
不要比较平均值
仅使用平均值来比较数字组会隐藏许多见解
在商务会议中,通常通过比较平均值来比较数字组。但这样做往往会隐藏这些组中数字分布的重要信息。有一些数据可视化方法可以揭示这些信息。这些方法包括条形图、直方图、密度图、箱线图和小提琴图。这些方法很容易使用免费软件生成,适用于从十几个到数千个的组。
2020 年 9 月 24 日

想象一下,您是一位高管,您被要求决定给哪位销售主管颁发大奖/晋升/奖金。您的公司是一家只看重收入的“弱肉强食”的资本主义公司,因此您决策的关键因素是今年谁的收入增长最多。(鉴于现在是 2020 年,也许我们卖的是口罩。)
以下是至关重要的数字。
| 姓名 | 平均收入增长 (%) |
|---|---|
| 爱丽丝 | 5.0 |
| 鲍勃 | 7.9 |
| 克拉拉 | 5.0 |
以及一张彩色图表
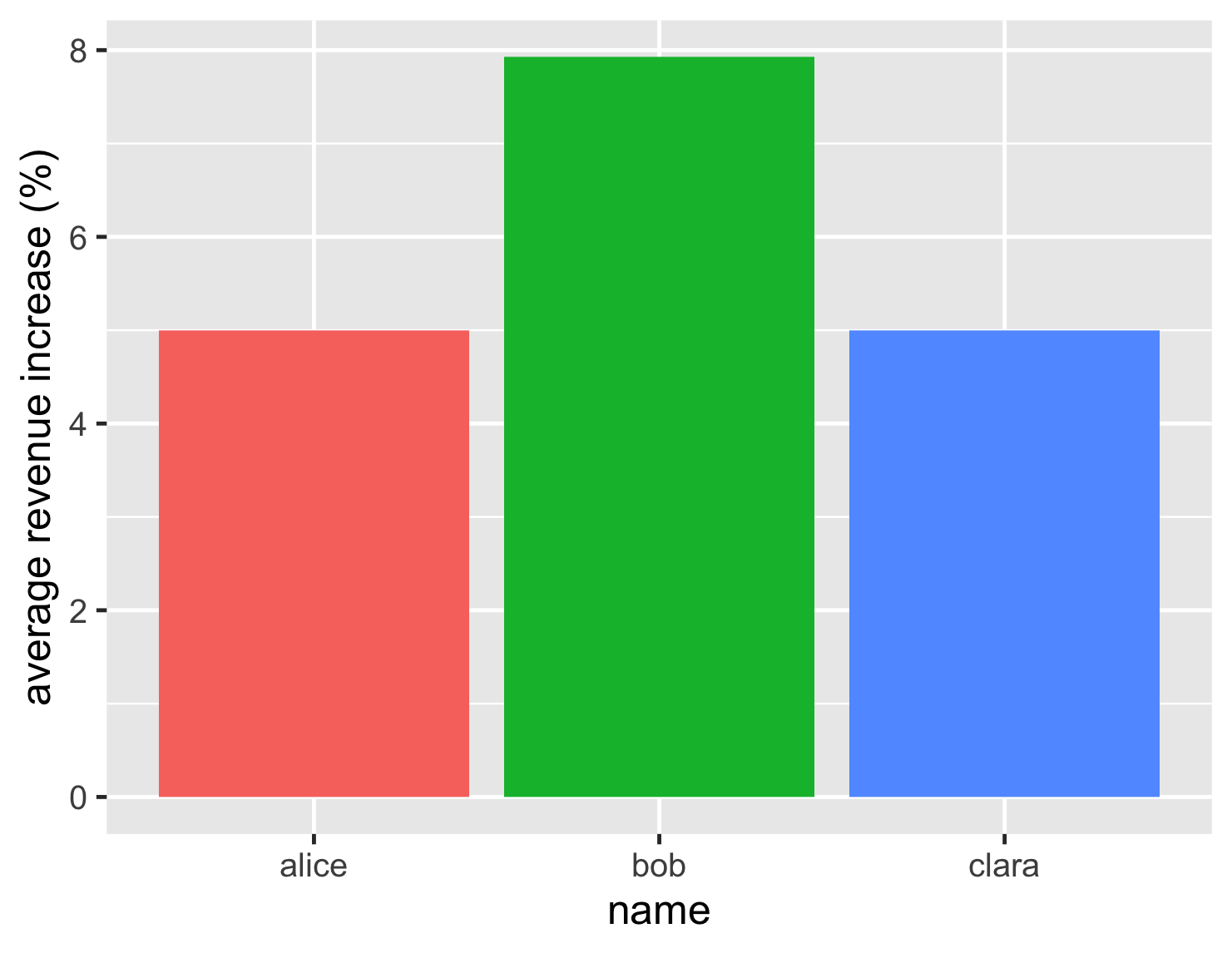
基于此,决策看起来很简单。鲍勃的收入增长率略低于 8%,明显高于竞争对手的 5%。
但让我们深入挖掘,看看我们每个销售人员的个人账户。
| 姓名 | 账户收入增长 (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 爱丽丝 | -1.0 | 2.0 | 1.0 | -3.0 | -1.0 | 10.0 | 13.0 | 8.0 | 11.0 | 10.0 |
| 鲍勃 | -0.5 | -2.5 | -6.0 | -1.5 | -2.0 | -1.8 | -2.3 | 80.0 | ||
| 克拉拉 | 3.0 | 7.0 | 4.5 | 5.5 | 4.8 | 5.0 | 5.2 | 4.0 | 6.0 | 5.0 |
这些账户级数据讲述了一个不同的故事。鲍勃的高绩效是由于一个账户产生了高达 80% 的收入增长。他所有其他账户都缩水了。由于鲍勃的绩效仅基于一个账户,他真的是最适合获得奖金的销售人员吗?
鲍勃的故事是比较任何数据点组时遇到的最大问题之一的典型例子。通常的平均值,技术上称为平均值,很容易受到单个异常值的影响,从而影响整个值。请记住,一旦比尔·盖茨进入房间,一百个无家可归者的平均净资产就是 10 亿美元。
详细的账户数据揭示了另一个差异。尽管爱丽丝和克拉拉的平均值相同,但他们的账户数据讲述了两个截然不同的故事。爱丽丝要么非常成功(约 10%),要么平庸(约 2%),而克拉拉始终保持着中等程度的成功(约 5%)。仅仅查看平均值会隐藏这种重要的差异。
到目前为止,任何学习过统计学或数据可视化的人都会对我这个“显而易见”的观点翻白眼。但这种知识并没有传达给企业界的人。我在商业演示文稿中经常看到比较平均值的条形图。因此,我决定写这篇文章,展示一系列可视化方法,您可以使用这些方法来探索此类信息,从而获得平均值无法提供的见解。通过这样做,我希望说服一些人停止只使用平均值,并在看到其他人这样做时质疑平均值。毕竟,除非您知道如何正确地检查这些数据,否则收集成为数据驱动型企业所需的数据毫无意义。
条形图显示所有单个数字
因此,规则是,如果您不知道数据的实际分布情况,就不要比较平均值。如何才能获得数据的清晰图像?
