
矛盾的观察
2009年3月3日

许多计算机系统都是为了存储数据并将其转化为对人类有用的信息而构建的。当我们这样做时,自然会希望使这些信息保持一致。毕竟,一个对事物持两种想法的计算机系统有什么用呢?
但有时计算机系统应该记录矛盾的数据,并帮助人类处理这些数据。这个问题在我多年前在英国国家医疗服务体系从事医疗保健工作时最先浮出水面。我们正在为医疗保健交付构建一个概念模型——本质上是电子医疗记录的概念模式。
回顾过去,我当然会做很多不同的事情。但有一件事特别珍贵和重要——该模型是我、另一位软件开发人员、两位医生和一位护士共同努力的结果。临床医生理解该模型,并在开发过程中发挥了充分的作用——他们不仅仅是被动的审查者。因此,我认为我们开发的想法在思考临床从业人员希望在电子医疗记录中看到什么方面特别有价值。
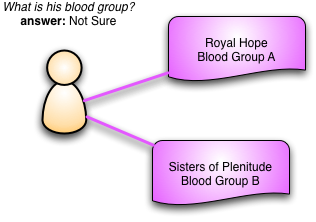
临床医生非常强调需要捕获矛盾信息。我可能有一张来自皇家希望医院的记录,上面写着我的血型是A型,还有一张来自丰裕姐妹医院的记录,上面写着我的血型是B型。这显然是胡说八道,血型不会改变。但这并不意味着我们不能记录这两条数据。在没有进一步调查的情况下,我们不知道哪一个是正确的。即使我们再次测试并确认其中一个,我们也不能简单地丢弃错误的那个,因为它可能成为进一步临床行动的基础。当然,还有很多情况,矛盾并不那么明显。我们可能永远无法确定两条矛盾数据中哪一个是错误的,或者可能会发现随着时间的推移发生的变化,这种变化极不可能,但并非不可能。
处理这个问题的关键不是将我的血型表示为“人”类的一个属性,而是将其表示为一个完整的类——我们称之为“观察”。每个观察都适用于特定患者,但也记录了诸如观察时间、观察者以及观察方式等信息。
我们还发现,观察可以是关于事物的缺失,也可以是关于事物的存在。因此,在某些情况下,可能无法确定我的血型,但可以确定它不是O型血。我们可以将其表示为对O型血缺失的观察。(我不知道这个例子是否可行或合理,但快速想出现实的例子可能很棘手。)观察事物的缺失在诊断过程中通常至关重要。
使用观察改变了我们确定有关患者信息的方式。我们不再简单地询问患者的血型,而是查看患者的所有血型观察结果。如果它们都相同,那么我们只需使用该值。如果它们不同,我们需要深入研究。在许多情况下,观察结果确实会随着时间的推移而发生合理的变化,因此我们可能会查看我体重随时间的推移的所有观察结果,以绘制我的体重变化情况。
虽然我们需要保留矛盾的观察结果,但我们还需要捕获我们是否认为其中一个观察结果是错误的。一些观察结果,例如骨折,会随着时间的推移而变得不真实,但上面的血型示例更有可能是错误的。在错误的情况下,我们有“拒绝”(或反驳)一个观察结果的另一个观察结果的概念。因此,我们可能在阿尔比恩医院进行进一步的测试,发现我的血型是A型,然后这个观察结果将拒绝丰裕姐妹医院的观察结果。拒绝一个观察结果意味着我们认为它从未真实存在过。我们永远不会删除旧的观察结果,而是将其标记为拒绝,并将其链接到阿尔比恩医院的观察结果。
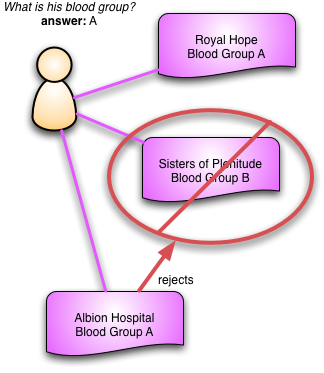
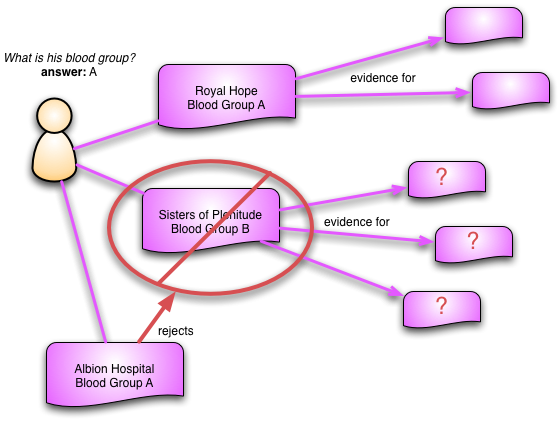
信息的一个重要属性是它被用来指导行为。被拒绝的观察结果可能已被用作进一步观察的证据或为干预提供理由。在记录中保留这些链接至关重要,因为一旦观察结果被拒绝,我们就可以跟踪这些链接来调查结果。如果我们刚刚拒绝的观察结果是另一个观察结果的证据的关键部分,那么应该对其进行质疑,并可能将其也拒绝。因此,观察结果形成了一个证据网络,我们可以随着对患者的了解而对其进行检查。
当然,大多数时候我们不会使用像这样的复杂方案。我们主要在假设一致的世界中进行编程。但有时我们必须放弃这种舒适的假设。当这种情况发生时,显式观察是一个有用的工具。
(如果您对此感兴趣,请参阅《分析模式》一书的第 3 章。我相信如果我现在重写它,我会写得更好,但核心概念似乎仍然很有效。我还想感谢我的同事参与这项工作:汤姆·凯恩斯、安妮·凯西、马克·瑟兹和哈齐姆·蒂米米)