
控制反转容器和依赖注入模式
在 Java 社区中,出现了一批轻量级容器,它们帮助将来自不同项目的组件组装成一个有凝聚力的应用程序。这些容器的底层是一个通用的模式,它们是如何执行连接的,它们在一个非常通用的名称“控制反转”下引用这个概念。在这篇文章中,我深入探讨了这种模式是如何工作的,在更具体的名称“依赖注入”下,并将其与服务定位器替代方案进行对比。它们之间的选择不如将配置与使用分离的原则重要。
2004 年 1 月 23 日

企业 Java 世界中一件有趣的事情是,在构建主流 J2EE 技术的替代方案方面,有大量的活动,其中大部分发生在开源领域。很多都是对主流 J2EE 世界中重量级复杂性的反应,但也很多是在探索替代方案并提出创造性的想法。一个常见的需要解决的问题是如何将不同的元素连接在一起:如何将这个 Web 控制器架构与那个数据库接口连接起来,而它们是由不同的团队构建的,彼此之间了解甚少。许多框架已经尝试解决这个问题,并且一些框架正在扩展以提供组装来自不同层的组件的通用功能。这些通常被称为轻量级容器,例如 PicoContainer 和 Spring。
这些容器的底层是一些有趣的设计原则,这些原则超越了这两个特定容器,甚至超越了 Java 平台。在这里,我想开始探索其中的一些原则。我使用的示例是 Java,但就像我大多数写作一样,这些原则同样适用于其他 OO 环境,特别是 .NET。
组件和服务
将元素连接在一起的主题几乎立即把我带入了围绕“服务”和“组件”这两个术语的复杂术语问题。你可以很容易地找到关于这些事物的定义的冗长且相互矛盾的文章。出于我的目的,以下是我目前对这些重载术语的使用。
我使用“组件”来表示一个软件块,它旨在被应用程序使用,而无需更改,该应用程序不受组件编写者的控制。我所说的“无需更改”是指使用应用程序不会更改组件的源代码,尽管它们可以通过组件编写者允许的方式扩展组件来改变组件的行为。
服务类似于组件,因为它被外部应用程序使用。主要区别在于,我希望组件在本地使用(想想 jar 文件、程序集、dll 或源代码导入)。服务将通过某种远程接口远程使用,无论是同步还是异步(例如 Web 服务、消息系统、RPC 或套接字)。
在这篇文章中,我主要使用“服务”,但许多相同的逻辑也可以应用于本地组件。事实上,你通常需要某种本地组件框架才能轻松访问远程服务。但是,写“组件或服务”读起来和写起来都很累,而且服务目前更流行。
一个简单的例子
为了帮助使所有这些更具体,我将使用一个运行示例来讨论所有这些。就像我所有的示例一样,这是一个超级简单的示例;它足够小,不切实际,但希望足够让你直观地了解正在发生的事情,而不会陷入真实示例的泥潭。
在这个示例中,我正在编写一个组件,它提供由特定导演执导的电影列表。这个惊人有用的功能由一个方法实现。
class MovieLister...
public Movie[] moviesDirectedBy(String arg) {
List allMovies = finder.findAll();
for (Iterator it = allMovies.iterator(); it.hasNext();) {
Movie movie = (Movie) it.next();
if (!movie.getDirector().equals(arg)) it.remove();
}
return (Movie[]) allMovies.toArray(new Movie[allMovies.size()]);
}
这个函数的实现非常天真,它要求一个查找器对象(我们稍后会讲到)返回它知道的每部电影。然后,它只在这个列表中搜索,以返回由特定导演执导的电影。我不会修复这个特定的天真之处,因为它只是这篇文章真正要点的支架。
这篇文章的真正要点是这个查找器对象,或者更确切地说,我们如何将 lister 对象与特定的查找器对象连接起来。之所以有趣,是因为我希望我精彩的 moviesDirectedBy 方法完全独立于所有电影的存储方式。因此,该方法所做的只是引用一个查找器,而该查找器所做的只是知道如何响应 findAll 方法。我可以通过为查找器定义一个接口来实现这一点。
public interface MovieFinder {
List findAll();
}
现在,所有这些都很好地解耦了,但在某个时刻,我必须想出一个具体的类来实际获取电影。在这种情况下,我把这段代码放在 lister 类的构造函数中。
class MovieLister...
