
使用云计算扩展 Etsy
2022 年 11 月 29 日

Tim Cochran 是 Thoughtworks 美国东部市场技术总监。Tim 拥有超过 19 年的经验,领导着从初创企业到大型企业的各种领域的工作,例如零售、金融服务和政府。他为组织提供技术战略方面的建议,并帮助他们做出正确的技术投资,以实现数字化转型目标。他是一位开发人员体验的坚定倡导者,并且热衷于使用数据驱动的方法来改进开发人员体验。

Keyur 是 Etsy 的首席架构师和基础设施工程副总裁。在他任职期间,他领导了多次重大的架构变更,最近一次是迁移到 Google Cloud。在此职位之前,他是系统工程团队的关键成员,帮助扩展网站并确保 PHP、MySQL、Memcached、Redis 和 Linux 内核平稳运行。

本文是以下系列的一部分:规模化瓶颈
Etsy 是一个在线市场,专门销售独特的手工和复古商品,在过去五年中取得了快速增长。然后,疫情极大地改变了购物者的习惯,导致更多消费者选择在线购物。结果,Etsy 市场从 2019 年底的 4570 万买家增长到 2021 年底的 9010 万买家(增长 97%),同期卖家数量从 250 万增长到 530 万(增长 112%)。
这种增长极大地增加了对技术平台的需求,导致流量一夜之间增长了近 3 倍。而且 Etsy 需要为更多客户提供持续的优质体验。为了满足这种需求,他们必须大幅扩展基础设施、产品交付和人才。虽然这种增长给团队带来了挑战,但业务从未出现瓶颈。Etsy 的团队能够交付新的改进功能,市场继续提供出色的客户体验。本文和下一篇文章讲述了 Etsy 的扩展策略。
Etsy 的基础扩展工作早在疫情爆发之前就已开始。2017 年,Mike Fisher 加入担任首席技术官。Josh Silverman 最近加入 Etsy 担任首席执行官,并建立了制度纪律,以开启一段增长时期。Mike 拥有扩展高增长公司的背景,并与 Martin Abbott 合著了关于该主题的几本书,包括 可扩展性艺术 和 可扩展性规则。
Etsy 依赖于两个数据中心的物理硬件,这带来了几个扩展挑战。随着预期增长,很明显成本会迅速增加。这影响了产品团队的敏捷性,因为他们必须提前计划容量。此外,数据中心位于一个州,这构成了可用性风险。很明显,他们需要尽快迁移到云计算。经过评估,Mike 和他的团队选择 Google Cloud Platform (GCP) 作为云合作伙伴,并开始 计划将他们的许多系统迁移到云计算。
在云迁移进行的同时,Etsy 正在发展其业务和团队。Mike 发现产品交付流程是另一个潜在的扩展瓶颈。赋予产品团队的自主权导致了一个问题:每个团队都以不同的方式交付。加入一个团队意味着学习一套新的实践,这很成问题,因为 Etsy 正在招聘许多新人。此外,他们还注意到一些产品计划没有达到预期效果。这些指标促使领导层重新评估其产品规划和交付流程的有效性。
战略原则