我将从上面的案例开始,当时我们没有太多数据点。通常,在这种情况下,最好的方法是条形图,它将显示不同人群中的每个数据点。
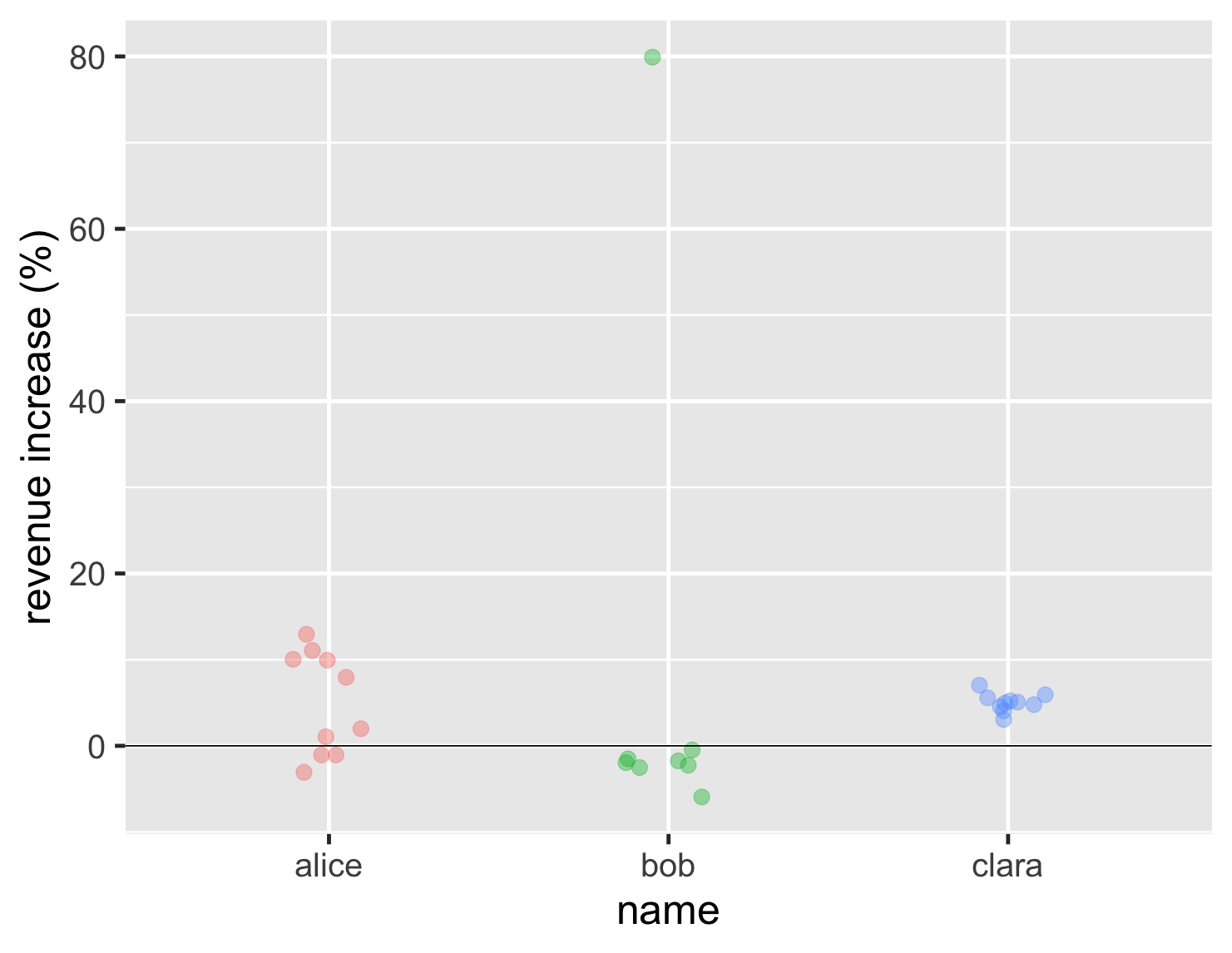
显示代码
ggplot(sales, aes(name, d_revenue, color=name)) + geom_jitter(width=0.15, alpha = 0.4, size=5, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
通过这张图表,我们现在可以清楚地看到鲍勃的唯一高点,他的大多数结果与爱丽丝的最差结果相似,而克拉拉则更加一致。这比之前的条形图告诉我们更多信息,但实际上并不难理解。
然后您可能会问,如何绘制这张漂亮的条形图?大多数想要绘制一些快速图表的人使用 Excel 或其他电子表格。我不知道在普通电子表格中绘制条形图有多容易,因为我不是电子表格用户。根据我在管理演示文稿中看到的内容,这可能是不可能的,因为我几乎从未见过一个。对于我的绘图,我使用 R,这是一个功能强大的统计软件包,由熟悉“肯德尔秩相关系数”和“曼-惠特尼 U 检验”等短语的人使用。然而,尽管拥有如此强大的武器库,但使用 R 系统进行简单的數據操作和图表绘制却相当容易。它由学者作为开源软件开发,因此您可以下载并使用它,而无需担心许可费用和采购官僚主义。对于开源世界来说,它拥有出色的文档和教程,可以帮助您学习如何使用它。(如果您是 Pythonista,也有许多优秀的 Python 库可以完成所有这些操作,尽管我还没有深入研究该领域。)如果您对 R 感兴趣,我在附录中有一个关于如何学习 R 的总结。
如果您对我是如何生成此处显示的各种图表的感兴趣,我在每个图表之后都包含了一个“显示代码”披露,其中显示了绘制图表的命令。使用的销售数据框有两列:name 和 d_revenue。
如果我们要考虑更多的数据点怎么办?想象一下,我们的三人组现在变得更加重要,每个人都处理数百个账户。他们的分布仍然显示出相同的基本特征,我们可以从新的条形图中看到这一点。
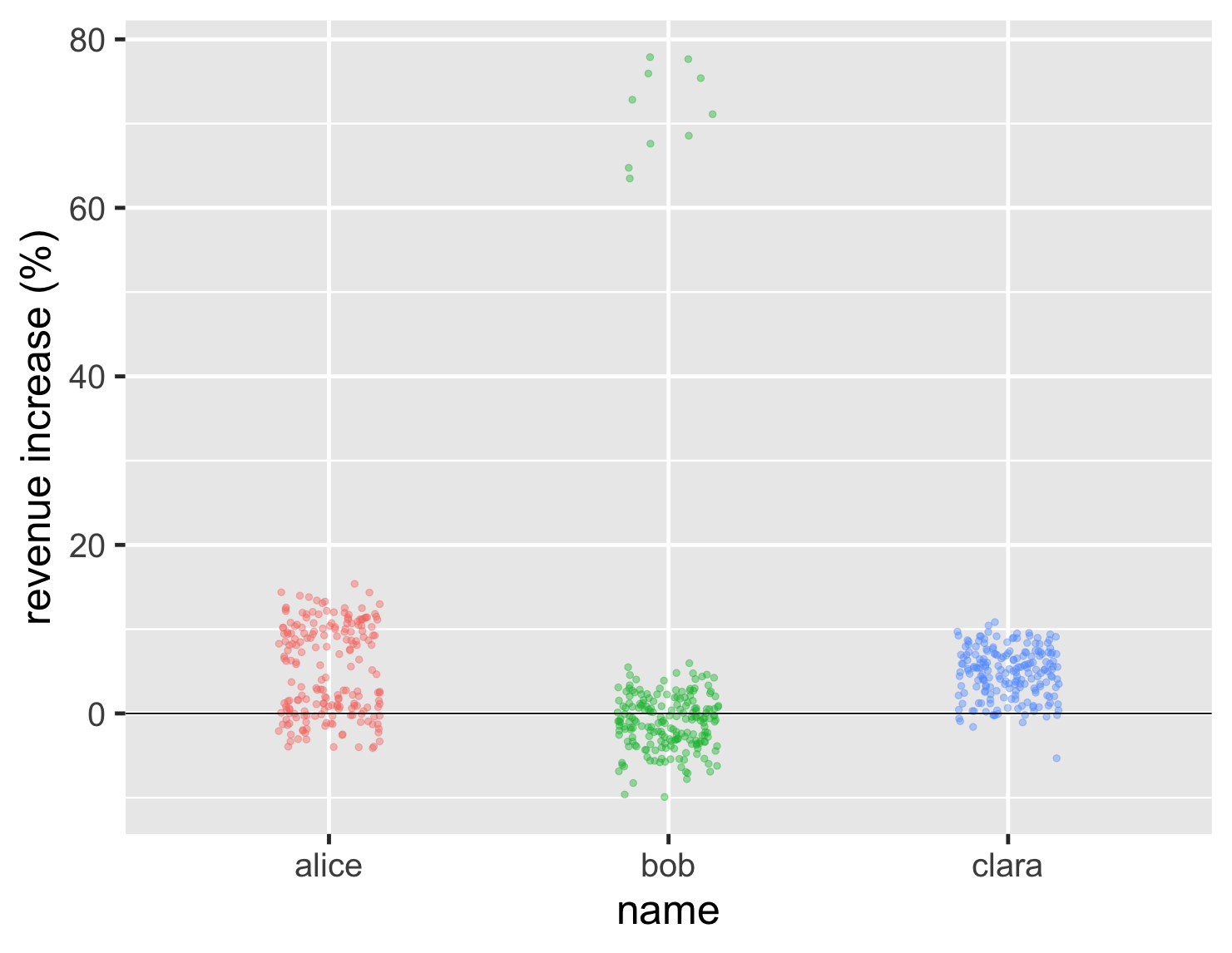
显示代码
ggplot(large_sales, aes(name, value, color=name)) + geom_jitter(width=0.15, alpha = 0.4, size=2, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
然而,条形图的一个问题是,我们无法看到平均值。因此,我们无法判断鲍勃的高值是否足以弥补他总体较低的点。我可以通过在图表上绘制平均点来解决这个问题,在本例中,它是一个黑色菱形。
