
重构访问外部服务的代码
当我编写处理外部服务的代码时,我发现将访问代码分离到单独的对象中非常有价值。在这里,我将展示如何将一些凝固的代码重构为这种分离的常见模式。
2015 年 2 月 17 日

软件系统的一个特点是它们并不独立存在。为了执行有用的操作,它们通常需要与其他软件部分进行通信,这些软件部分由不同的人编写,我们不认识他们,他们也不认识或关心我们正在编写的软件。
当我们编写执行这种外部协作的软件时,我认为应用良好的模块化和封装特别有用。我看到了一些常见的模式,并且发现这些模式在执行此操作时很有价值。
在本文中,我将以一个简单的示例为例,并逐步介绍引入我想要的模块化的重构。
起始代码
示例代码的任务是从 JSON 文件中读取有关视频的一些数据,使用来自 YouTube 的数据对其进行丰富,计算一些简单的进一步数据,然后以 JSON 格式返回数据。
以下是起始代码。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json'))
ids = @video_list.map{|v| v['youtubeID']}
client = GoogleAuthorizer.new(
token_key: 'api-youtube',
application_name: 'Gateway Youtube Example',
application_version: '0.1'
).api_client
youtube = client.discovered_api('youtube', 'v3')
request = {
api_method: youtube.videos.list,
parameters: {
id: ids.join(","),
part: 'snippet, contentDetails, statistics',
}
}
response = JSON.parse(client.execute!(request).body)
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_record = response['items'].find{|v| id == v['id']}
video['views'] = youtube_record['statistics']['viewCount'].to_i
days_available = Date.today - Date.parse(youtube_record['snippet']['publishedAt'])
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list)
end
此示例的语言是 Ruby
我要在这里说的第一件事是,此示例中的代码并不多。如果整个代码库只是这个脚本,那么您不必太担心模块化。我需要一个小的示例,但是如果我们查看一个真实的系统,任何读者的眼睛都会变得呆滞。因此,我必须请您想象这段代码是数万行代码系统中的典型代码。
对 YouTube API 的访问是通过 GoogleAuthorizer 对象进行的,对于本文的目的,我将将其视为外部 API。它处理连接到 Google 服务(如 YouTube)的复杂细节,尤其是处理授权问题。如果您想了解它的工作原理,请查看 我最近写的一篇关于访问 Google API 的文章。
这段代码有什么问题?您可能不理解这段代码执行的所有操作,但您应该能够看到它混合了不同的关注点,我在下面的代码示例中通过颜色进行了标记。为了进行任何更改,您必须理解 如何访问 YouTube 的 API, YouTube 如何构建其数据 以及 一些领域逻辑。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json'))
ids = @video_list.map{|v| v['youtubeID']}
client = GoogleAuthorizer.new(
token_key: 'api-youtube',
application_name: 'Gateway Youtube Example',
application_version: '0.1'
).api_client
youtube = client.discovered_api('youtube', 'v3')
request = {
api_method: youtube.videos.list,
parameters: {
id: ids.join(","),
part: 'snippet, contentDetails, statistics',
}
}
response = JSON.parse(client.execute!(request).body)
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_record = response['items'].find{|v| id == v['id']}
video['views'] = youtube_record['statistics']['viewCount'].to_i