Mike Fisher(首席技术官)和 Keyur Govande(首席架构师)制定了最初的云迁移策略,其中包含以下原则
最小可行产品 - Etsy 希望避免的一种典型反模式是重建过多,从而延长迁移时间。相反,他们使用 MVP 的精益概念,以尽可能快且廉价的方式验证 Etsy 的系统是否可以在云中运行,并消除对数据中心的依赖。
本地决策 - 每个团队都可以对其拥有的内容做出自己的决定,并接受项目团队的监督。Etsy 的平台被分成许多功能,例如计算、可观察性和 ML 基础设施,以及面向领域的应用程序堆栈,例如搜索、竞价引擎和通知。每个团队都进行了概念验证,以制定迁移计划。主要的市场应用程序是一个著名的庞大单体应用程序,因此需要创建一个跨团队的计划来重点关注它。
不改变开发人员体验 - Etsy 将高质量的开发人员体验视为生产力和员工幸福的关键。重要的是,基于云的系统继续提供开发人员依赖的功能,例如快速反馈和复杂的可观察性。
他们还面临着与现有数据中心合同相关的截止日期,他们非常希望能够按时完成。
使用合作伙伴
为了加快云迁移速度,Etsy 希望引入外部专业知识,帮助他们采用新的工具和技术,例如 Terraform、Kubernetes 和 Prometheus。与 Thoughtworks 的许多典型客户不同,Etsy 没有一个迫切的平台来推动他们对参与的根本需求。他们是一家数字原生公司,一直采用现代化的软件开发方法。尽管没有一个具体的问题需要解决,但 Etsy 知道还有改进的空间。因此,参与方法是在整个平台组织中进行嵌入。Thoughtworks 的基础设施工程师和技术产品经理加入了搜索基础设施、持续部署服务、计算、可观察性和机器学习基础设施团队。
增量式联合方法
对市场单体应用程序进行的最初“提升和迁移”到云计算是最困难的。该团队希望保持单体应用程序的完整性,并进行最少的更改。但是,它使用了 LAMP 堆栈,因此很难重新构建平台。他们进行了一些测试性能和容量的预演。虽然第一次切换失败了,但他们能够快速回滚。按照 Etsy 的典型风格,他们庆祝了这次失败,并将其作为学习的机会。最终,它在 9 个月内完成,比最初计划的整整一年时间还要短。在最初迁移之后,单体应用程序随后进行了调整和优化,使其更好地适应云环境,添加了诸如自动扩展和自动修复不良节点等功能。
与此同时,其他堆栈也在迁移。虽然每个团队都创建了自己的迁移路径,但团队并非完全独立。Etsy 使用了一个跨团队的架构咨询小组来分享更广泛的背景,并帮助在整个公司范围内进行模式匹配。例如,搜索堆栈迁移到 GKE,作为云计算的一部分,这比单体应用程序的提升和迁移操作花费的时间更长。另一个例子是数据湖迁移。Etsy 拥有一个内部部署的 Vertica 集群,他们将其迁移到 Big Query,在此过程中改变了所有内容。
不出所料,在云迁移之后,Etsy 对云的优化并没有停止。每个团队都继续寻找机会,以最大程度地利用云计算。在架构咨询小组的帮助下,他们研究了以下问题:如何通过迁移到行业标准工具来减少自定义代码量,如何提高成本效益,以及如何改进反馈循环。