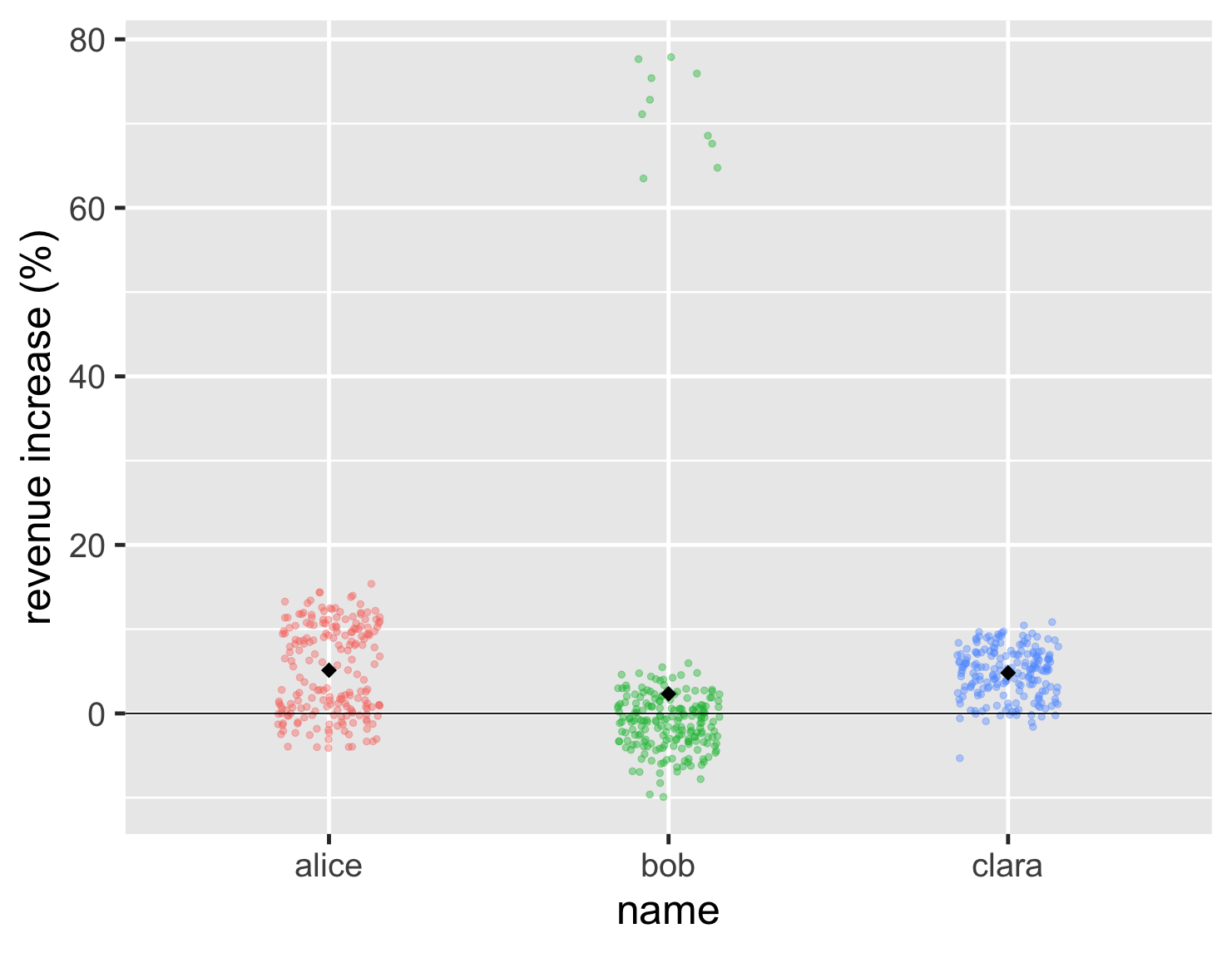
显示代码
ggplot(large_sales, aes(name, value, color=name)) + geom_jitter(width=0.15, alpha = 0.4, size=2, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + stat_summary(fun = "mean", size = 5, geom = "point", shape=18, color = 'black') + theme_grey(base_size=30)
因此,在这种情况下,鲍勃的平均值略低于其他两个。
这表明,即使我经常贬低那些使用平均值来比较组的人,但我并不认为平均值毫无用处。我鄙视那些只使用平均值的人,或者在没有检查整体分布的情况下使用平均值的人。某种平均值通常是比较的有用元素,但大多数情况下,中位数实际上是更好的中心点,因为它对像鲍勃这样的巨大异常值更具抵抗力。每当您看到“平均值”时,您都应该考虑哪一个更好:中位数还是平均值?
中位数之所以如此少用,通常是因为我们的工具没有鼓励我们使用它。SQL 是占主导地位的数据库查询语言,它带有内置的 AVG 函数,用于计算平均值。但是,如果您想要中位数,您通常只能搜索一些相当难看的算法,除非您的数据库能够加载扩展函数。[1] 如果有一天我成为最高领导人,我将颁布法令,任何平台都不得拥有平均值函数,除非它们也提供中位数。
使用直方图查看分布的形状
虽然使用条形图是立即了解数据外观的好方法,但其他图表可以帮助我们以不同的方式进行比较。我注意到的一件事是,许多人想要使用“一张图表”来显示特定数据集。但每种图表都阐明了数据集的不同特征,明智的做法是使用多个图表来了解数据可能告诉我们的信息。当然,这在我探索数据、试图了解数据告诉我的信息时是正确的。但即使在传达数据时,我也会使用多个图表,以便我的读者能够看到数据所表达的不同方面。
直方图是查看分布的经典方法。以下是大型数据集的直方图。
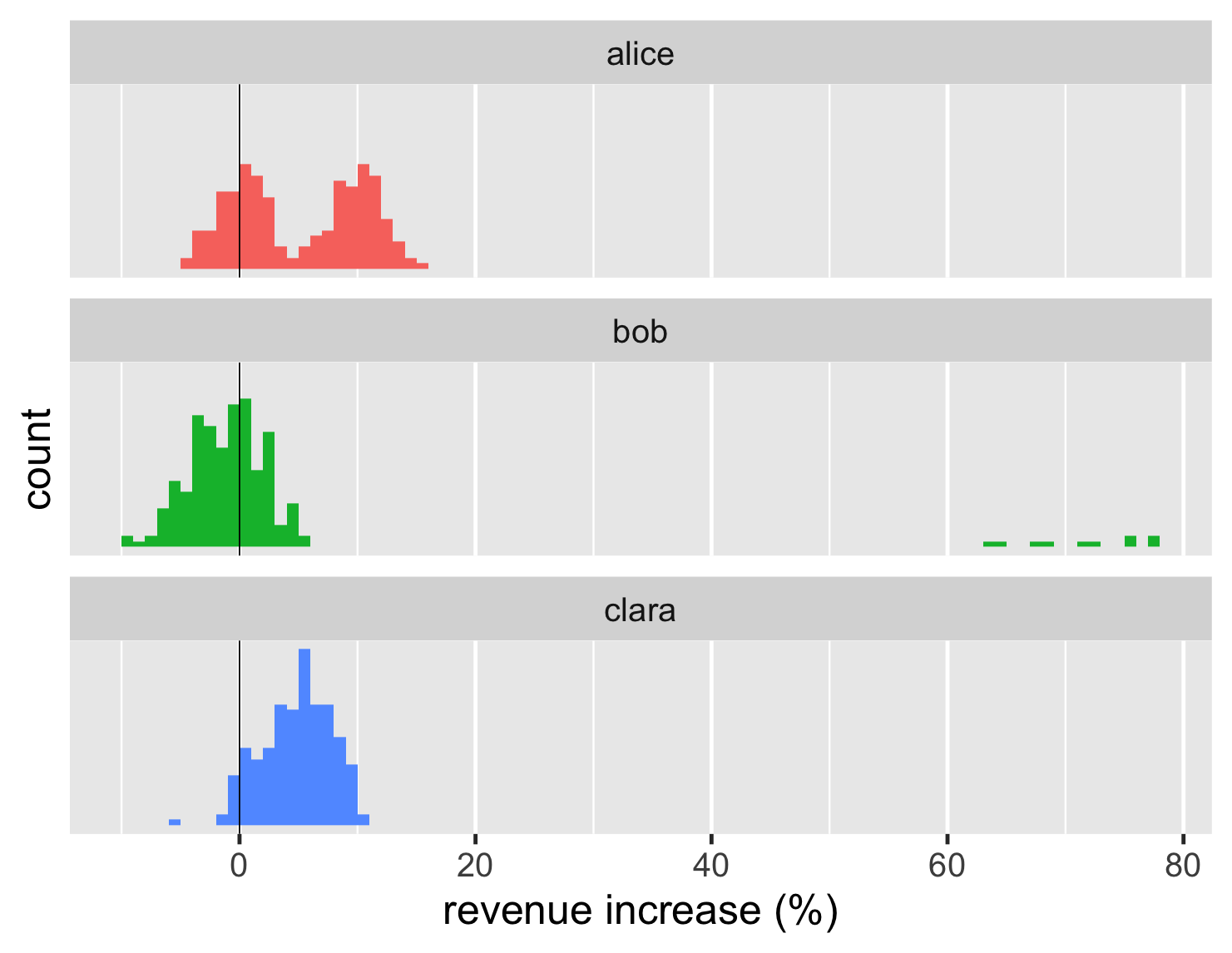
显示代码
ggplot(large_sales, aes(value, fill=name)) + geom_histogram(binwidth = 1, boundary=0, show.legend=FALSE) + xlab(label = "revenue increase (%)") + scale_y_continuous(breaks = c(50,100)) + geom_vline(xintercept = 0) + theme_grey(base_size=30) + facet_wrap(~ name,ncol=1)
