 更广泛。
当我听到关于将组织想要分析的所有数据整合到一个单一位置时,我立即想到数据仓库(以及数据集市[1])的概念。但数据湖和数据仓库之间存在着至关重要的区别。数据湖存储的是原始数据,以数据源提供的任何形式存储。对数据的模式没有假设,每个数据源可以使用任何它喜欢的模式。由数据的消费者来根据自己的目的理解这些数据。
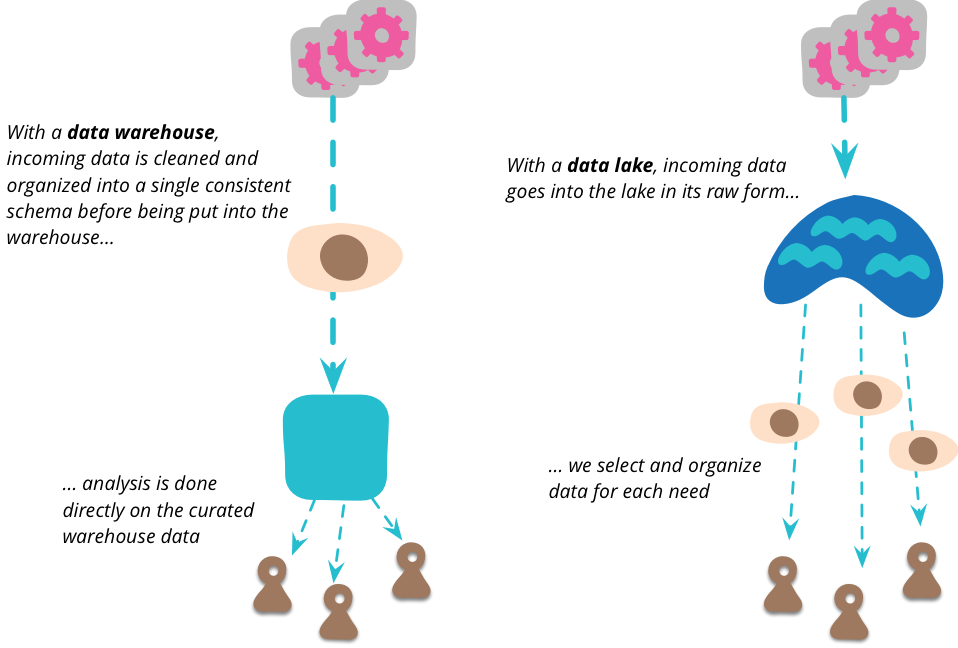
这是一个重要的步骤,许多数据仓库项目由于模式问题而进展不顺利。数据仓库倾向于使用所有分析需求的单一模式,但我认为,除了最小的组织之外,单一统一数据模型是不切实际的。即使要对一个稍微复杂的领域进行建模,你也需要多个边界上下文,每个上下文都有自己的数据模型。在分析方面,你需要每个分析用户使用一个对他们正在进行的分析有意义的模型。通过转向仅存储原始数据,这将责任明确地放在了数据分析师身上。
数据仓库项目遇到的另一个问题是确保数据质量。试图获得数据的权威单一来源需要对不同系统如何获取和使用数据进行大量分析。系统 A 可能适合某些数据,而系统 B 适合其他数据。你会遇到一些规则,例如系统 A 更适合最近的订单,而系统 B 更适合一个月或更长时间以前的订单,除非涉及退货。除此之外,数据质量通常是一个主观问题,不同的分析对数据质量问题的容忍度不同,甚至对什么是好质量的看法也不同。
这导致了对数据湖的一个常见批评——它只是一个用于存储各种质量数据的垃圾场,更适合称为数据沼泽。这种批评既有道理又无关紧要。新分析的热门头衔是“数据科学家”。虽然这是一个被滥用的头衔,但许多这类人确实拥有扎实的科学背景。任何严肃的科学家都知道数据质量问题。想想你可能认为的简单的事情,比如分析一段时间内的温度读数。你必须考虑到一些气象站的迁移方式可能会微妙地影响读数,设备故障导致的异常,传感器无法工作导致的缺失时间段。许多复杂的统计技术都是为了解决数据质量问题而创建的。科学家总是对数据质量持怀疑态度,并且习惯于处理可疑的数据。因此,对他们来说,数据湖很重要,因为他们可以处理原始数据,并且可以有目的地应用技术来理解它,而不是某种不透明的数据清洗机制,这种机制可能弊大于利。
数据仓库通常不会仅仅清洗数据,还会将数据聚合到更容易分析的形式。但科学家也倾向于反对这一点,因为聚合意味着丢弃数据。数据湖应该包含所有数据,因为你不知道人们现在或几年后会发现什么有价值的东西。
我的一位同事用一个最近的例子说明了这种想法:“我们试图比较我们自动化的预测模型与公司合同经理做出的手动预测。为此,我们决定用一年前的数据训练我们的模型,并将我们的预测与当时经理做出的预测进行比较。由于我们现在知道正确的结果,这应该是一个公平的准确性测试。当我们开始这样做时,似乎经理的预测很糟糕,即使是我们简单的模型,只用了两周时间就做出来了,也远远超过了他们。我们怀疑这种优异的表现太好了,不像是真的。经过大量的测试和挖掘,我们发现与那些经理预测相关的时间戳是不正确的。它们被某些月末处理报告修改了。简而言之,数据仓库中的这些值毫无用处;我们担心我们将无法进行这种比较。经过进一步的挖掘,我们发现这些报告已被存储,因此我们可以提取当时做出的真实预测。(我们再次打败了他们,但这花了几个月的时间)。"