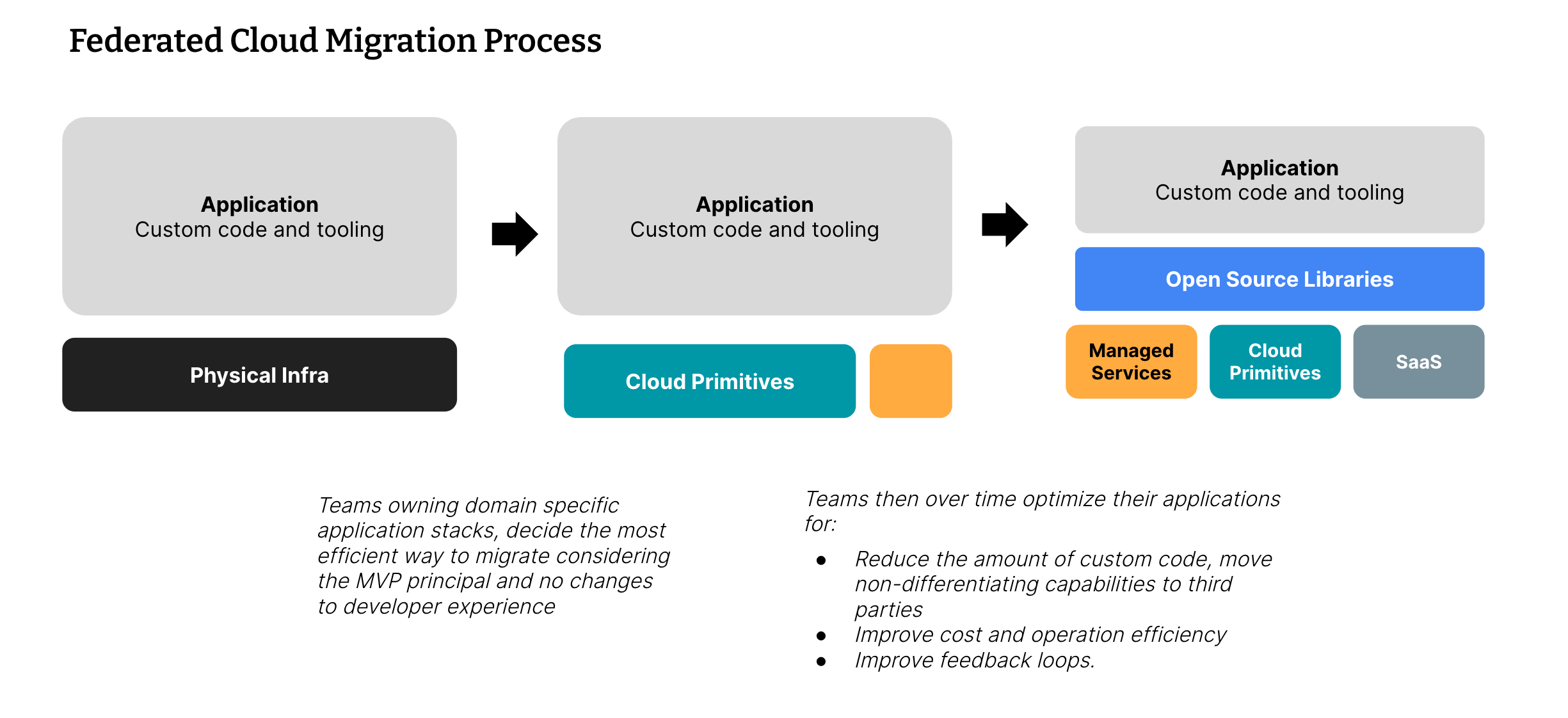
图 1:联合云迁移
例如,让我们看看可观察性和 ML 基础设施这两个团队的迁移路径
观察一切的挑战
Etsy 以衡量一切而闻名,“如果它在移动,我们就跟踪它”。操作指标(跟踪、指标和日志)被整个公司用来创造价值。产品经理和数据分析师利用这些数据进行规划,并证明想法的预期价值。产品团队使用它来支持其各自责任领域的正常运行时间和性能。
由于 Etsy 致力于超可观察性,因此被分析的数据量并不小。可观察性是自助式的;每个团队都可以决定要衡量什么。他们使用 8000 万个指标系列,涵盖网站和支持基础设施。这将每天产生 20 TB 的日志。
当 Etsy 最初制定这一策略时,市场上并没有很多工具和服务能够满足他们苛刻的要求。在许多情况下,他们最终不得不自己构建工具。例如 StatsD,这是一种统计数据聚合工具,现在已经开源,并在整个行业中使用。随着时间的推移,DevOps 运动蓬勃发展,行业也赶上了。许多创新的可观察性工具(例如 Prometheus)出现了。随着云迁移,Etsy 可以评估市场并利用第三方工具来降低运营成本。
可观察性堆栈是最后迁移的,因为它非常复杂。它需要重建,而不是提升和迁移。他们依赖于大型服务器,而为了有效地使用云计算,他们应该使用许多更小的服务器,并轻松地进行水平扩展。他们将堆栈的大部分迁移到托管服务和第三方 SaaS 产品。一个例子是引入 Lightstep,他们可以使用它来外包跟踪处理。仍然需要在内部进行一定程度的处理,以处理 Etsy 依赖的独特场景。
迁移到云计算使更好的 ML 平台成为可能
Etsy 的一个重要创新来源是他们利用机器学习的方式。
Etsy 利用机器学习 (ML) 为全球数百万买家创造个性化的体验,提供最先进的搜索、广告和推荐。Etsy 的 ML 平台团队通过开发和维护 Etsy 的 ML 从业人员依赖的技术基础设施来支持我们的机器学习实验,这些基础设施用于大规模地对 ML 模型进行原型设计、训练和部署。
迁移到云计算使 Etsy 能够构建一个基于托管服务的新 ML 平台,既降低了运营成本,又缩短了从想法生成到生产部署的时间。
由于他们的资源位于云中,他们现在可以依赖云功能。他们使用 Dataflow 进行 ETL,使用 Vertex AI 训练他们的模型。随着他们看到这些工具取得成功,他们确保设计平台使其可扩展到其他工具。为了使其广泛可用,他们采用了行业标准工具,例如 TensorFlow 和 Kubernetes。Etsy 在开发和测试 ML 方面的生产力远远超过了他们之前的性能。正如 Rob 和 Kyle 所说,“我们估计从想法到实时 ML 实验的时间缩短了约 50%。”