days_available = Date.today - Date.parse(youtube_record['snippet']['publishedAt'])
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list)
end
像我这样的软件专家通常会谈论“关注点分离”——这基本上意味着不同的主题应该在不同的模块中。我这样做最主要的原因是理解:在一个模块化良好的程序中,每个模块都应该只关注一个主题,这样我就可以忽略我不需要理解的任何内容。如果 YouTube 的数据格式发生变化,我不应该需要理解应用程序的领域逻辑来重新排列访问代码。即使我正在进行一个从 YouTube 获取一些新数据并在某些领域逻辑中使用它的更改,我也应该能够将我的任务拆分为这些部分,并分别处理每个部分,从而最大限度地减少我需要记住的代码行数。
我的重构任务是将这些关注点拆分为单独的模块。完成后,Video Service 中的唯一代码应该是未着色的代码——协调这些其他职责的代码。
对代码进行测试
重构的第一步总是相同的。您需要确信您不会无意中破坏任何东西。重构就是将一系列小的步骤串联起来,所有这些步骤都是行为保留的。通过保持步骤很小,我们增加了不搞砸的可能性。但我非常了解自己,我知道即使是最简单的更改我也会搞砸,因此为了获得所需的信心,我必须进行测试来捕捉我的错误。
但是,像这样的代码并不容易测试。最好编写一个测试来断言计算的每月观看次数字段。毕竟,如果其他任何事情出错,这将导致错误的答案。但问题是我正在访问实时 YouTube 数据,而人们有观看视频的习惯。来自 YouTube 的观看次数字段会定期更改,导致我的测试 非确定性地 变为红色。
因此,我的第一个任务是消除这种不稳定性。我可以通过引入一个 测试替身 来做到这一点,测试替身看起来像 YouTube,但以确定性的方式响应。不幸的是,在这里我遇到了遗留代码困境。
遗留代码困境:当我们更改代码时,应该有测试到位。为了将测试到位,我们通常必须更改代码。
鉴于我必须在没有测试的情况下进行此更改,我需要进行最小的、最简单的更改,这些更改可以将与 YouTube 的交互放在一个接缝后面,以便我可以引入测试替身。因此,我的第一步是使用 提取方法 将与 YouTube 的交互从例程的其余部分分离到它自己的方法中。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json'))
ids = @video_list.map{|v| v['youtubeID']}
response = call_youtube ids
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_record = response['items'].find{|v| id == v['id']}
video['views'] = youtube_record['statistics']['viewCount'].to_i
days_available = Date.today - Date.parse(youtube_record['snippet']['publishedAt'])
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list)
end
def call_youtube ids
client = GoogleAuthorizer.new(
token_key: 'api-youtube',
application_name: 'Gateway Youtube Example',
application_version: '0.1'
).api_client
youtube = client.discovered_api('youtube', 'v3')
request = {
api_method: youtube.videos.list,
parameters: {
id: ids.join(","),
part: 'snippet, contentDetails, statistics',
}
}
return JSON.parse(client.execute!(request).body)
end
这样做可以实现两件事。首先,它很好地将 Google API 操作代码提取到它自己的方法中(大部分),将其与任何其他类型的代码隔离。这本身就值得。其次,更紧迫的是,它建立了一个接缝,我可以用来替换测试行为。Ruby 的内置 minitest 库允许我轻松地对对象上的单个方法进行存根。
class VideoServiceTester < Minitest::Test
def setup
vs = VideoService.new
vs.stub(:call_youtube, stub_call_youtube) do
@videos = JSON.parse(vs.video_list)
@µS = @videos.detect{|v| 'wgdBVIX9ifA' == v['youtubeID']}
@evo = @videos.detect{|v| 'ZIsgHs0w44Y' == v['youtubeID']}
end
end