直方图非常适合显示单个分布的形状。因此,很容易看出爱丽丝的交易集中在两个不同的块中,而克拉拉的交易集中在一个块中。这些形状从条形图中也多少可以看出,但直方图更清楚地显示了形状。
直方图只显示一个组,但在这里我同时显示了几个组以进行比较。R 有一个专门用于此的功能,它称为分面图。这些“小倍数”(爱德华·塔夫特创造的术语)对于比较非常有用。幸运的是,R 使它们易于绘制。
另一种可视化分布形状的方法是密度图,我认为它类似于直方图的平滑曲线。
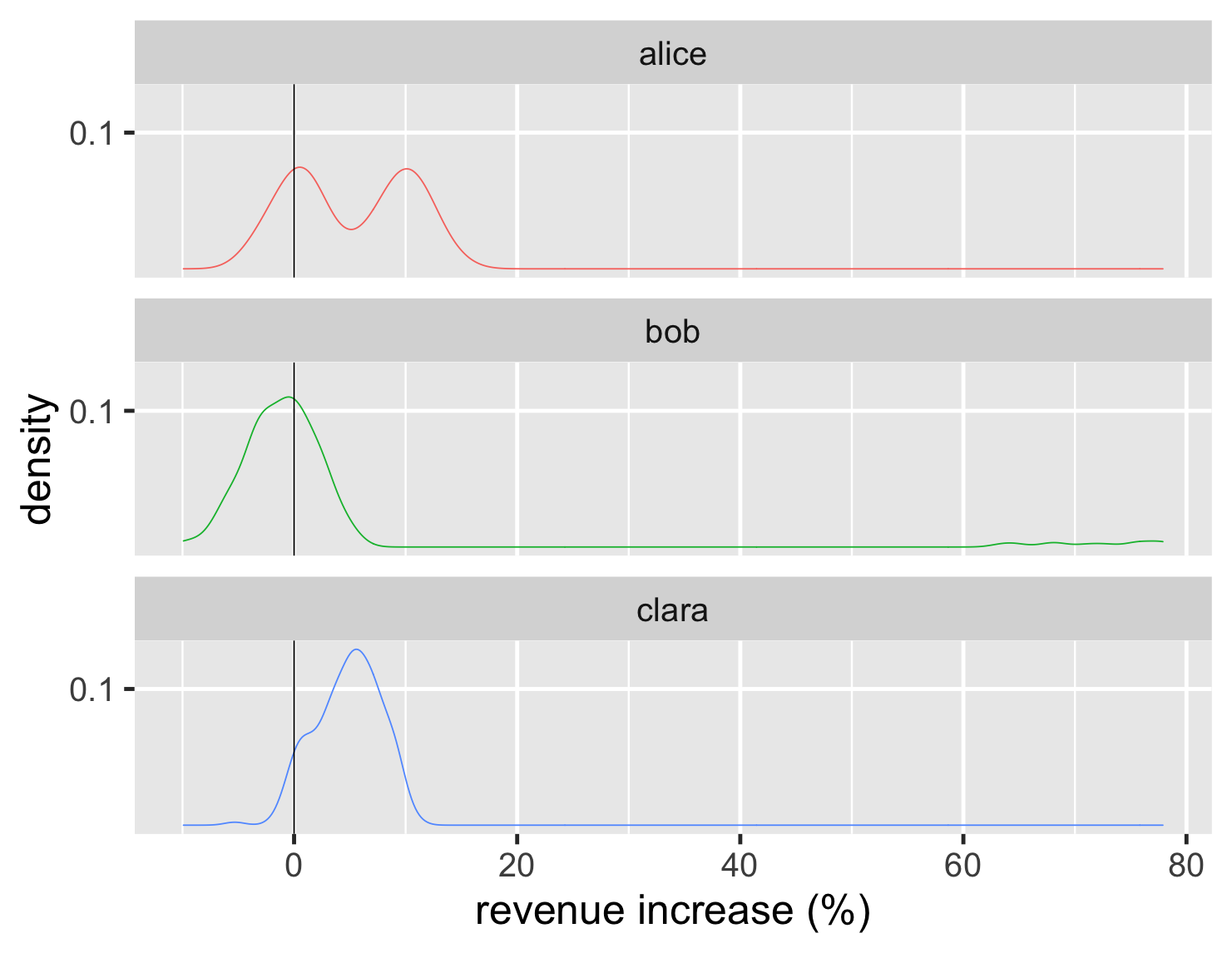
显示代码
ggplot(large_sales, aes(value, color=name)) + geom_density(show.legend=FALSE) + geom_vline(xintercept = 0) + xlab(label = "revenue increase (%)") + scale_y_continuous(breaks = c(0.1)) + theme_grey(base_size=30) + facet_wrap(~ name,ncol=1)
y 轴上的密度刻度对我来说意义不大,因此我倾向于从图中删除该刻度——毕竟,这些图的关键元素是分布的形状。此外,由于密度图很容易渲染为线条,因此我可以将它们全部绘制在同一张图表上。
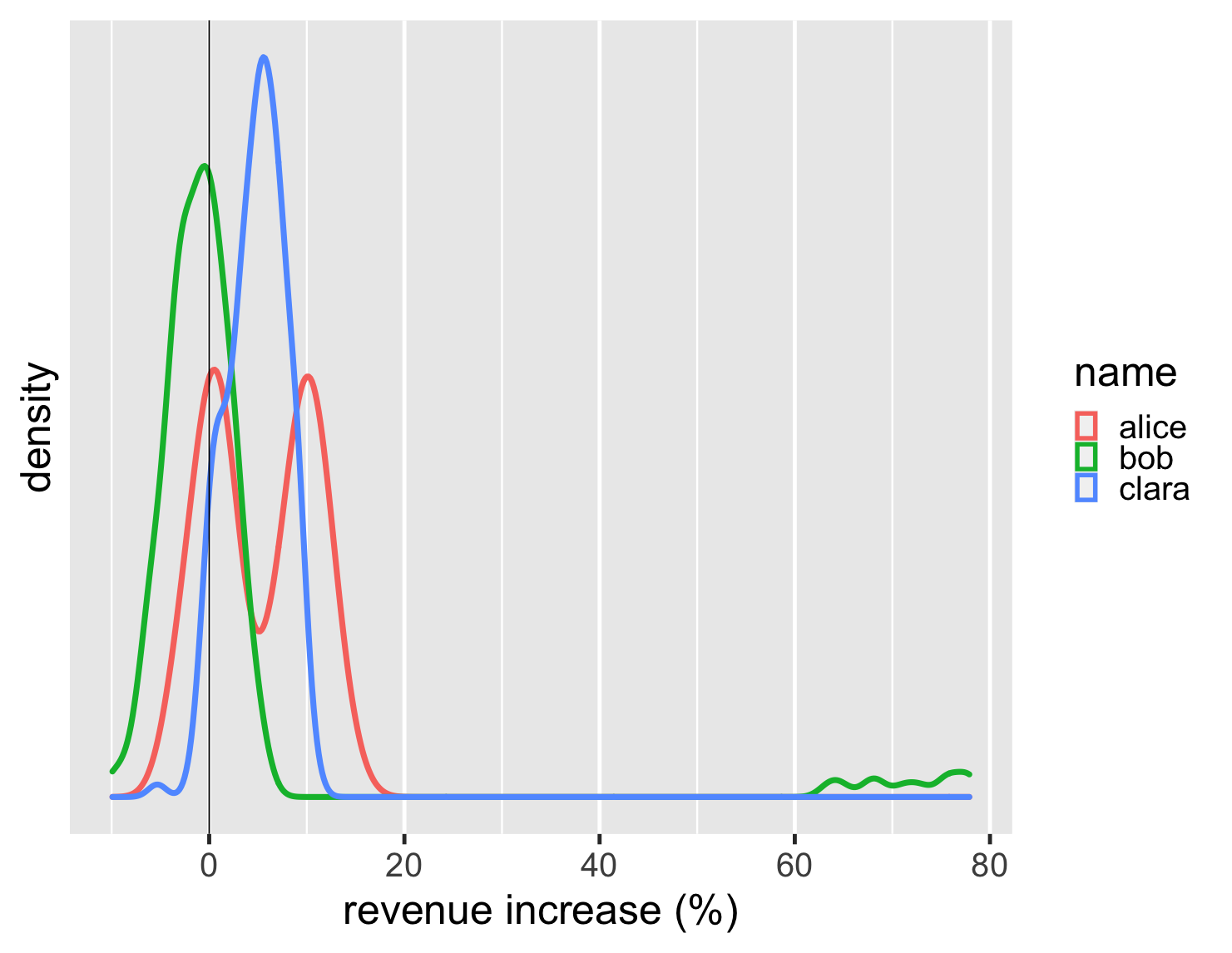
显示代码
ggplot(large_sales, aes(value, color=name)) + geom_density(size=2) + scale_y_continuous(breaks = NULL) + xlab(label = "revenue increase (%)") + geom_vline(xintercept = 0) + theme_grey(base_size=30)
直方图和密度图在数据点更多时更有效,在数据点很少时(如第一个示例)则不太有用。当只有几个值时,例如评论网站上的 5 星评级,计数的条形图很有用。几年前,亚马逊为其评论添加了这样的图表,该图表显示了分布以及平均分数。
箱线图适用于许多比较
直方图和密度图是比较不同分布形状的好方法,但一旦我超过几个图表,它们就难以比较。了解分布中常用的范围和位置也很有用。这就是箱线图派上用场的地方。
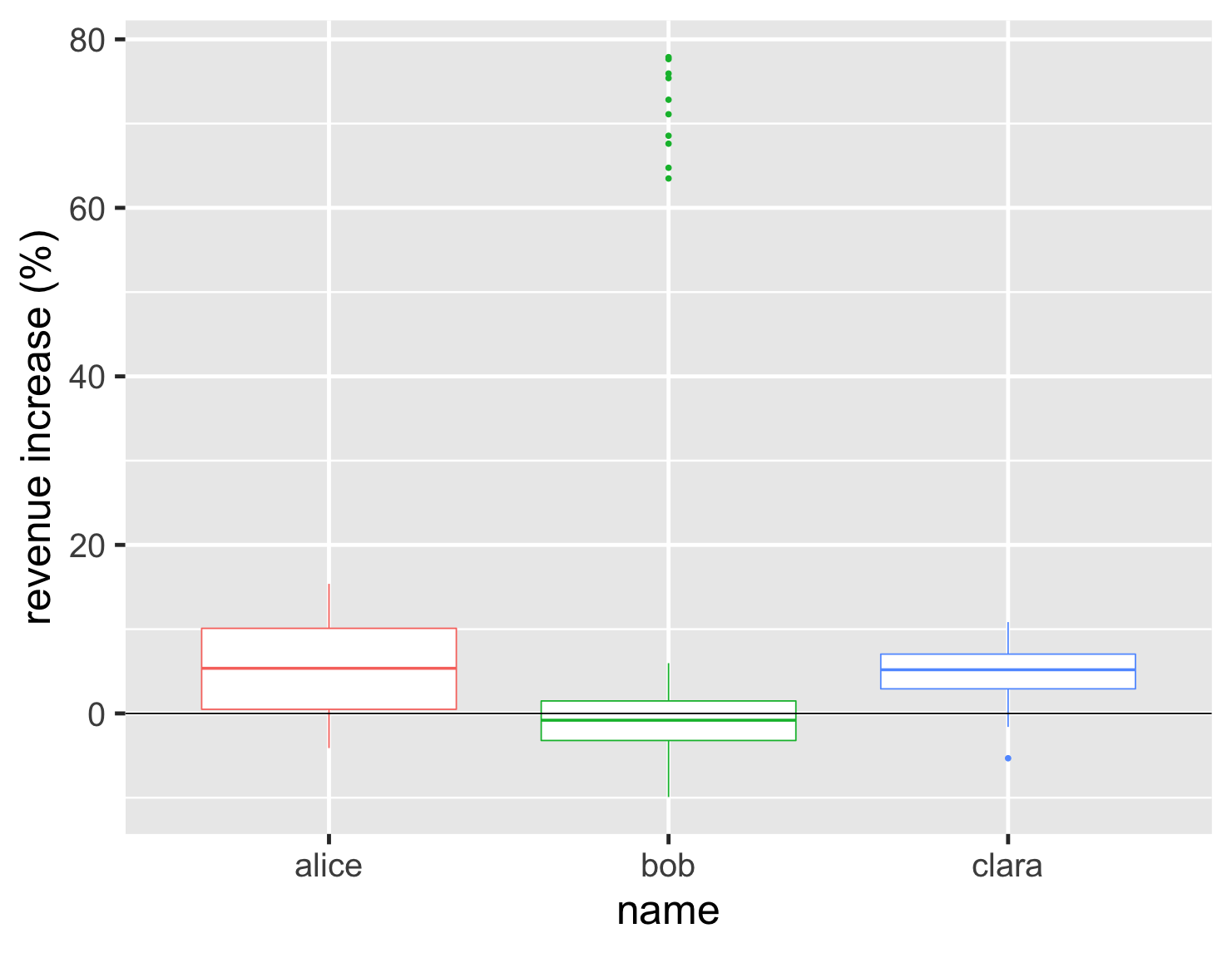
显示代码