private MovieFinder finder;
public MovieLister() {
finder = new ColonDelimitedMovieFinder("movies1.txt");
}
实现类的名称来自我从冒号分隔的文本文件中获取列表的事实。我将省去细节,毕竟重点只是存在一些实现。
现在,如果我只是为自己使用这个类,那么一切都很好。但是,当我的朋友们渴望获得这个精彩的功能,并想要一份我的程序副本时,会发生什么?如果他们也把他们的电影列表存储在一个名为“movies1.txt”的冒号分隔的文本文件中,那么一切都会很好。如果他们为他们的电影文件使用了不同的名称,那么将文件名放在属性文件中很容易。但是,如果他们使用完全不同的方式存储他们的电影列表:SQL 数据库、XML 文件、Web 服务,或者只是另一种格式的文本文件,会发生什么?在这种情况下,我们需要一个不同的类来获取这些数据。现在,因为我已经定义了 MovieFinder 接口,所以这不会改变我的 moviesDirectedBy 方法。但是,我仍然需要某种方法将正确的查找器实现实例放到位。
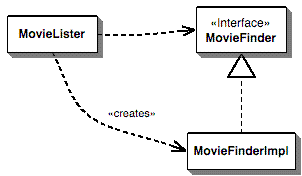
图 1:使用 lister 类中的简单创建的依赖关系
图 1 显示了这种情况下的依赖关系。MovieLister 类依赖于 MovieFinder 接口和实现。我们希望它只依赖于接口,但如果那样,我们如何创建一个实例来使用呢?
{kind=link}
在我的书 P of EAA 中,我们描述了这种情况为 插件。查找器的实现类不会在编译时链接到程序中,因为我不知道我的朋友们将使用什么。相反,我们希望我的 lister 可以与任何实现一起工作,并且该实现可以在稍后的某个时刻被插入,不受我的控制。问题是如何建立这种连接,以便我的 lister 类不知道实现类,但仍然可以与一个实例通信以完成它的工作。
将此扩展到一个真实的系统,我们可能会有几十个这样的服务和组件。在每种情况下,我们可以通过与它们通过接口通信来抽象我们对这些组件的使用(如果组件不是为接口而设计的,则使用适配器)。但是,如果我们希望以不同的方式部署这个系统,我们需要使用插件来处理与这些服务的交互,以便我们可以在不同的部署中使用不同的实现。
因此,核心问题是如何将这些插件组装成一个应用程序?这是这一代新型轻量级容器面临的主要问题之一,并且它们普遍都使用控制反转来解决这个问题。
控制反转
当这些容器谈论它们之所以如此有用是因为它们实现了“控制反转”时,我感到非常困惑。控制反转 是框架的常见特征,因此说这些轻量级容器之所以特殊是因为它们使用控制反转,就像说我的汽车之所以特殊是因为它有轮子一样。
问题是:“他们正在反转哪方面的控制?”当我第一次遇到控制反转时,它是在用户界面的主要控制中。早期的用户界面由应用程序程序控制。你将有一系列命令,例如“输入姓名”、“输入地址”;你的程序将驱动提示并获取对每个提示的响应。使用图形(甚至基于屏幕的)UI,UI 框架将包含这个主循环,而你的程序则提供屏幕上各个字段的事件处理程序。程序的主要控制被反转了,从你那里转移到了框架。
对于这一代新型容器,反转是关于它们如何查找插件实现。在我的简单示例中,lister 通过直接实例化查找器实现来查找它。这阻止了查找器成为插件。这些容器使用的方法是确保任何插件用户都遵循一些约定,这些约定允许一个单独的组装模块将实现注入到 lister 中。
因此,我认为我们需要一个更具体的名称来描述这种模式。控制反转是一个过于通用的术语,因此人们会发现它令人困惑。因此,经过与各种 IoC 支持者的多次讨论,我们最终确定了“依赖注入”这个名称。
我将从讨论依赖注入的各种形式开始,但我要指出,这不是消除应用程序类对插件实现依赖的唯一方法。你可以用来实现这一点的另一种模式是服务定位器,我将在解释完依赖注入后讨论它。
依赖注入的形式
依赖注入的基本思想是拥有一个单独的对象,一个组装器,它使用适当的查找器接口实现来填充 lister 类中的一个字段,从而产生类似于 图 2 的依赖关系图。
{kind=link}
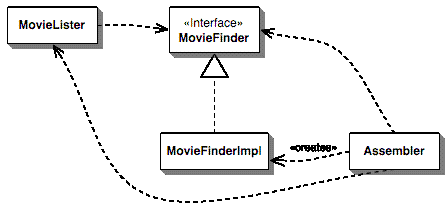
图 2:依赖注入器的依赖关系
依赖注入主要有三种风格。我为它们使用的名称是构造函数注入、Setter 注入和接口注入。如果你在当前关于控制反转的讨论中阅读了这些内容,你会听到它们被称为类型 1 IoC(接口注入)、类型 2 IoC(Setter 注入)和类型 3 IoC(构造函数注入)。我发现数字名称很难记住,这就是我在这里使用我自己的名称的原因。