def stub_call_youtube
JSON.parse(File.read('test/data/youtube-video-list.json'))
end
def test_microservices_monthly_json
assert_in_delta 5880, @µS ['monthlyViews'], 1
assert_in_delta 20, @evo['monthlyViews'], 1
end
# further tests as needed…
通过分离 YouTube 调用并对其进行存根,我可以使此测试以确定性的方式运行。至少在今天是这样,为了让它在明天也能工作,我需要对对 Date.today 的调用做同样的事情。
class VideoServiceTester…
def setup
Date.stub(:today, Date.new(2015, 2, 2)) do
vs = VideoService.new
vs.stub(:call_youtube, stub_call_youtube) do
@videos = JSON.parse(vs.video_list)
@µS = @videos.detect{|v| 'wgdBVIX9ifA' == v['youtubeID']}
@evo = @videos.detect{|v| 'ZIsgHs0w44Y' == v['youtubeID']}
end
end
end
将远程调用分离到连接对象中
通过将代码放入不同的函数中来分离关注点是分离的第一级。但是,当关注点像领域逻辑和处理外部数据提供者一样不同时,我更喜欢将分离级别提高到不同的类。
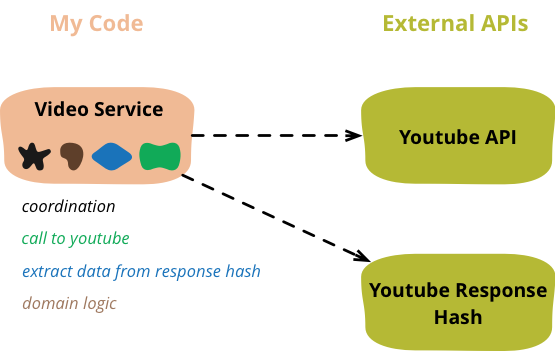
图 1:在开始时,视频服务类包含四个职责
因此,我的第一步是创建一个新类并使用 移动方法。
class VideoService…
def call_youtube ids
YoutubeConnection.new.list_videos ids
end
class YoutubeConnection…
def list_videos ids
client = GoogleAuthorizer.new(
token_key: 'api-youtube',
application_name: 'Gateway Youtube Example',
application_version: '0.1'
).api_client
youtube = client.discovered_api('youtube', 'v3')
request = {
api_method: youtube.videos.list,
parameters: {
id: ids.join(","),
part: 'snippet, contentDetails, statistics',
}
}
return JSON.parse(client.execute!(request).body)
end
有了它,我还可以更改存根,使其返回测试替身,而不是简单地对方法进行存根。
class VideoServiceTester…
def setup
Date.stub(:today, Date.new(2015, 2, 2)) do
YoutubeConnection.stub(:new, YoutubeConnectionStub.new) do
@videos = JSON.parse(VideoService.new.video_list)
@µS = @videos.detect{|v| 'wgdBVIX9ifA' == v['youtubeID']}
@evo = @videos.detect{|v| 'ZIsgHs0w44Y' == v['youtubeID']}
end
end
end
class YoutubeConnectionStub…
def list_videos ids
JSON.parse(File.read('test/data/youtube-video-list.json'))
end
在进行此重构时,我必须警惕,我闪亮的新测试不会捕捉到我在存根后面犯的任何错误,因此我必须手动确保生产代码仍然有效。(是的,正如您所问,我在执行此操作时确实犯了一个错误(省略了对 list-videos 的参数)。我需要进行如此多的测试是有原因的。)
通过使用单独的类获得更大的关注点分离,您还可以获得更好的测试接缝——我可以将需要存根的所有内容包装到单个对象创建中,如果我们需要在测试期间对同一个服务对象进行多次调用,这将特别方便。
将对 YouTube 的调用移动到连接对象后,视频服务上的方法不再值得保留,因此我将其进行 内联方法 处理。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json'))
ids = @video_list.map{|v| v['youtubeID']}
response = YoutubeConnection.new.list_videos ids
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_record = response['items'].find{|v| id == v['id']}