ggplot(large_sales, aes(name, value, color=name)) + geom_boxplot(show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
箱线图将我们的注意力集中在数据的中间范围,因此一半的数据点位于箱体内。查看图表,我们可以看到鲍勃超过一半的账户都缩水了,并且他的上四分位数低于克拉拉的下四分位数。我们还看到他的一组热门账户位于图表的上端。
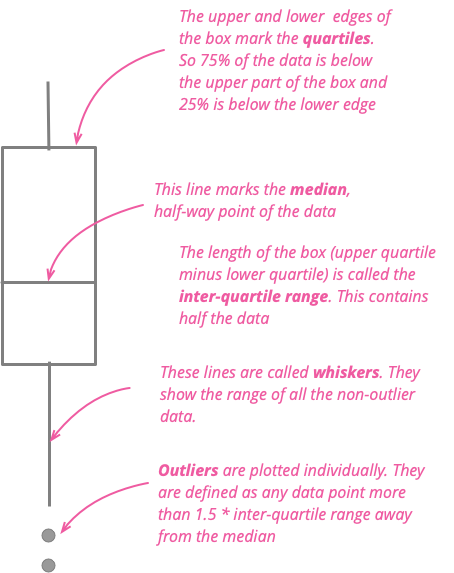
箱线图在比较几十个项目时效果很好,提供了对基础数据外观的良好总结。以下是一个示例。我于 1983 年搬到伦敦,十年后搬到波士顿。作为英国人,我自然会想到这两个城市的天气比较。因此,这里有一张图表,显示了自 1983 年以来每个月的每日最高气温比较。
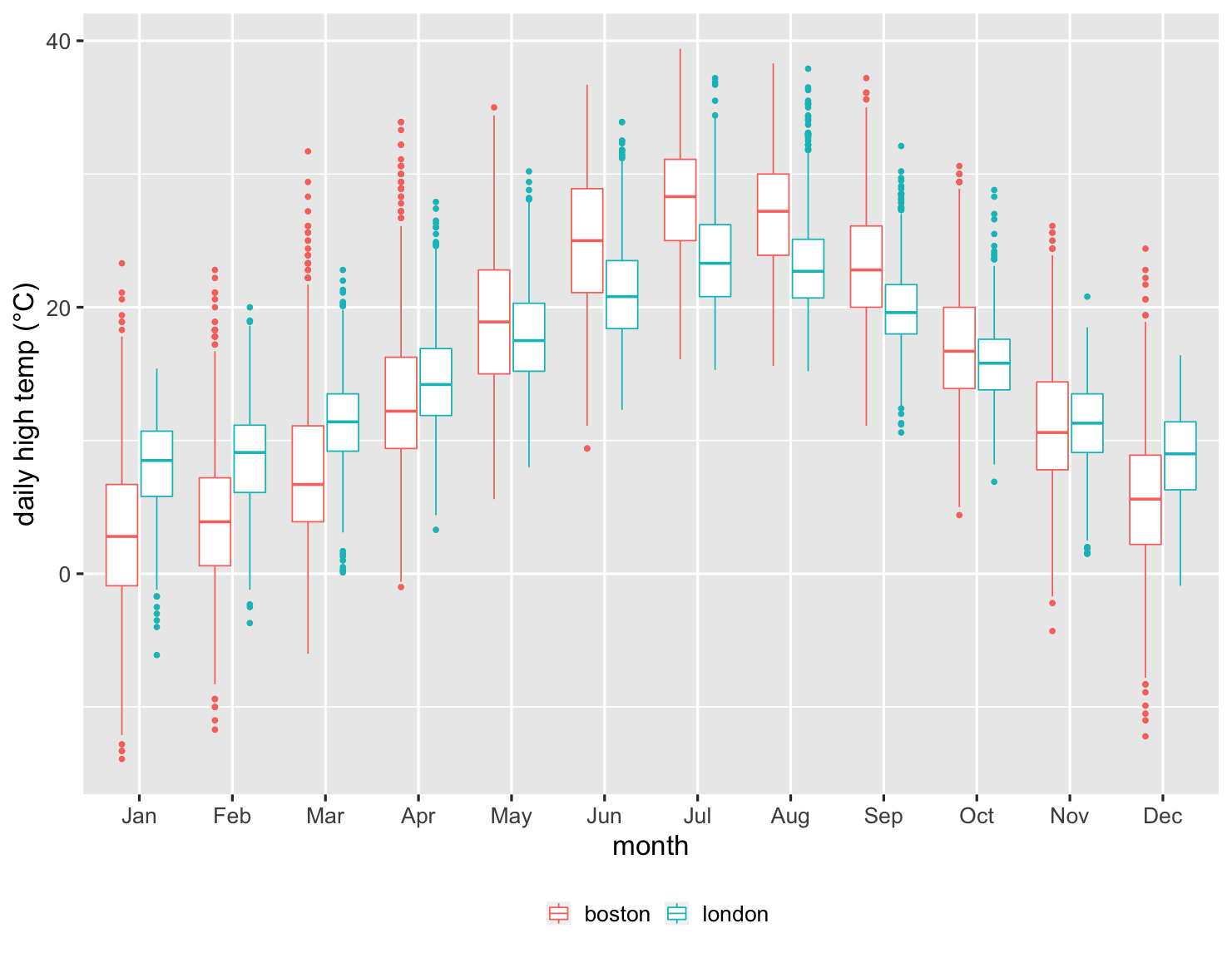
显示代码
ggplot(temps, aes(month, high_temp, color=factor(city))) + ylab(label = "daily high temp (°C)") + theme_grey(base_size=20) + scale_x_discrete(labels=month.abb) + labs(color = NULL) + theme(legend.position = "bottom") + geom_boxplot()
这是一张令人印象深刻的图表,因为它总结了超过 27,000 个数据点。我可以看到,伦敦冬季的中位气温比波士顿高,但夏季则更低。但我也可以看到每个月变化的比较。我可以看到,在超过四分之一的时间里,波士顿 1 月份的气温不会超过冰点。波士顿的上四分位数几乎超过了伦敦的下四分位数,这清楚地表明我的新家有多冷。但我也可以看到,波士顿 1 月份有时会比伦敦在那个冬季月份的任何时候都温暖。
然而,箱线图有一个缺点,即我们无法看到数据的精确形状,只能看到常用的聚合点。在比较爱丽丝和克拉拉时,这可能是一个问题,因为我们没有像直方图和密度图那样看到爱丽丝分布中的双峰。
有几种方法可以解决这个问题。一种方法是,我可以轻松地将箱线图与条形图结合起来。
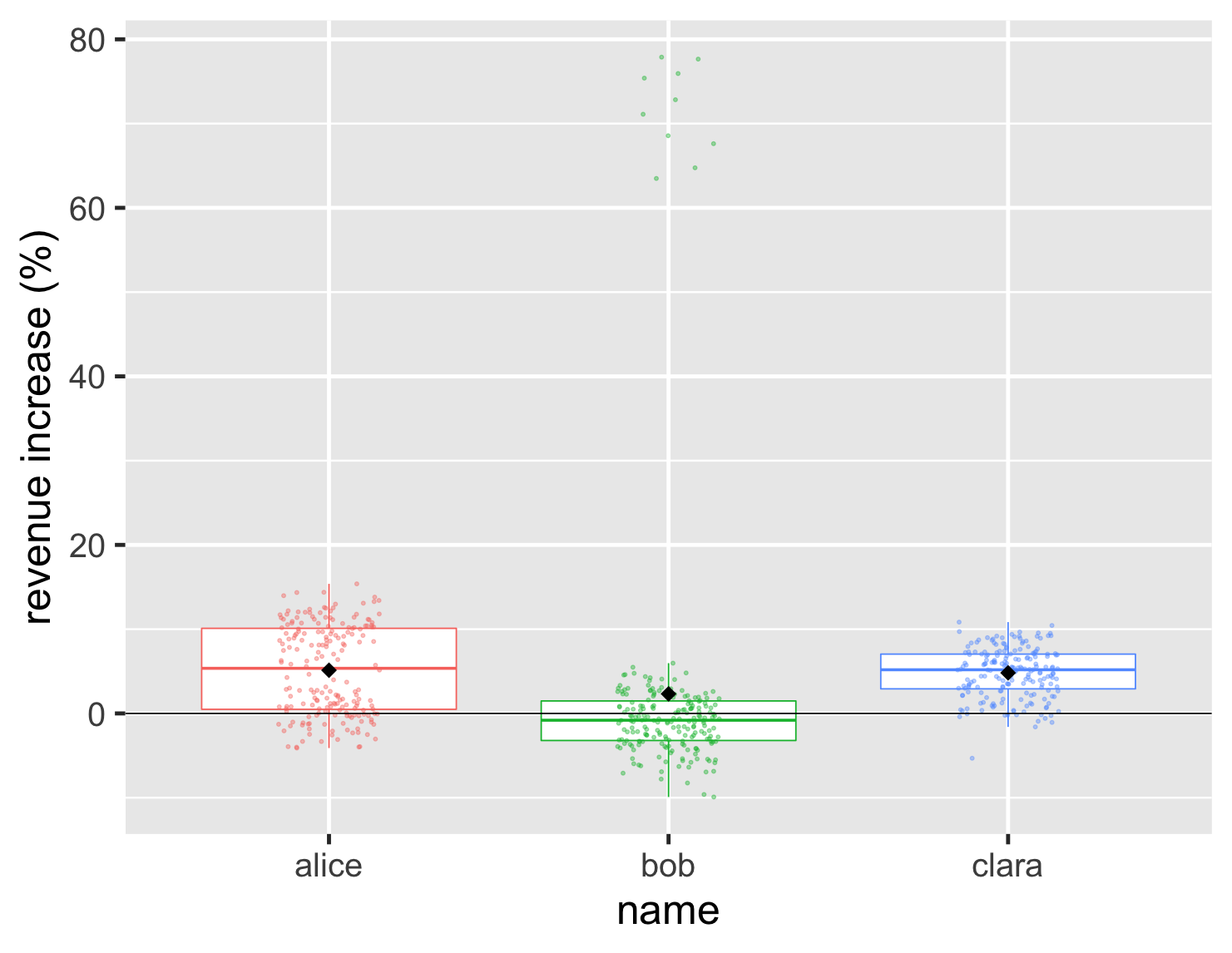
显示代码
ggplot(large_sales, aes(name, value, color=name)) + geom_boxplot(show.legend=FALSE, outlier.shape = NA) + geom_jitter(width=0.15, alpha = 0.4, size=1, show.legend=FALSE) + ylab(label = "revenue increase (%)") + stat_summary(fun = "mean", size = 5, geom = "point", shape=18, color = 'black') + geom_hline(yintercept = 0) + theme_grey(base_size=30)