使用 PicoContainer 的构造函数注入
我将从展示如何使用一个名为 PicoContainer 的轻量级容器来完成这种注入开始。我之所以从这里开始,主要是因为我在 Thoughtworks 的几位同事非常积极地参与了 PicoContainer 的开发(是的,这是一种公司裙带关系)。
PicoContainer 使用构造函数来决定如何将查找器实现注入到 lister 类中。为了使这能够工作,电影 lister 类需要声明一个包含所有需要注入内容的构造函数。
class MovieLister...
public MovieLister(MovieFinder finder) {
this.finder = finder;
}
查找器本身也将由 pico 容器管理,因此,容器将把文本文件的名称注入到其中。
class ColonMovieFinder...
public ColonMovieFinder(String filename) {
this.filename = filename;
}
然后,pico 容器需要被告知将哪个实现类与每个接口关联,以及将哪个字符串注入到查找器中。
private MutablePicoContainer configureContainer() {
MutablePicoContainer pico = new DefaultPicoContainer();
Parameter[] finderParams = {new ConstantParameter("movies1.txt")};
pico.registerComponentImplementation(MovieFinder.class, ColonMovieFinder.class, finderParams);
pico.registerComponentImplementation(MovieLister.class);
return pico;
}
此配置代码通常在另一个类中设置。在我们的示例中,每个使用我的列表器的朋友都可以在他们自己的某个设置类中编写相应的配置代码。当然,将这种配置信息保存在单独的配置文件中很常见。您可以编写一个类来读取配置文件并适当地设置容器。虽然 PicoContainer 本身不包含此功能,但有一个密切相关的项目称为 NanoContainer,它提供了适当的包装器,允许您拥有 XML 配置文件。这样的纳米容器将解析 XML,然后配置底层的 pico 容器。该项目的理念是将配置文件格式与底层机制分离。
要使用容器,您需要编写类似这样的代码。
public void testWithPico() {
MutablePicoContainer pico = configureContainer();
MovieLister lister = (MovieLister) pico.getComponentInstance(MovieLister.class);
Movie[] movies = lister.moviesDirectedBy("Sergio Leone");
assertEquals("Once Upon a Time in the West", movies[0].getTitle());
}
虽然在这个例子中我使用了构造函数注入,但 PicoContainer 也支持 setter 注入,尽管它的开发者更喜欢构造函数注入。
使用 Spring 的 Setter 注入
The Spring framework 是一个广泛的企业 Java 开发框架。它包括事务、持久化框架、Web 应用程序开发和 JDBC 的抽象层。与 PicoContainer 一样,它也支持构造函数和 setter 注入,但它的开发者倾向于更喜欢 setter 注入 - 这使得它成为此示例的合适选择。
为了让我的电影列表器接受注入,我为该服务定义了一个设置方法
class MovieLister...
private MovieFinder finder;
public void setFinder(MovieFinder finder) {
this.finder = finder;
}
类似地,我为文件名定义了一个 setter。
class ColonMovieFinder...