video['views'] = youtube_record['statistics']['viewCount'].to_i
days_available = Date.today - Date.parse(youtube_record['snippet']['publishedAt'])
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list)
end
def call_youtube ids
YoutubeConnection.new.list_videos ids
end
我不喜欢我的存根必须解析 json 字符串。总的来说,我喜欢将连接对象保持为 谦虚对象,因为它们执行的任何行为都不会被测试。因此,我更喜欢将解析提取到调用者中。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json'))
ids = @video_list.map{|v| v['youtubeID']}
response = JSON.parse(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_record = response['items'].find{|v| id == v['id']}
video['views'] = youtube_record['statistics']['viewCount'].to_i
days_available = Date.today - Date.parse(youtube_record['snippet']['publishedAt'])
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list)
end
class YoutubeConnection…
def list_videos ids
client = GoogleAuthorizer.new(
token_key: 'api-youtube',
application_name: 'Gateway Youtube Example',
application_version: '0.1'
).api_client
youtube = client.discovered_api('youtube', 'v3')
request = {
api_method: youtube.videos.list,
parameters: {
id: ids.join(","),
part: 'snippet, contentDetails, statistics',
}
}
return JSON.parse(client.execute!(request).body)
end
class YoutubeConnectionStub…
def list_videos ids
JSON.parse(File.read('test/data/youtube-video-list.json'))
end
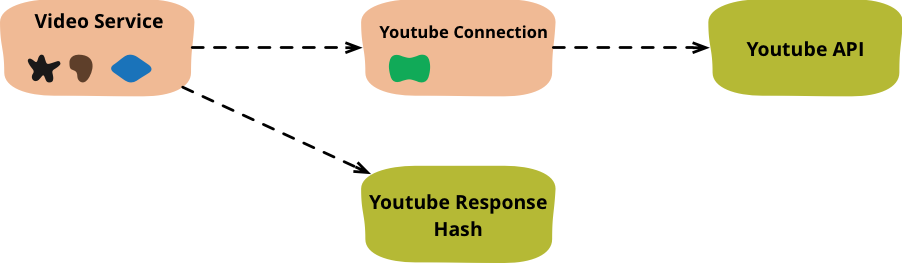
图 2:第一步将 YouTube 连接代码分离到一个 连接 对象中。
将 YouTube 数据结构分离到网关中
现在我已经将对 YouTube 的基本连接分离并可以存根,我可以处理深入研究 YouTube 数据结构的代码。这里的问题是,一堆代码需要知道要获取观看次数数据,您必须查看结果的“statistics”部分,但要获取发布日期,您需要查看“snippet”部分。这种深入研究在来自远程源的数据中很常见,它以对他们有意义的方式进行组织,而不是对我来说。这是完全合理的,他们没有洞察我的需求,我自己做这件事已经够麻烦了。
我发现一个很好的思考方式是 Eric Evans 的 限界上下文 概念。YouTube 根据其上下文组织其数据,而我想根据不同的上下文组织我的数据。组合两个限界上下文的代码会变得复杂,因为它混合了两个独立的词汇。我需要使用 Eric 所谓的反腐败层将它们分离,在它们之间建立一个清晰的边界。他用中国的长城来举例说明反腐败层,就像任何这样的墙一样,我们需要允许某些东西通过它们之间的网关。在软件术语中,网关允许我穿过墙,从 YouTube 限界上下文获取我需要的数据。但网关应该以在我的上下文中而不是在他们的上下文中具有意义的方式表达。
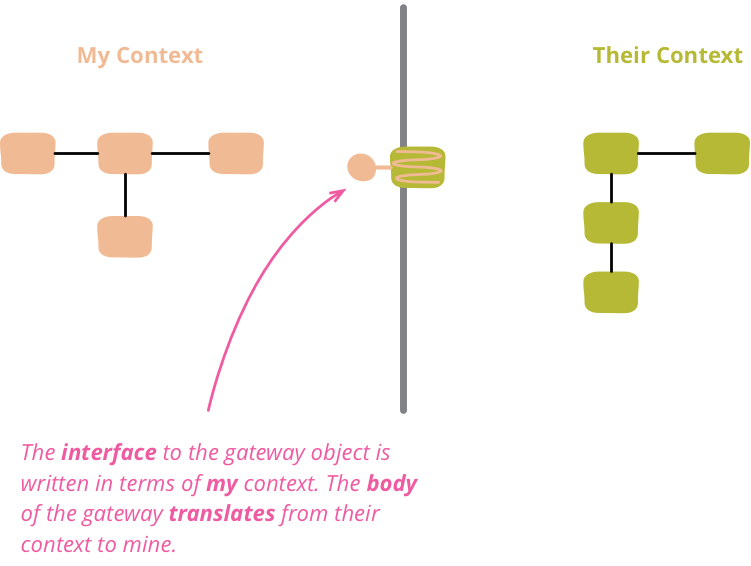
在这个简单的示例中,这意味着一个网关对象,它可以提供发布日期和观看次数,而客户端无需知道这些数据在 YouTube 数据结构中的存储方式。网关对象将 YouTube 的上下文转换为我的上下文。
我首先创建一个网关对象,用我从连接中获得的响应对其进行初始化。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json'))
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_record = youtube.record(id)