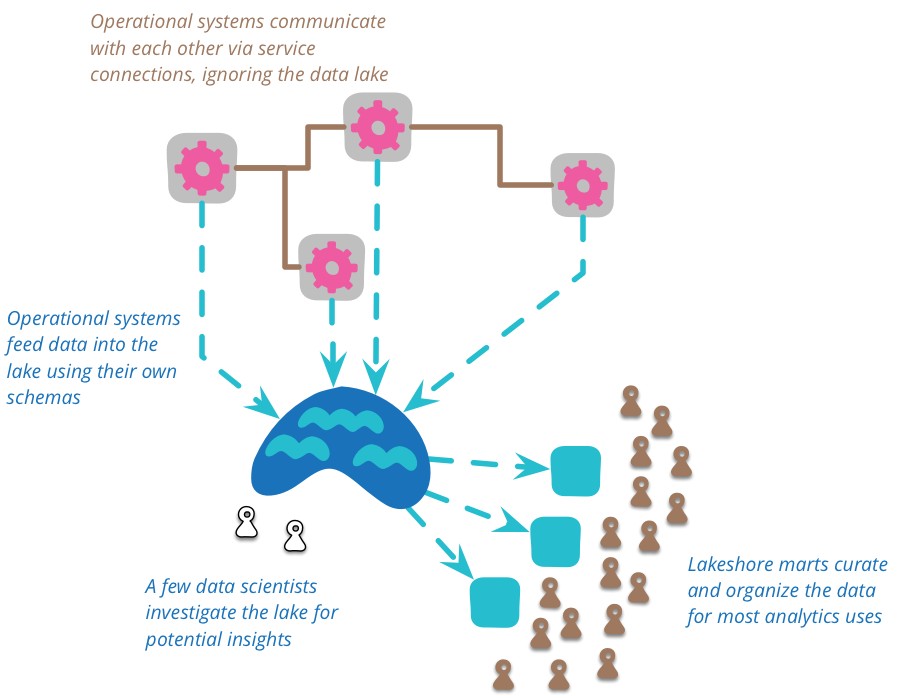
这种原始数据的复杂性意味着有空间可以容纳一些东西,这些东西可以将数据整理成更易于管理的结构(以及减少大量数据)。数据湖不应该被直接访问太多。因为数据是原始的,你需要很多技能才能理解它。在数据湖中工作的人相对较少,当他们发现数据湖中普遍有用的数据视图时,他们可以创建许多数据集市,每个数据集市都为单个边界上下文提供特定的模型。然后,更多下游用户可以将这些湖岸集市视为该上下文的权威来源。
到目前为止,我已经将数据湖描述为跨企业集成数据的单一位置,但我应该提到,这不是最初的意图。这个术语是由 James Dixon 在 2010 年创造的,当时他认为数据湖应该用于单个数据源,多个数据源将形成一个“水花园”。尽管最初的表述如此,但现在普遍的用法是将数据湖视为将许多来源结合在一起。[2]
你应该将数据湖用于分析目的,而不是用于运营系统之间的协作。当运营系统协作时,它们应该通过为此目的而设计的服务进行协作,例如 RESTful HTTP 调用或异步消息传递。数据湖太复杂了,不适合用于运营通信。分析数据湖可能会导致新的运营通信路线,但这些路线应该直接构建,而不是通过数据湖。
重要的是,所有放入数据湖中的数据都应该有明确的来源和时间。每个数据项都应该有明确的跟踪,说明它来自哪个系统以及数据是在何时生成的。因此,数据湖包含一个历史记录。这可能来自将领域事件馈送到数据湖中,这与事件溯源系统自然契合。但它也可能来自定期将当前状态转储到数据湖中的系统——当源系统没有时间能力但你想要对其数据进行时间分析时,这种方法很有价值。其结果是,放入数据湖中的数据是不可变的,一旦陈述的观察结果不能被删除(尽管它可能在以后被反驳),你也应该预期矛盾的观察结果。
数据湖是无模式的,由源系统决定使用什么模式,由消费者决定如何处理由此产生的混乱。此外,源系统可以随意更改其输入数据模式,消费者也必须应对。显然,我们更希望这种更改尽可能地减少干扰,但科学家更喜欢混乱的数据而不是丢失数据。
数据湖将非常庞大,并且大部分存储都围绕着一个大型无模式结构的概念——这就是为什么 Hadoop 和 HDFS 通常是人们用于数据湖的技术。湖岸集市的至关重要任务之一是减少你需要处理的数据量,这样大数据分析就不必处理大量数据。
数据湖对大量原始数据的需求引发了关于隐私和安全的棘手问题。数据最小化原则与数据科学家希望现在捕获所有数据的愿望存在很大冲突。数据湖对黑客来说是一个诱人的目标,他们可能喜欢将精选内容吸收到公共海洋中。将对数据湖的直接访问权限限制在一个小型数据科学团队可能会降低这种威胁,但并不能避免如何让该团队对他们所航行数据的隐私负责的问题。
注释
1: 通常的区别是,数据集市是针对组织中的单个部门,而数据仓库则跨所有部门进行集成。关于数据仓库是否应该是所有数据集市的联合,或者数据集市是否应该是数据仓库中数据的逻辑子集(视图),人们的意见不一致。
2: 在一篇后来的博客文章中,Dixon 强调了湖泊与水花园的区别,但(在评论中)说这是一个微小的变化。对我来说,关键点是湖泊以其自然状态存储大量数据,馈送流的数量并不重要。