public void setFilename(String filename) {
this.filename = filename;
}
第三步是设置文件的配置。Spring 支持通过 XML 文件和代码进行配置,但 XML 是预期的方式。
<beans>
<bean id="MovieLister" class="spring.MovieLister">
<property name="finder">
<ref local="MovieFinder"/>
</property>
</bean>
<bean id="MovieFinder" class="spring.ColonMovieFinder">
<property name="filename">
<value>movies1.txt</value>
</property>
</bean>
</beans>
然后测试看起来像这样。
public void testWithSpring() throws Exception {
ApplicationContext ctx = new FileSystemXmlApplicationContext("spring.xml");
MovieLister lister = (MovieLister) ctx.getBean("MovieLister");
Movie[] movies = lister.moviesDirectedBy("Sergio Leone");
assertEquals("Once Upon a Time in the West", movies[0].getTitle());
}
接口注入
第三种注入技术是为注入定义和使用接口。 Avalon 是一个在某些地方使用此技术的框架示例。我稍后会详细介绍,但在这种情况下,我将使用一些简单的示例代码。
使用此技术,我首先定义一个接口,我将通过它执行注入。这是将电影查找器注入对象的接口。
public interface InjectFinder {
void injectFinder(MovieFinder finder);
}
此接口将由提供 MovieFinder 接口的人定义。任何想要使用查找器的类(例如列表器)都需要实现它。
class MovieLister implements InjectFinder
public void injectFinder(MovieFinder finder) {
this.finder = finder;
}
我使用类似的方法将文件名注入查找器实现中。
public interface InjectFinderFilename {
void injectFilename (String filename);
}
class ColonMovieFinder implements MovieFinder, InjectFinderFilename...
public void injectFilename(String filename) {
this.filename = filename;
}
然后,像往常一样,我需要一些配置代码来连接实现。为了简单起见,我将在代码中执行此操作。
class Tester...
private Container container;
private void configureContainer() {
container = new Container();
registerComponents();
registerInjectors();
container.start();
}
此配置有两个阶段,通过查找键注册组件与其他示例非常相似。
class Tester...
private void registerComponents() {
container.registerComponent("MovieLister", MovieLister.class);
container.registerComponent("MovieFinder", ColonMovieFinder.class);
}
一个新步骤是注册将注入依赖组件的注入器。每个注入接口都需要一些代码来注入依赖对象。在这里,我通过在容器中注册注入器对象来做到这一点。每个注入器对象都实现了注入器接口。
class Tester...
private void registerInjectors() {
container.registerInjector(InjectFinder.class, container.lookup("MovieFinder"));
container.registerInjector(InjectFinderFilename.class, new FinderFilenameInjector());
}
public interface Injector {
public void inject(Object target);
}
当依赖项是为该容器编写的类时,组件本身实现注入器接口是有意义的,就像我在这里对电影查找器所做的那样。对于通用类,例如字符串,我在配置代码中使用内部类。
class ColonMovieFinder implements Injector...
public void inject(Object target) {
((InjectFinder) target).injectFinder(this);
}
class Tester...
public static class FinderFilenameInjector implements Injector {
public void inject(Object target) {
((InjectFinderFilename)target).injectFilename("movies1.txt");
}
}
然后测试使用容器。
class Tester…
public void testIface() {
configureContainer();
MovieLister lister = (MovieLister)container.lookup("MovieLister");
Movie[] movies = lister.moviesDirectedBy("Sergio Leone");
assertEquals("Once Upon a Time in the West", movies[0].getTitle());
}
容器使用声明的注入接口来确定依赖项,并使用注入器来注入正确的依赖项。(我在这里做的特定容器实现对该技术并不重要,我不会展示它,因为你只会笑。)
使用服务定位器
依赖注入的关键优势在于它消除了MovieLister 类对具体MovieFinder 实现的依赖。这使我可以将列表器提供给朋友,让他们为自己的环境插入合适的实现。注入不是打破这种依赖的唯一方法,另一种方法是使用 服务定位器。
服务定位器背后的基本思想是拥有一个对象,它知道如何获取应用程序可能需要的全部服务。因此,此应用程序的服务定位器将有一个方法,在需要时返回电影查找器。当然,这只是将负担转移了一点,我们仍然必须将定位器放入列表器中,从而导致 图 3 的依赖关系
{kind=link}
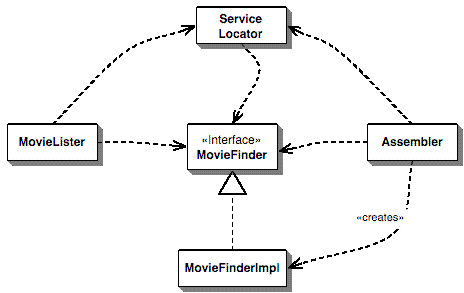
图 3:服务定位器的依赖关系
在这种情况下,我将使用 ServiceLocator 作为单例 注册表。然后,列表器可以在实例化时使用它来获取查找器。
class MovieLister...