video['views'] = youtube_record['statistics']['viewCount'].to_i
days_available = Date.today - Date.parse(youtube_record['snippet']['publishedAt'])
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list)
end
class YoutubeGateway…
def initialize responseJson
@data = JSON.parse(responseJson)
end
def record id
@data['items'].find{|v| id == v['id']}
end
在这一点上,我创建了最简单的行为,即使我最终不打算使用网关的 record 方法,实际上,除非我停下来喝杯茶,否则我认为它不会持续半个小时。
现在,我将查看视图的深入逻辑从服务移动到网关,创建一个单独的网关项目类来表示每个视频记录。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json'))
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_record = youtube.record(id)
video['views'] = youtube.item(id)['views']
days_available = Date.today - Date.parse(youtube_record['snippet']['publishedAt'])
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list)
end
class YoutubeGateway…
def item id
{
'views' => record(id)['statistics']['viewCount'].to_i
}
end
我对发布日期也执行相同的操作
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json'))
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_record = youtube.record(id)
video['views'] = youtube.item(id)['views']
days_available = Date.today - youtube.item(id)['published']
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list)
end
class YoutubeGateway…
def item id
{
'views' => record(id)['statistics']['viewCount'].to_i,
'published' => Date.parse(record(id)['snippet']['publishedAt'])
}
end
由于我使用的是网关中按键查找的记录,因此我想在内部数据结构中更好地反映这种用法,我可以通过用哈希替换列表来做到这一点
class YoutubeGateway…
def initialize responseJson @data = JSON.parse(responseJson)['items'] .map{|i| [ i['id'], i ] } .to_h end def item id { 'views' => @data[id]['statistics']['viewCount'].to_i, 'published' => Date.parse(@data[id]['snippet']['publishedAt']) } end def record id @data['items'].find{|v| id == v['id']} end
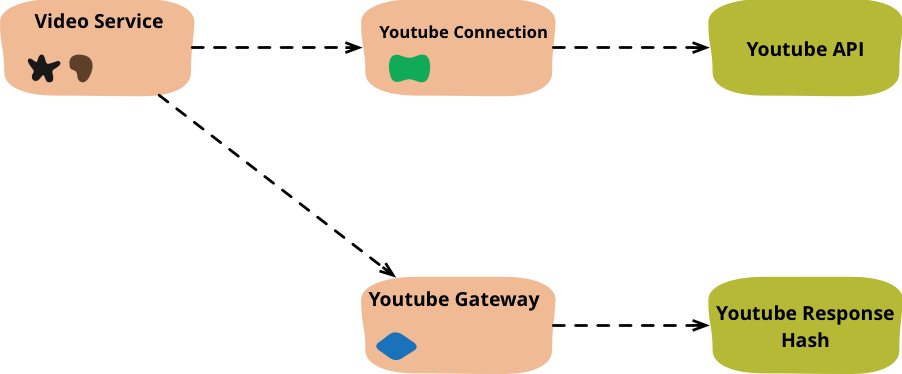
图 4:将数据处理分离到一个 网关 对象中
完成这些操作后,我已经完成了我想做的关键分离。YouTube 连接对象处理对 YouTube 的调用,返回一个数据结构,它将其提供给 YouTube 网关对象。服务代码现在只关注我想要查看数据的形式,而不是它在不同服务中的存储方式。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json'))
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
video['views'] = youtube.item(id)['views']
days_available = Date.today - youtube.item(id)['published']
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list)
end
将领域逻辑分离到领域对象中