然而,这种性能增长并非没有挑战。随着数据规模的增长,高性能代码的重要性也随之提高。如果代码性能低下,客户体验可能会受到影响,因此该团队必须构建一个高度优化的系统。“看似微不足道的低效率,例如非矢量化代码,会导致巨大的性能下降,在某些情况下,我们发现优化单个张量流转换函数可以将模型运行时间从 200 毫秒缩短到 4 毫秒。” 从数字上看,这是一个两个数量级的改进,但在商业方面,这是一种客户可以轻松感知到的性能变化。
云计算的挑战是什么?
Etsy 必须运营自己的基础设施,并且许多平台团队的技能都在系统运营方面。迁移到云计算使团队能够使用更高抽象级别,由基础设施即代码进行管理。他们改变了基础设施招聘,寻找软件工程技能。这与现有团队产生了摩擦;有些人非常兴奋,但另一些人对这种新方法感到担忧。
虽然云计算确实减少了他们需要管理的事项,并简化了规划,但它并没有完全让他们摆脱容量规划。云服务仍然运行在带有 CPU 和磁盘的服务器上,在某些情况下,仍然需要针对未来的负载进行适当调整。展望未来,随着按需云服务的改进,Etsy 希望能够减少这种容量规划。
疫情的压力测试
Etsy 一直以来都是以数据中心为基础的,这在某些方面限制了他们的发展。由于他们对数据中心的投入非常大,因此他们没有利用云供应商开发的新产品。例如,他们的数据中心设置缺乏强大的 API 来管理配置和容量。
当 Mike Fisher 加入 Etsy 时,他们开始了云迁移之旅。这为他们未来的成功奠定了基础,因为迁移基本上在疫情爆发前就完成了。这在几个方面体现出来:他们没有遇到容量瓶颈,尽管流量在一夜之间暴涨了 2-3 倍,因为事件数量从 10 亿增加到了 60 亿。
在疫情期间,云计算为他们提供了灵活性,并有一些具体的例子可以证明这一点。例如,云计算使他们能够缩小“语义差距”,确保搜索“口罩”时能显示出布口罩,而不是化妆品或服装类型的口罩。这是因为 Google Cloud 使 Etsy 能够实施更复杂的机器学习,并能够实时地重新训练算法。另一个例子是他们的数据库管理从数据中心迁移到了云端。具体来说,在备份方面,Etsy 的灾难恢复能力在云端得到了提升,因为他们利用了块存储快照来恢复数据库。这使他们能够快速恢复,充满信心并能够快速测试,不像以前的方法,恢复需要几个小时,而且无法完美地扩展。
Etsy 进行广泛的负载和性能测试。他们使用混沌工程技术,有一个“规模日”,在最大容量下对系统进行压力测试。疫情过后,负载增加不再是峰值,而是日常平均水平。负载测试架构和技术需要与任何其他系统一样可扩展,才能应对增长。
不断改进平台
Etsy 的下一个重点领域之一是为工程师创建“铺好的道路”。一套建议的方法和工具,以减少在启动和开发服务时的摩擦。在云迁移的前四年,他们决定采用一种非常分散的策略。他们采用了 Peter Seibel 在其关于 Twitter 工程效率 的文章中描述的“让 1000 朵花盛开”的方法。这些系统以前从未在云端存在过。他们不知道回报会是什么,并希望最大限度地提高在云端发现价值的机会。
因此,一些产品团队在重新发明轮子,因为 Etsy 没有现有的实施模式和服务。现在,他们拥有了更多在云端运营的经验,平台团队知道差距在哪里,并且可以看到需要哪些工具。