MovieFinder finder = ServiceLocator.movieFinder();
class ServiceLocator...
public static MovieFinder movieFinder() {
return soleInstance.movieFinder;
}
private static ServiceLocator soleInstance;
private MovieFinder movieFinder;
与注入方法一样,我们必须配置服务定位器。在这里,我是在代码中执行此操作,但使用从配置文件读取适当数据的机制并不难。
class Tester...
private void configure() {
ServiceLocator.load(new ServiceLocator(new ColonMovieFinder("movies1.txt")));
}
class ServiceLocator...
public static void load(ServiceLocator arg) {
soleInstance = arg;
}
public ServiceLocator(MovieFinder movieFinder) {
this.movieFinder = movieFinder;
}
这是测试代码。
class Tester...
public void testSimple() {
configure();
MovieLister lister = new MovieLister();
Movie[] movies = lister.moviesDirectedBy("Sergio Leone");
assertEquals("Once Upon a Time in the West", movies[0].getTitle());
}
我经常听到这样的抱怨,这些服务定位器不好,因为它们不可测试,因为你无法用实现替换它们。当然,你可以设计得很糟糕,从而陷入这种麻烦,但你没有必要这样做。在这种情况下,服务定位器实例只是一个简单的數據持有者。我可以轻松地使用我的服务的测试实现创建定位器。
对于更复杂的定位器,我可以子类化服务定位器并将该子类传递到注册表的类变量中。我可以更改静态方法以调用实例上的方法,而不是直接访问实例变量。我可以通过使用线程特定存储来提供线程特定定位器。所有这些都可以完成,而无需更改服务定位器的客户端。
可以这样想,服务定位器是一个注册表,而不是一个单例。单例提供了一种实现注册表的简单方法,但这种实现决策很容易改变。
使用隔离的接口进行定位
上述简单方法的一个问题是,MovieLister 依赖于完整的服务定位器类,即使它只使用一项服务。我们可以通过使用 角色接口 来减少这一点。这样,列表器就可以声明它需要的接口部分,而不是使用完整的服务定位器接口。
在这种情况下,列表器的提供者也会提供一个定位器接口,它需要它来获取查找器。
public interface MovieFinderLocator {
public MovieFinder movieFinder();
然后,定位器需要实现此接口以提供对查找器的访问。
MovieFinderLocator locator = ServiceLocator.locator(); MovieFinder finder = locator.movieFinder();
public static ServiceLocator locator() {
return soleInstance;
}
public MovieFinder movieFinder() {
return movieFinder;
}
private static ServiceLocator soleInstance;
private MovieFinder movieFinder;
你会注意到,由于我们想使用接口,我们不能再通过静态方法访问服务了。我们必须使用该类来获取定位器实例,然后使用它来获取我们需要的東西。
动态服务定位器
上面的示例是静态的,因为服务定位器类对您需要的每项服务都有方法。这不是唯一的做法,您还可以创建一个动态服务定位器,允许您将您需要的任何服务存储到其中,并在运行时做出选择。
在这种情况下,服务定位器使用映射而不是每个服务的字段,并提供通用方法来获取和加载服务。
class ServiceLocator...
private static ServiceLocator soleInstance;
public static void load(ServiceLocator arg) {
soleInstance = arg;
}
private Map services = new HashMap();
public static Object getService(String key){
return soleInstance.services.get(key);
}
public void loadService (String key, Object service) {
services.put(key, service);
}
配置涉及使用适当的键加载服务。
class Tester...
private void configure() {
ServiceLocator locator = new ServiceLocator();
locator.loadService("MovieFinder", new ColonMovieFinder("movies1.txt"));
ServiceLocator.load(locator);
}
我使用相同的键字符串使用服务。
class MovieLister...