虽然与 YouTube 的所有交互现在都被分配到单独的对象中,但视频服务仍然将它的领域逻辑(如何计算每月观看次数)与编排本地存储的数据和服务中数据的之间的关系混合在一起。如果我为视频引入一个领域对象,我可以将它们分离出来。
我的第一步是简单地将视频数据的哈希包装在一个对象中。
class Video…
def initialize aHash
@data = aHash
end
def [] key
@data[key]
end
def []= key, value
@data[key] = value
end
def to_h
@data
end
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json')).map{|h| Video.new(h)}
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
video['views'] = youtube.item(id)['views']
days_available = Date.today - youtube.item(id)['published']
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list.map{|v| v.to_h})
end
为了将计算逻辑移动到新的视频对象中,我首先需要将其转换为适合移动的形状——我可以通过将所有逻辑都封装到视频服务上的单个方法中来做到这一点,该方法将视频领域对象和 YouTube 网关项目作为参数。第一步是使用
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json')).map{|h| Video.new(h)}
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_item = youtube.item(id)
video['views'] = youtube_item['views']
days_available = Date.today - youtube_item['published']
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
return JSON.dump(@video_list.map{|v| v.to_h})
end
完成这些操作后,我可以轻松地将计算逻辑提取到它自己的方法中。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json')).map{|h| Video.new(h)}
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_item = youtube.item(id)
enrich_video video, youtube_item
end
return JSON.dump(@video_list.map{|v| v.to_h})
end
def enrich_video video, youtube_item
video['views'] = youtube_item['views']
days_available = Date.today - youtube_item['published']
video['monthlyViews'] = video['views'] * 365.0 / days_available / 12
end
然后,很容易应用 Move Method 将其移入视频。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json')).map{|h| Video.new(h)}
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_item = youtube.item(id)
video.enrich_with_youtube youtube_item
end
return JSON.dump(@video_list.map{|v| v.to_h})
end
class Video…
def enrich_with_youtube youtube_item @data['views'] = youtube_item['views'] days_available = Date.today - youtube_item['published'] @data['monthlyViews'] = @data['views'] * 365.0 / days_available / 12 end
完成之后,我可以删除对视频哈希的更新。
class Video…
def []= key, value
@data[key] = value
end
现在我有合适的对象了,我可以使用服务方法中的 ID 简化编排。我首先使用 Inline Temp 在 youtube_item 上,然后用视频对象上的方法调用替换对枚举索引的引用。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json')).map{|h| Video.new(h)}