这使我能够同时显示基础数据和重要的聚合值。在这个图中,我还包括了之前使用的黑色菱形,以显示平均值的位置。这是一种突出显示像鲍勃这样的案例的好方法,在这些案例中,平均值和中位数有很大差异。
另一种方法是小提琴图,它在箱体的两侧绘制密度图。
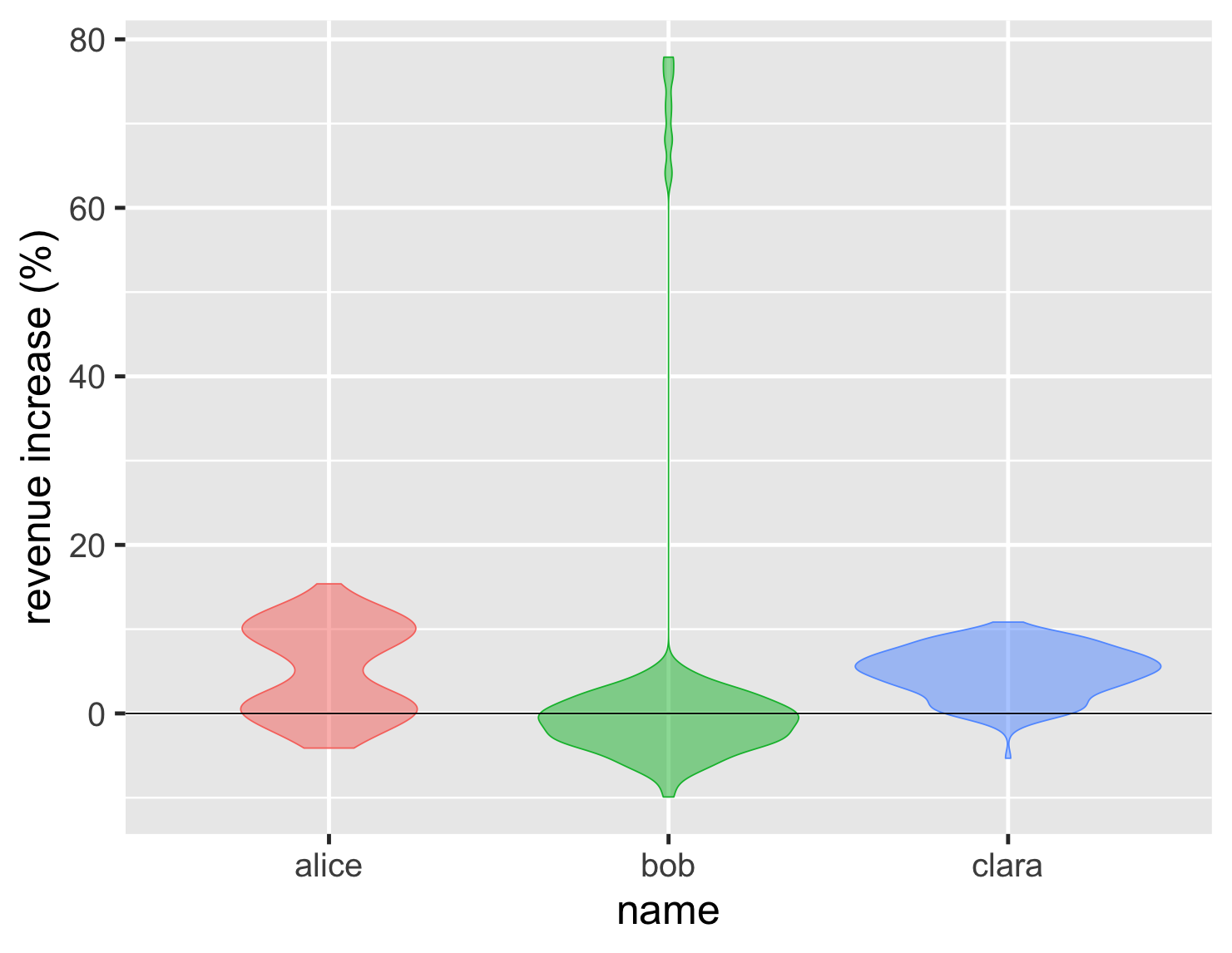
显示代码
ggplot(large_sales, aes(name, value, color=name, fill=name)) + geom_violin(show.legend=FALSE, alpha = 0.5) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
这样做的好处是可以清楚地显示分布的形状,因此爱丽丝表现的双峰非常突出。与密度图一样,它们只有在点数较多时才会变得有效。对于销售示例,我认为我更愿意在框中看到点,但如果我们有 27,000 个温度测量值,权衡就会改变。
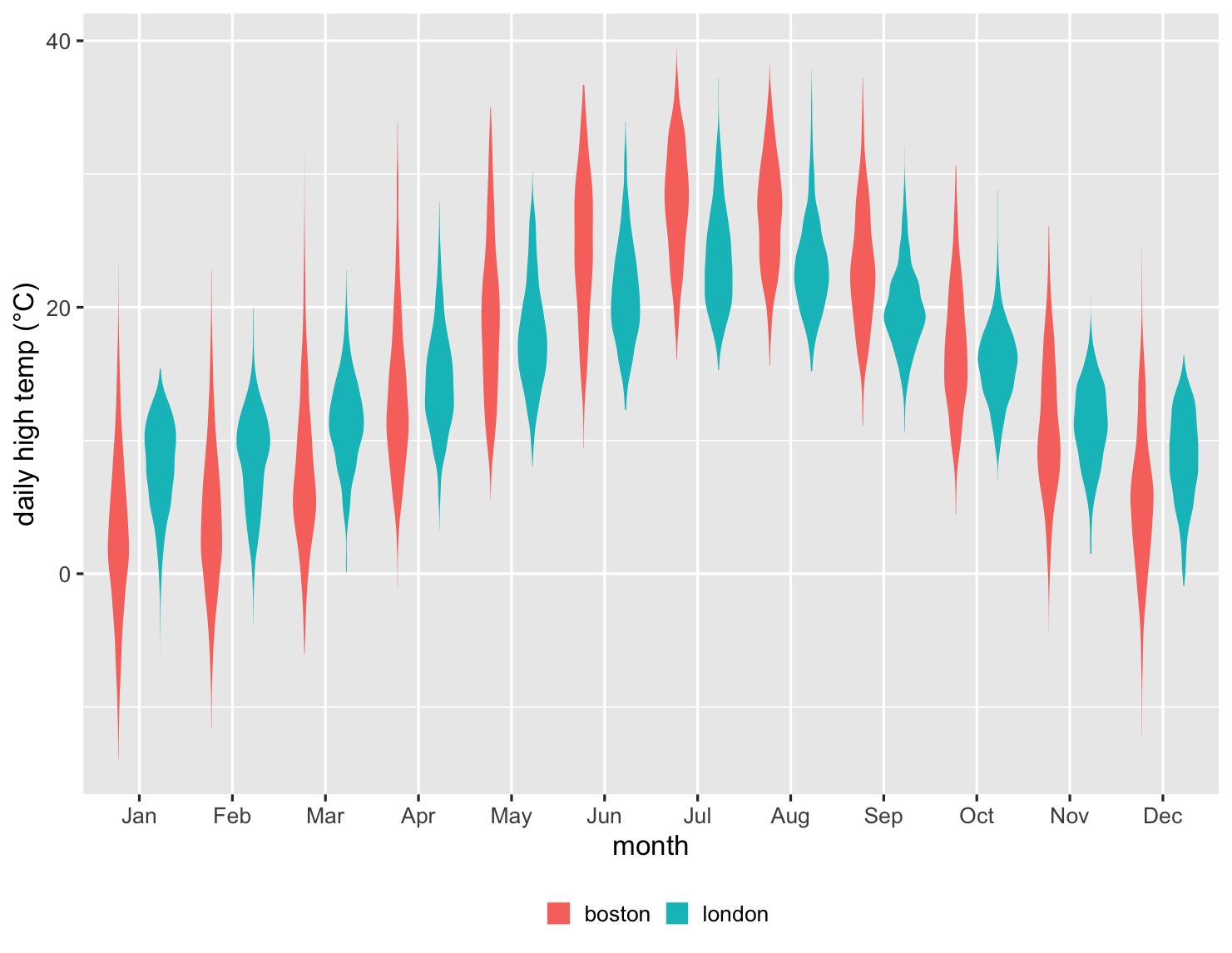
显示代码
ggplot(temps, aes(month, high_temp, fill=factor(city))) + ylab(label = "daily high temp (°C)") + theme_grey(base_size=20) + labs(fill = NULL) + scale_x_discrete(labels=month.abb) + theme(legend.position = "bottom") + geom_violin(color = NA)
在这里我们可以看到,小提琴图在显示每个月的數據形状方面做得很好。但总的来说,我发现此数据的箱线图更有用。通过使用数据中的重要标志(例如中位数和四分位数)进行比较通常更容易。这是多个图发挥作用的另一个例子,至少在探索数据时是这样。箱线图通常是最有用的,但至少值得看一下小提琴图,看看它是否揭示了一些奇怪的形状。
总结
- 除非你了解潜在的分布,否则不要仅仅使用平均值来比较组。
- 如果有人向你展示仅包含平均值的数据,请询问:“分布是什么样的?”
- 如果你正在探索组之间的比较方式,请使用多个不同的图来探索它们的形状以及如何最好地比较它们。
- 如果要求提供“平均值”,请检查均值或中位数哪个更好。