MovieFinder finder = (MovieFinder) ServiceLocator.getService("MovieFinder");
总的来说,我不喜欢这种方法。虽然它确实很灵活,但它并不明确。我找到到达服务的唯一方法是通过文本键。我更喜欢显式方法,因为通过查看接口定义更容易找到它们的位置。
使用 Avalon 同时使用定位器和注入
依赖注入和服务定位器不一定是相互排斥的概念。将两者结合使用的很好的例子是 Avalon 框架。Avalon 使用服务定位器,但使用注入来告诉组件在哪里找到定位器。
Berin Loritsch 向我发送了这个使用 Avalon 的运行示例的简单版本。
public class MyMovieLister implements MovieLister, Serviceable {
private MovieFinder finder;
public void service( ServiceManager manager ) throws ServiceException {
finder = (MovieFinder)manager.lookup("finder");
}
服务方法是接口注入的一个例子,允许容器将服务管理器注入 MyMovieLister。服务管理器是服务定位器的一个例子。在这个例子中,列表器不会将管理器存储在字段中,而是立即使用它来查找查找器,它确实存储了查找器。
决定使用哪个选项
到目前为止,我一直专注于解释我对这些模式及其变体的看法。现在我可以开始谈论它们的优缺点,以帮助确定使用哪些模式以及何时使用。
服务定位器与依赖注入
基本选择是在服务定位器和依赖注入之间。第一点是,两种实现都提供了朴素示例中缺少的基本解耦 - 在这两种情况下,应用程序代码都独立于服务接口的具体实现。两种模式之间的重要区别在于如何将该实现提供给应用程序类。使用服务定位器,应用程序类通过向定位器发送消息来显式请求它。使用注入,没有显式请求,服务出现在应用程序类中 - 因此控制反转。
控制反转是框架的常见特征,但它是有代价的。它往往难以理解,并在尝试调试时导致问题。因此,总的来说,除非需要,否则我更愿意避免它。这并不是说它不好,只是我认为它需要比更直接的替代方案更能证明自己的价值。
关键区别在于,使用服务定位器,每个服务用户都对定位器有依赖关系。定位器可以隐藏对其他实现的依赖关系,但您确实需要看到定位器。因此,定位器和注入器之间的决定取决于这种依赖关系是否是一个问题。
使用依赖注入可以帮助更容易地查看组件依赖关系。使用依赖注入器,您只需查看注入机制(例如构造函数)即可查看依赖关系。使用服务定位器,您必须搜索源代码以查找对定位器的调用。具有查找引用功能的现代 IDE 使这更容易,但它仍然不如查看构造函数或设置方法容易。
这在很大程度上取决于服务的用户的性质。如果您正在构建一个使用服务的各种类的应用程序,那么应用程序类对定位器的依赖关系就不是什么大问题。在我的将电影列表器提供给朋友的例子中,使用服务定位器效果很好。他们只需要配置定位器以挂钩正确的服务实现,无论是通过一些配置代码还是通过配置文件。在这种情况下,我认为注入器的反转并没有提供任何令人信服的东西。
如果列表器是我提供给其他人编写的应用程序的组件,则差异就会出现。在这种情况下,我对客户将使用的服务定位器的 API 知之甚少。每个客户可能都有他们自己的不兼容的服务定位器。我可以通过使用隔离的接口来解决其中的一些问题。每个客户都可以编写一个适配器,将我的接口与他们的定位器匹配,但在任何情况下,我仍然需要看到第一个定位器来查找我的特定接口。一旦适配器出现,那么直接连接到定位器的简单性就开始消失。
由于使用注入器,组件没有对注入器的依赖关系,因此一旦组件被配置,它就无法从注入器获取更多服务。
人们更喜欢依赖注入的一个常见原因是它使测试更容易。这里的意思是,为了进行测试,您需要轻松地用存根或模拟替换真实的服務实现。但是,依赖注入和服务定位器之间实际上没有区别:两者都非常适合存根。我怀疑这种观察来自人们没有努力确保他们的服务定位器可以轻松替换的项目。这就是持续测试的帮助所在,如果您无法轻松地为测试存根服务,那么这意味着您的设计存在严重问题。
