
演示域数据分层
2015年8月26日

对信息丰富的程序进行模块化最常见的方法之一是将其分成三个广泛的层:演示(UI)、域逻辑(也称为业务逻辑)和数据访问。因此,您经常会看到 Web 应用程序被分成一个了解如何处理 HTTP 请求和渲染 HTML 的 Web 层、一个包含验证和计算的业务逻辑层,以及一个负责处理如何管理数据库或远程服务中持久化数据的数据库访问层。

总的来说,我发现这对于许多应用程序来说是一种有效的模块化形式,也是我经常使用和鼓励的一种形式。它最大的优势(对我来说)是它允许我通过允许我相对独立地思考这三个主题来缩小我的注意力范围。当我处理域逻辑代码时,我可以基本上忽略 UI,并将与数据源的任何交互视为一组抽象函数,这些函数为我提供我需要的数据并根据我的意愿更新数据。当我处理数据访问层时,我专注于将数据整理成我的接口所需的形式的细节。当我处理演示文稿时,我可以专注于 UI 行为,将要显示或更新的任何数据视为通过函数调用神奇地出现。通过分离这些元素,我缩小了我在每个部分中的思考范围,这使得我更容易遵循我需要做的事情。
这种范围的缩小并不意味着对它们的编程有任何顺序——我通常发现我需要在这些层之间进行迭代。我可能会根据我对 UX 的初始理解来构建数据和域层,但在改进 UX 时,我需要更改域,这需要更改数据层。但即使有这种跨层迭代,我发现专注于一次一层更容易,因为我正在进行更改。这类似于您在使用重构的两种帽子时获得的思维模式切换。
模块化的另一个原因是允许我替换模块的不同实现。这种分离允许我在同一个域逻辑之上构建多个演示文稿,而无需重复它。多个演示文稿可能是 Web 应用程序中的独立页面,具有 Web 应用程序加上移动原生应用程序、用于脚本目的的 API,甚至是一个老式的命令行界面。模块化数据源允许我优雅地应对数据库技术的更改,或者支持可能在短时间内发生变化的持久化服务。但是我必须提到,虽然我经常听到关于数据访问替换是分离数据源层的一个驱动因素,但我很少听到有人真正这样做。
模块化还支持可测试性,这自然会吸引我,因为我是自测试代码的忠实粉丝。模块边界暴露了适合测试的缝隙。UI 代码通常难以测试,因此将尽可能多的逻辑放入域层中是一个好主意,这样可以轻松地进行测试,而无需进行体操才能通过 UI 访问程序[1]。数据访问通常很慢且笨拙,因此在数据层周围使用测试替身通常会使域逻辑测试更容易且更具响应性。
虽然可替换性和可测试性无疑是这种分层的优势,但我必须强调,即使没有这两个原因,我仍然会像这样进行分层。缩小注意力范围的理由本身就足够了。
当谈论这一点时,我们可以将其视为一种模式(演示-域-数据)或将其分成两种模式(演示-域和域-数据)。两种观点都有用——我认为演示-域-数据是演示-域和域-数据的组合。
我认为这些层是一种模块形式,这是一个通用的词,我用来描述我们如何将软件聚集成相对独立的部分。这与代码的对应关系完全取决于我们所处的编程环境。通常,最低级别是某种子例程或函数。面向对象的语言将具有一个类概念,该概念收集函数和数据结构。大多数语言都有一些称为包或命名空间的更高级别,这些命名空间通常可以形成层次结构。模块可能对应于可独立部署的单元:库或服务,但它们不必。
分层可以在这些级别的任何级别发生。一个小型程序可能只是将不同层的单独函数放入不同的文件中。一个更大的系统可能具有与命名空间相对应的层,每个命名空间包含许多类。