- 在展示组之间的差异时,至少要考虑我在这里展示的图表,不要害怕使用多个图表,并选择最能说明重要特征的图表。
- 最重要的是:**绘制分布!**
致谢
Adriano Domeniconi、David Colls、David Johnston、James Gregory、John Kordyback、Julie Woods-Moss、Kevin Yeung、Mackenzie Kordyback、Marco Valtas、Ned Letcher、Pat Sarnacke、Saravanakumar Saminathan、Tiago Griffo 和 Xiao Guo 在内部邮件列表中对本文草稿发表了评论。
进一步阅读
Cédric Scherer 介绍了雨云图的方法,该方法将箱线图、小提琴图和条形图的特征组合在一个紧凑的符号中。他的教程基于Allen 等人的一篇论文。
我学习 R 的经历
我第一次接触 R 是大约 15 年前,当时我和一位同事一起做了一些统计问题的工作。虽然我在学校学了很多数学,但我却回避了统计学。虽然我对它提供的见解非常感兴趣,但我被它所需的计算量吓倒了。我有一个奇怪的特征,我擅长数学,但不擅长算术。
我喜欢 R,尤其是因为它支持其他地方几乎没有的图表(而且我一直不太喜欢使用电子表格)。但 R 是一个平台,其社区足够危险,以至于让 JavaScript 看起来很安全。然而,近年来,由于 Hadley Whickham(R 的奥斯曼男爵)的工作,使用 R 变得容易得多。他领导了“tidyverse”的开发:一系列使 R 非常易于使用的库。本文中的所有图都使用他的 ggplot2 库。
近年来,我越来越多地使用 R 来创建任何使用定量数据的报告,将 R 用于计算和绘图。在这里,tidyverse dplyr 库发挥了重要作用。从本质上讲,它允许我在表格数据上形成操作管道。在某种程度上,它是在表格行上的集合管道,具有用于映射和过滤行的函数。然后它通过支持表格操作(如联接和透视)进一步发展。
如果编写如此出色的软件还不够,他还合著了一本学习使用 R 的优秀书籍:R for Data Science。我发现这是一本关于数据分析的优秀教程,是 tidyverse 的入门介绍,也是我经常参考的书籍。如果你对操作和可视化数据感兴趣,并且喜欢亲自动手使用一个强大的工具来完成这项工作,那么这本书是一个很好的选择。R 社区在这本书和其他帮助解释数据科学概念和工具的书籍方面做得很好。tidyverse 社区还构建了一个一流的开源编辑和开发环境,称为R Studio。我再说一句,在使用 R 时,我通常使用它而不是 Emacs。