为了确定投资是否有效。Etsy 正在跟踪各种指标。例如,他们监控与系统可靠性、可调试性和可用性相关的 SLI/SLO 趋势。另一个关键指标是生产时间 - 新工程师设置好环境并进行第一次更改所需的时间。这在不同的领域有不同的含义;例如,可能是第一个网站推送或第一个在大数据平台上运行的数据管道。以前需要 2 个小时的事情现在只需要 20 分钟。
他们将这些定量指标与定期衡量工程满意度相结合,使用一种类似于 NPS 调查的形式来评估工程师在各自的工程环境中工作的满意度,并提供机会指出问题并提出改进建议。另一个有趣的统计数据是,基础设施已经扩展到使用 10 倍的节点数量,但只需要 2 倍的人员来管理它们。
衡量成本和碳排放
Etsy 继续拥抱一切可测量的东西。迁移到云端使团队更容易识别和跟踪他们的运营成本,比在数据中心更容易。Etsy 在 Google Cloud 之上构建了工具,提供仪表板,可以洞察支出情况,帮助团队了解哪些功能导致成本上升。仪表板包含丰富的上下文信息,帮助他们根据对理想效率的理解做出优化决策。
可持续发展是公司非常重要的支柱。Etsy 在其季度 SEC 文件中报告了其能源消耗,并承诺减少能源消耗。他们一直在测量数据中心的能源消耗,但在云端尝试这样做最初比较困难。Etsy 的一个团队研究并创建了 Cloud Jewels,一个能源估算工具,他们将其开源。
我们无法衡量我们 2025 年关键影响目标的进展 - 将我们的能源强度降低 25%。云提供商通常不会向客户披露其服务的能源消耗量。为了弥补这些数据的缺乏,我们创建了一组称为 Cloud Jewels 的转换系数,帮助我们大致将我们的云使用信息(如 Google Cloud 使用数据)转换为近似使用的能源。我们很自豪我们的工作和 方法 被 Google 和 AWS 利用,并将其构建到他们自己的模型和工具中。
-- Emily Sommer (Etsy 可持续发展架构师)
这些指标最近被添加到他们的产品仪表板中,允许产品经理和工程师找到减少能源消耗的机会,并发现新功能是否产生了任何影响。Thoughtworks 也有类似的可持续发展使命,他们还创建了一个名为 Cloud Carbon Footprint 的开源工具,该工具的灵感来自对 Cloud Jewels 的初步研究,并由 Thoughtworks 内部团队进一步开发。
致谢
感谢 Martin Fowler、Christopher Hastings 和 Melissa Newman 的写作帮助,以及 Dale Peakskill、Kyle Gallatin、Emily Sommer 和 Rob Miles 分享他们扩展工作的经验。
特别感谢 Mike Fisher 对 Etsy 扩展之旅的坦诚分享。
重大修订
2022 年 11 月 29 日:发布了文章的剩余部分
2022 年 11 月 22 日:发布了关于可观察性和 ML 平台的部分
2022 年 11 月 17 日:发布了第一部分