我已经提到了三层,但常见的是看到具有三层以上的架构。一个常见的变体是在域和演示文稿之间放置一个服务层,或者将演示文稿层分成单独的层,例如使用演示文稿模型。我发现更多层不会破坏基本模式,因为核心分离仍然存在。
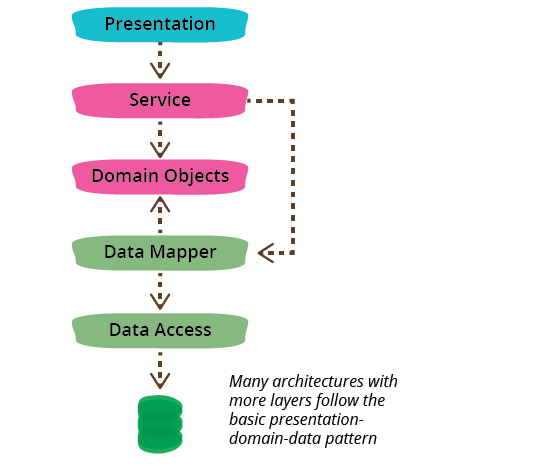
依赖关系通常从上到下贯穿层堆栈:演示文稿依赖于域,然后域依赖于数据源。一个常见的变体是安排事物,以便域不依赖于其数据源,方法是在域和数据源层之间引入一个映射器。这种方法通常被称为六边形架构。
这些层是逻辑层,而不是物理层。我可以在我的笔记本电脑上运行所有三层,我可以在台式机上运行演示文稿和域模型,并在服务器上运行数据库,我可以在浏览器中使用富客户端拆分演示文稿,并在服务器上使用前端后端。在这种情况下,我将 BFF 视为演示文稿层,因为它专注于支持特定的演示文稿选项。
虽然演示文稿-域-数据分离是一种常见的方法,但它应该只应用于相对较小的粒度。随着应用程序的增长,每个层本身可能会变得足够复杂,以至于您需要进一步模块化。当这种情况发生时,通常最好不要使用演示文稿-域-数据作为模块的更高级别。框架通常鼓励您在较小的系统中使用类似视图-模型-数据的顶级命名空间;这对于较小的系统来说是可以的,但是一旦这些层中的任何一层变得太大,您应该将顶级拆分为面向域的模块,这些模块在内部分层。
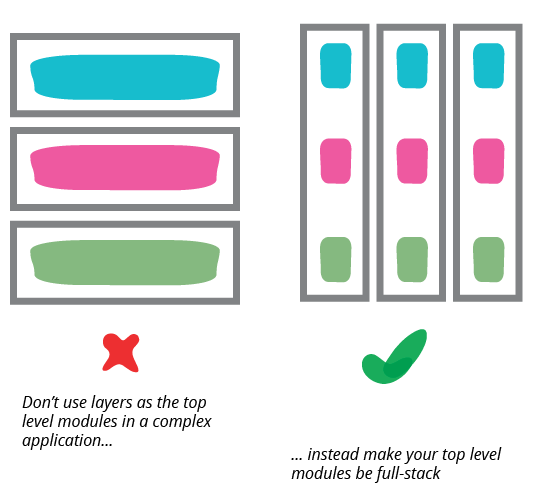
开发人员不必是全栈,但团队应该。
我看到这种分层导致组织走偏的一种常见方式是反模式,即按这些层分离开发团队。这看起来很有吸引力,因为前端和后端开发需要不同的框架(甚至语言),这使得开发人员很容易专门从事其中一个或另一个。将具有共同技能的人员放在一起有利于技能共享,并允许组织将团队视为单个、界限明确的工作类型的提供者。同样,将所有数据库专家放在一起符合数据库和模式的常见集中化。但是,这些层之间丰富的相互作用需要在它们之间频繁切换。当您在同一个团队中拥有可以随意协作的专家时,这并不难,但团队边界会增加相当大的摩擦,并降低个人发展系统重要跨层理解的动机。更糟糕的是,将层分离成团队会增加开发人员和用户之间的距离。开发人员不必是全栈(虽然这是值得称赞的),但团队应该。
进一步阅读
我已经从许多不同的角度在其他地方写过关于这种分离的文章。这种分层驱动了P of EAA的结构,该书的第 1 章详细介绍了这种分层。我没有在书中将这种分层作为一种模式,但我一直在分离的演示文稿和演示文稿域分离中尝试过这个领域。
有关为什么演示文稿-域-数据不应该成为大型系统中最高级别的模块的更多信息,请查看Simon Brown的写作和演讲。我同意他的观点,即软件架构应该嵌入代码中。
我和我的同事Badri Janakiraman就六边形架构的本质进行了引人入胜的讨论。上下文主要围绕使用 Ruby on Rails 的应用程序,但许多想法适用于您可能正在考虑这种方法的其他情况。
致谢
James Lewis、Jeroen Soeters、Marcos Brizeno、Rouan Wilsenach 和 Sean Newham 与我讨论了这篇文章的草稿。注释
1: 页面对象也是帮助围绕 UI 进行测试的重要工具。