当然,测试问题因侵入性很强的组件环境而加剧,例如 Java 的 EJB 框架。我认为,这些框架应该尽量减少对应用程序代码的影响,特别是不要做会减慢编辑-执行循环的事情。使用插件来替换重量级组件对这个过程有很大帮助,这对测试驱动开发等实践至关重要。
因此,主要问题是对于那些编写预期在编写者控制之外的应用程序中使用的代码的人来说。在这些情况下,即使是对服务定位器的最小假设也是一个问题。
构造函数注入与 Setter 注入
对于服务组合,你总是需要一些约定来将它们连接在一起。注入的优势主要在于它只需要非常简单的约定 - 至少对于构造函数和 setter 注入而言。你不需要在你的组件中做任何奇怪的事情,并且注入器可以相当直接地配置所有内容。
接口注入更具侵入性,因为你必须编写大量接口才能将所有内容整理好。对于容器所需的一小部分接口,例如 Avalon 的方法,这并不算太糟糕。但对于组装组件和依赖项来说,这需要大量工作,这就是当前轻量级容器使用 setter 和构造函数注入的原因。
setter 和构造函数注入之间的选择很有趣,因为它反映了面向对象编程中一个更普遍的问题 - 你应该在构造函数中填充字段还是使用 setter。
我长期以来对对象的默认做法是在构造时尽可能创建有效的对象。这条建议可以追溯到 Kent Beck 的 Smalltalk 最佳实践模式:构造函数方法和构造函数参数方法。带参数的构造函数让你在显眼的位置清楚地说明创建有效对象的含义。如果有多种方法可以做到这一点,请创建多个构造函数来显示不同的组合。
构造函数初始化的另一个优点是它允许你通过简单地不提供 setter 来清楚地隐藏任何不可变的字段。我认为这很重要 - 如果某样东西不应该改变,那么缺少 setter 会很好地传达这一点。如果你使用 setter 进行初始化,那么这可能会很麻烦。(实际上,在这些情况下,我更喜欢避免通常的设置约定,我更喜欢像 initFoo 这样的方法,以强调这应该是你在出生时才应该做的事情。)
但在任何情况下都会有例外。如果你有很多构造函数参数,事情看起来会很乱,尤其是在没有关键字参数的语言中。确实,很长的构造函数通常是对象过于繁忙的标志,应该将其拆分,但有些情况下你需要这样做。
如果你有多种方法可以构造一个有效的对象,那么很难通过构造函数来显示这一点,因为构造函数只能在参数的数量和类型上有所不同。这时工厂方法就派上用场了,它们可以使用私有构造函数和 setter 的组合来实现它们的工作。经典工厂方法用于组件组装的问题是,它们通常被视为静态方法,而你不能在接口上使用它们。你可以创建一个工厂类,但这只会变成另一个服务实例。工厂服务通常是一个好策略,但你仍然需要使用这里介绍的技术之一来实例化工厂。
如果你有简单的参数,例如字符串,那么构造函数也会受到影响。使用 setter 注入,你可以为每个 setter 指定一个名称来指示字符串应该做什么。使用构造函数,你只是依赖于位置,这更难理解。
如果你有多个构造函数和继承,那么事情可能会变得特别尴尬。为了初始化所有内容,你必须提供构造函数来转发到每个超类构造函数,同时还要添加你自己的参数。这会导致构造函数的爆炸式增长。
尽管有这些缺点,但我更倾向于从构造函数注入开始,但要准备好一旦我上面概述的问题开始成为问题就切换到 setter 注入。
这个问题导致了在提供依赖注入作为其框架一部分的各个团队之间进行了很多争论。然而,似乎大多数构建这些框架的人已经意识到,支持这两种机制很重要,即使他们更喜欢其中一种。
代码或配置文件
一个独立但经常混淆的问题是,是否应该使用配置文件或 API 上的代码来连接服务。对于大多数可能在许多地方部署的应用程序来说,单独的配置文件通常是最有意义的。几乎所有时候,这都将是一个 XML 文件,这是有道理的。但是,在某些情况下,使用程序代码进行组装更容易。一种情况是,你有一个简单的应用程序,它没有很多部署变化。在这种情况下,一些代码可能比单独的 XML 文件更清晰。
相反的情况是,组装非常复杂,涉及条件步骤。一旦你开始接近编程语言,那么 XML 就会开始崩溃,最好使用一种具有所有语法来编写清晰程序的真实语言。然后,你编写一个构建器类来进行组装。如果你有不同的构建器场景,你可以提供多个构建器类,并使用一个简单的配置文件在它们之间进行选择。