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
ids.each do |id|
video = @video_list.find{|v| id == v['youtubeID']}
youtube_item = youtube.item(id)
video.enrich_with_youtube(youtube.item(video.youtube_id))
end
return JSON.dump(@video_list.map{|v| v.to_h})
end
class Video…
def youtube_id
@data['youtubeID']
end
这允许我直接使用对象进行枚举。
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json')).map{|h| Video.new(h)}
ids = @video_list.map{|v| v['youtubeID']}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
@video_list.each {|v| v.enrich_with_youtube(youtube.item(v.youtube_id))}
return JSON.dump(@video_list.map{|v| v.to_h})
end
并删除视频中哈希的访问器。
class Video…
def [] key
@data[key]
end
class VideoService…
def video_list
@video_list = JSON.parse(File.read('videos.json')).map{|h| Video.new(h)}
ids = @video_list.map{|v| v.youtube_id}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
@video_list.each {|v| v.enrich_with_youtube(youtube.item(v.youtube_id))}
return JSON.dump(@video_list.map{|v| v.to_h})
end
我可以将视频对象的内部哈希替换为字段,但我认为不值得,因为它主要使用哈希加载,最终输出是 JSON 化的哈希。一个 嵌入式文档 是一个完全合理的域对象形式。
对最终对象的思考
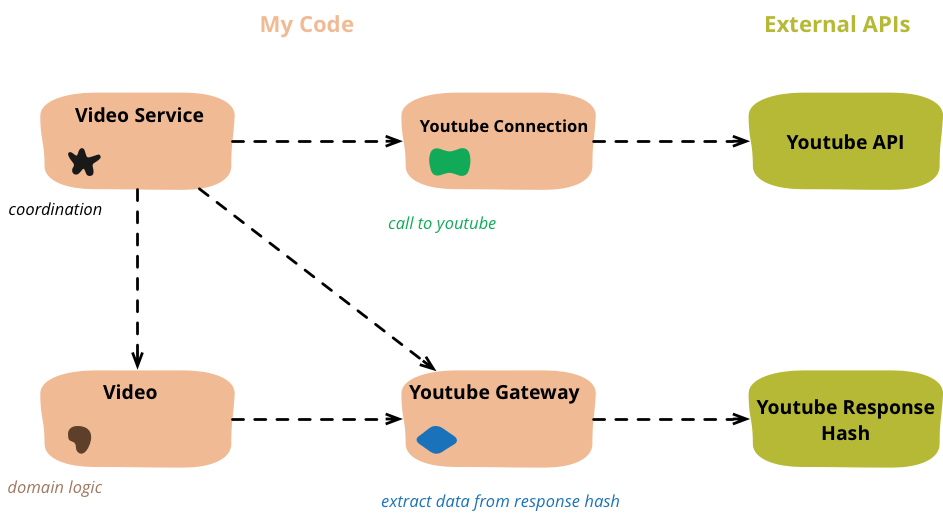
图 5:通过此重构创建的对象及其依赖关系
class VideoService...
def video_list
@video_list = JSON.parse(File.read('videos.json')).map{|h| Video.new(h)}
ids = @video_list.map{|v| v.youtube_id}
youtube = YoutubeGateway.new(YoutubeConnection.new.list_videos(ids))
@video_list.each {|v| v.enrich_with_youtube(youtube.item(v.youtube_id))}
return JSON.dump(@video_list.map{|v| v.to_h})
end
class YoutubeConnection
def list_videos ids
client = GoogleAuthorizer.new(
token_key: 'api-youtube',
application_name: 'Gateway Youtube Example',
application_version: '0.1'
).api_client
youtube = client.discovered_api('youtube', 'v3')
request = {
api_method: youtube.videos.list,
parameters: {
id: ids.join(","),
part: 'snippet, contentDetails, statistics',
}
}
return client.execute!(request).body
end
end
class YoutubeGateway
def initialize responseJson
@data = JSON.parse(responseJson)['items']
.map{|i| [ i['id'], i ] }
.to_h
end
def item id
{
'views' => @data[id]['statistics']['viewCount'].to_i,
'published' => Date.parse(@data[id]['snippet']['publishedAt'])
}
end
end
class Video
def initialize aHash
@data = aHash
end
def to_h
@data