R 当然并不完美。作为一种编程语言,它非常古怪,我不敢偏离简单的 dplyr/ggplot2 管道的林荫大道。如果我想在数据丰富的环境中进行严肃的编程,我会认真考虑切换到 Python。但对于我所做的数据工作类型,R 的 tidyverse 已经证明是一个很好的工具。
制作好的条形图的技巧
当我使用条形图时,我经常使用一些有用的技巧。通常,你会有具有相似甚至相同值的數據点。如果我天真地绘制它们,我最终会得到这样的条形图。
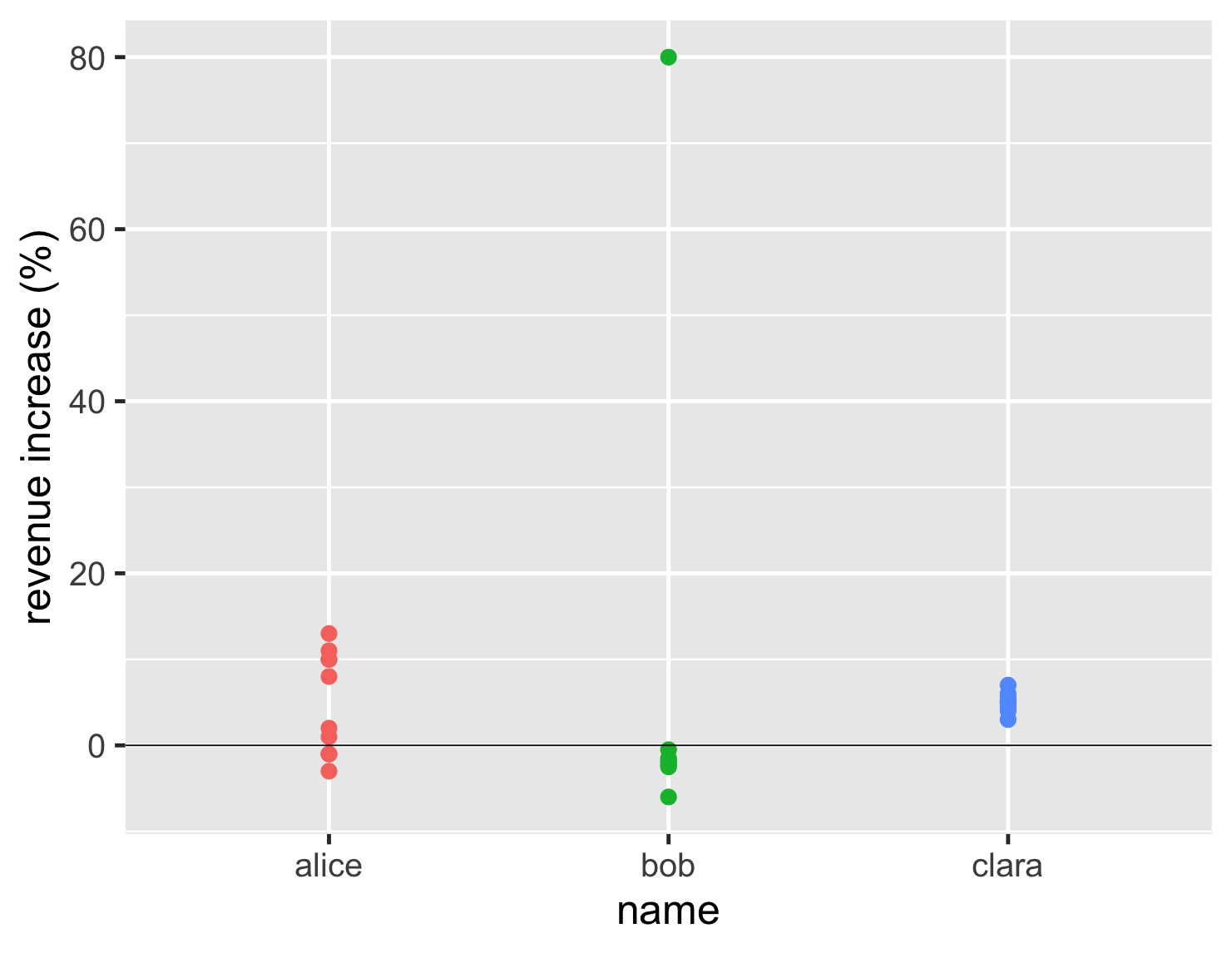
显示代码
ggplot(sales, aes(name, d_revenue, color=name)) + geom_point(size=5, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_gray(base_size=30)
这个图仍然比第一个条形图好,因为它清楚地表明了鲍勃的异常值与他通常的表现有何不同。但由于克拉拉有如此多的相似值,它们都堆叠在一起,因此你无法看到有多少个值。
我使用的第一个技巧是添加一些抖动。这会在条形图的点上添加一些随机的水平移动,这使它们能够散开并区分开来。我的第二个技巧是使点部分透明,这样我们就可以看到它们何时叠加在一起。使用这两个技巧,我们可以正确地了解数据点的数量和位置。
探索直方图的箱宽
直方图通过将数据放入箱中来工作。因此,如果我的箱宽为 1%,那么所有收入增长在 0% 到 1% 之间的帐户都将放入同一个箱中,并且图表将绘制每个箱中包含多少个帐户。因此,箱的宽度(或数量)对我们看到的内容有很大影响。如果我为该数据集创建更大的箱,我将得到这个图。
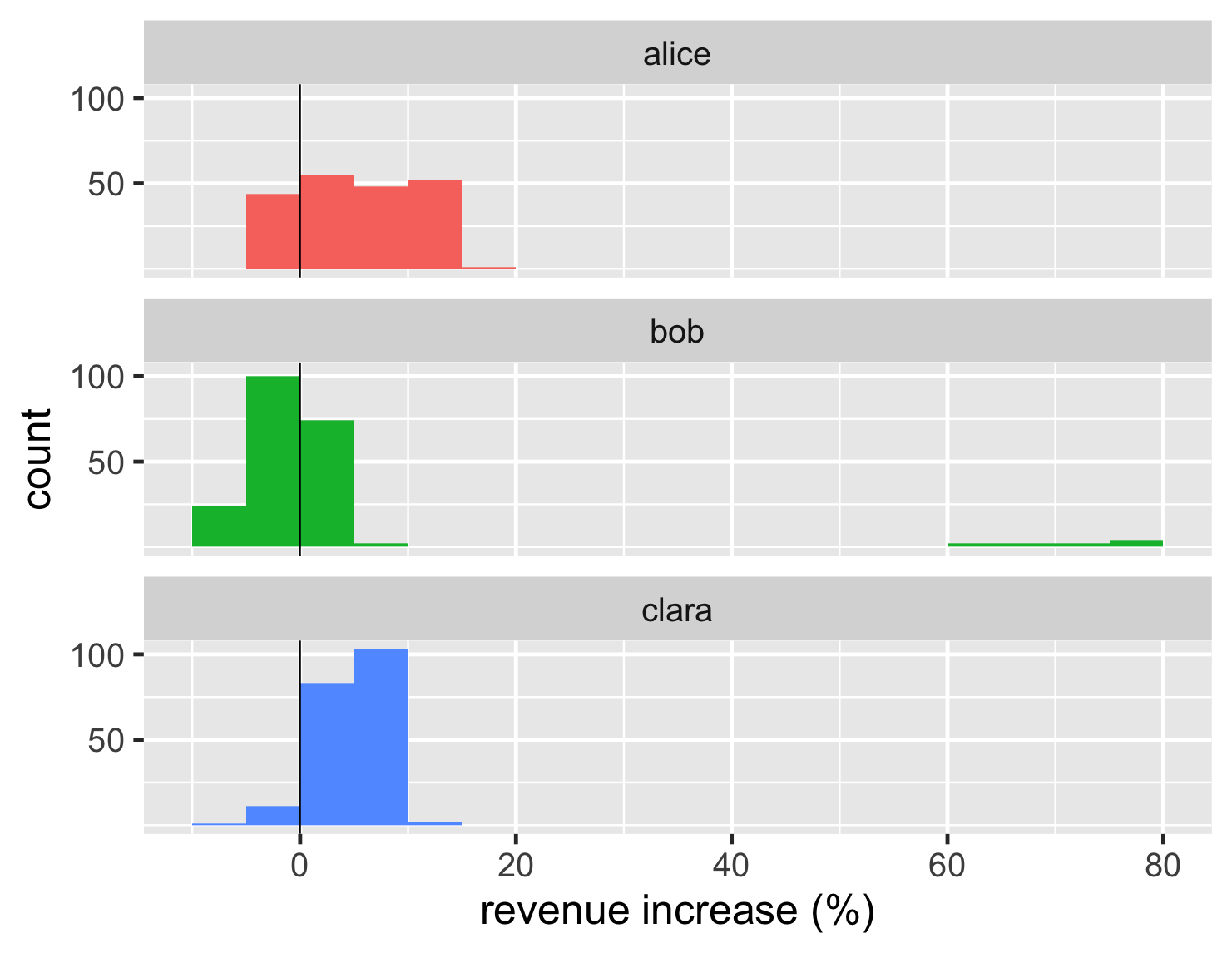
显示代码
ggplot(large_sales, aes(value, fill=name)) + geom_histogram(binwidth = 5, boundary=0,show.legend=FALSE) + scale_y_continuous(breaks = c(50,100)) + xlab(label = "revenue increase (%)") + geom_vline(xintercept = 0) + theme_grey(base_size=30) + facet_wrap(~ name,ncol=1)
在这里,箱太宽了,以至于我们看不到爱丽丝分布的两个峰值。
相反的问题是,如果箱太窄,图表就会变得嘈杂。因此,当我绘制直方图时,我会尝试不同的箱宽,尝试不同的值,看看哪些值有助于揭示数据的有趣特征。
脚注
1: 我充分利用了 SQLite 的扩展函数贡献文件,其中包含许多有用的函数,包括中位数。
重大修订
2020 年 9 月 24 日:发布
2020 年 9 月 18 日:开始起草