我经常认为人们过于急于定义配置文件。通常,编程语言可以提供一种简单而强大的配置机制。现代语言可以轻松地编译小型汇编器,这些汇编器可以用来组装大型系统的插件。如果编译很痛苦,那么也有一些脚本语言可以很好地工作。
人们经常说配置文件不应该使用编程语言,因为它们需要由非程序员编辑。但这种情况有多常见?人们真的期望非程序员更改复杂服务器端应用程序的事务隔离级别吗?非语言配置文件只有在它们很简单的情况下才能很好地工作。如果它们变得复杂,那么就该考虑使用适当的编程语言了。
目前我们在 Java 世界中看到的是配置文件的喧嚣,每个组件都有自己的配置文件,这些配置文件与其他所有人的配置文件都不一样。如果你使用十几个这样的组件,你很容易最终得到十几个需要保持同步的配置文件。
我在这里的建议是始终提供一种方法,通过编程接口轻松地完成所有配置,然后将单独的配置文件视为可选功能。你可以轻松地构建配置文件处理来使用编程接口。如果你正在编写一个组件,那么你可以让你的用户决定是使用编程接口、你的配置文件格式,还是编写他们自己的自定义配置文件格式并将其与编程接口绑定。
将配置与使用分离
所有这些中最重要的问题是确保服务的配置与服务的用法分离。实际上,这是一个基本的设计原则,它与接口与实现的分离相一致。当条件逻辑决定要实例化哪个类时,我们在面向对象程序中看到了这一点,然后对该条件的未来评估是通过多态性而不是通过重复的条件代码来完成的。
如果这种分离在单个代码库中很有用,那么当你使用外部元素(如组件和服务)时,它尤其重要。第一个问题是你是否希望将实现类的选择推迟到特定的部署。如果是这样,你需要使用某种插件实现。一旦你开始使用插件,那么插件的组装就必须与应用程序的其余部分分开进行,以便你可以轻松地为不同的部署替换不同的配置。你如何实现这一点是次要的。这种配置机制可以配置服务定位器,也可以使用注入直接配置对象。
一些进一步的问题
在这篇文章中,我重点介绍了使用依赖注入和服务定位器进行服务配置的基本问题。还有一些与之相关的其他主题也值得关注,但我还没有时间深入研究。特别是生命周期行为问题。一些组件具有不同的生命周期事件:例如停止和启动。另一个问题是人们越来越关注在这些容器中使用面向方面的方法。虽然我目前没有在文章中考虑这些内容,但我确实希望通过扩展这篇文章或编写另一篇文章来对此进行更多阐述。
你可以通过查看专门用于轻量级容器的网站来了解更多关于这些想法的信息。从 picocontainer 和 spring 网站浏览将引导你进入更多关于这些问题的讨论,并开始了解一些进一步的问题。
总结
当前涌现的轻量级容器都具有一个共同的底层模式,用于它们如何进行服务组装 - 依赖注入模式。依赖注入是服务定位器的有用替代方案。在构建应用程序类时,两者大致相当,但我认为服务定位器由于其更直接的行为而略占优势。但是,如果你正在构建要在多个应用程序中使用的类,那么依赖注入是更好的选择。
如果你使用依赖注入,那么有许多风格可供选择。我建议你遵循构造函数注入,除非你遇到这种方法的特定问题,在这种情况下,请切换到 setter 注入。如果你选择构建或获取容器,请寻找一个支持构造函数注入和 setter 注入的容器。
服务定位器和依赖注入之间的选择不如将服务配置与应用程序中服务的用法分离的原则重要。
致谢
我衷心感谢许多帮助我完成这篇文章的人。Rod Johnson、Paul Hammant、Joe Walnes、Aslak Hellesøy、Jon Tirsén 和 Bill Caputo 帮助我掌握了这些概念,并对这篇文章的早期草稿提出了意见。Berin Loritsch 和 Hamilton Verissimo de Oliveira 对 Avalon 如何融入其中提供了一些非常有益的建议。Dave W Smith 坚持询问我最初的接口注入配置代码,从而让我面对这样一个事实,即它很愚蠢。Gerry Lowry 为我发送了许多拼写错误的修正 - 足以超过感谢的阈值。
重大修订
2004 年 1 月 23 日:重新设计了接口注入示例的配置代码。
2004 年 1 月 16 日:添加了 Avalon 的定位器和注入的简短示例。
2004 年 1 月 14 日:首次出版