end
def youtube_id
@data['youtubeID']
end
def enrich_with_youtube youtube_item
@data['views'] = youtube_item['views']
days_available = Date.today - youtube_item['published']
@data['monthlyViews'] = @data['views'] * 365.0 / days_available / 12
end
end
那么我取得了什么成就呢?重构通常会减少代码量,但在这种情况下,代码量几乎翻了一番,从 26 行增加到 54 行。在其他条件相同的情况下,代码越少越好。但我认为,通过将关注点分离,获得更好的模块化通常值得代码量增加。这也是教学(即玩具)示例的规模可能会掩盖重点的地方。26 行代码并不难理解,但如果我们谈论的是以这种风格编写的 2600 行代码,那么模块化就非常值得代码量增加。通常,当你在更大的代码库中做这种事情时,任何这样的增加都会小得多,因为你会发现更多通过消除重复来减少代码量的机会。
你会注意到,我在这里完成了四种对象:协调器、域对象、网关和连接。这是一种常见的职责安排,尽管不同的情况会看到依赖关系布局的合理变化。由于特定需求,最佳的职责和依赖关系安排会有所不同。需要频繁更改的代码应该与很少更改的代码或仅因不同原因而更改的代码分开。被广泛重用的代码不应该依赖于仅用于特定情况的代码。这些驱动因素因情况而异,并决定了依赖关系模式。
一个常见的变化是反转域对象和网关之间的依赖关系——将网关变成一个 Mapper。这允许域对象独立于其填充方式,但代价是映射器需要了解域对象并获得对其内部结构的访问权限。如果域对象在许多上下文中使用,那么这可能是一种有价值的安排。
另一个变化可能是将调用连接的代码从协调器移到网关。这简化了协调器,但使网关稍微复杂了一些。这是否是一个好主意取决于协调器是否变得过于复杂,或者许多协调器是否使用相同的网关,导致在设置连接时出现重复代码。
我还认为,我可能会将连接的一些行为移到调用者,特别是如果调用者是网关对象。网关知道它需要什么数据,因此应该在调用的参数中提供零件列表。但这实际上只在我们有其他客户端调用 list_videos 时才会出现问题,因此我倾向于等到那天。
我认为很重要的一件事是,无论你的具体情况如何,都要对所涉及对象的职责有一个一致的命名策略。我偶尔会听到有人说你不应该将模式名称放入你的代码中,但我不同意。模式名称通常有助于传达不同元素扮演的角色,因此拒绝这种机会是愚蠢的。当然,在一个团队中,你的代码会显示常见的模式,命名应该反映这一点。我使用“网关”来遵循我在 P of EAA 中创造的 网关 模式。我在这里使用了“连接”来显示与外部系统的原始链接,并打算在我的未来写作中使用这种约定。这种命名约定并非普遍适用,虽然你使用我的命名约定会让我感到自豪,但重要的是,你应该选择一些约定,而不是你应该使用哪种命名约定。
当我将一个方法分解成这样一组对象时,关于测试结果自然会产生一个问题。我在视频服务中有一个原始方法的单元测试,现在我应该为三个新类编写测试吗?我的倾向是,如果现有的测试充分涵盖了行为,那么没有必要立即添加更多测试。随着我们添加更多行为,我们应该添加更多测试,如果这种行为被添加到新对象中,那么新的测试将集中在它们身上。随着时间的推移,这可能意味着当前针对视频服务的某些测试看起来不合适,应该移动。但所有这些都将在未来进行,应该在未来处理。
我在测试中特别关注的是我放在 YouTube 连接上的存根的使用。像这样的存根很容易失控,然后它们实际上会减慢更改速度,因为简单的生产代码更改会导致更新许多测试。这里的关键是关注测试代码中的重复,并像对待生产代码中的重复一样认真地解决它。
这种关于组织测试替身的思考自然会引出组装服务对象的更广泛问题。现在我已经将一个行为从单个服务对象拆分为三个服务对象和一个域实体(使用 Evans 分类),关于如何实例化、配置和组装服务对象自然会产生一个问题。目前,视频服务直接为其依赖项执行此操作,但这在更大的系统中很容易失控。为了处理这种复杂性,通常使用 服务定位器和依赖注入 等技术。我现在不打算讨论这个问题,但这可能是后续文章的主题。
这个例子使用了对象,很大程度上是因为我对面向对象风格比对函数式风格更熟悉。但我预计基本职责划分将相同,但边界由函数(或可能是命名空间)而不是类和方法设置。其他一些细节会发生变化,视频对象将是一个数据结构,丰富它将创建新的数据结构,而不是就地修改。从函数式风格的角度来看,这将是一篇有趣的文章。
重构是一种通过一系列微小的行为保持转换来更改代码的特定方法。它不仅仅是移动代码。
最后,我想再次强调关于重构的一个重要的普遍观点。重构不是你应该用来对代码库进行任何重构的术语。它特别指的是应用一系列非常小的行为保持更改的方法。我们在这里看到了几个例子,我故意引入了我知道很快就会删除的代码,只是为了能够采取保持行为的小步骤。
这里的重点是,通过采取小步骤,你最终会更快地完成,因为你不会破坏任何东西,从而避免调试。大多数人发现这违反直觉,当我肯特·贝克第一次向我展示他如何重构时,我当然也这么认为。但我很快发现它有多有效。
重大修订
2015 年 2 月 17 日:首次发布