
提前读取推导
2009 年 2 月 10 日

我在 QCon 旧金山 参加的一个有趣的演讲是 Greg Young 关于他在最近一个系统中使用的特定架构的演讲。Greg 是 领域驱动设计 的忠实粉丝,在这种情况下,它需要与必须处理高交易量并向大量用户提供数据的系统一起使用。我发现他的设计中有很多有趣的地方,特别是他的 事件溯源 的使用,但在这篇文章中,我只想讨论其中一个方面——我称之为提前读取推导。
当我们使用领域模型时,我们使用它是因为它包含复杂的领域逻辑。将这种领域逻辑分类为以下几类可能会有所帮助:
- 验证:检查输入是否有意义,以及对象是否适合进一步操作。
- 后果:启动一些将改变世界状态的操作。
- 推导:根据我们已经拥有的信息推断出一些信息。
这些类型的领域逻辑对更新和读取的应用方式不同。假设我们有一个家谱系统。我们收到一个更新,这是一个出生记录。
name: Bilbo Baggins
father: Bungo Baggins
mother: Belladonna Took
当我们提交此数据时,我们的领域模型将进行一些验证(父亲与母亲不同)。它可能会执行一些后果(Bungo 有一个未支付的遗赠,Bilbo 有权获得)。它也可能进行一些推导,但通常只是为了支持验证或后果(我们需要一个 Bilbo 祖先的列表来验证我们的家谱中没有循环)。
当我们读取数据时,通常只有推导逻辑会起作用。假设我们有一个请求来显示 Bilbo 的父亲的父亲。这需要一些领域逻辑——知道父亲的父亲是父亲的父亲。在大多数系统中,我们在收到读取请求时运行此读取推导逻辑。本质上,我们收到读取请求,调用数据库提取原始数据,运行任何必要的推导逻辑,然后返回结果(尽管缓存可能会发挥作用以减少此操作)。
提前读取推导做了一些完全不同的事情。在这里,读取根本不接触主数据库。相反,我们有一个或多个 报表数据库,它们的结构与我们的读取请求相同。任何读取请求都直接转到报表数据库,报表数据库直接读取数据并将其推送到没有领域逻辑参与的情况下。
让我用出生记录的例子和这个图再解释一下。
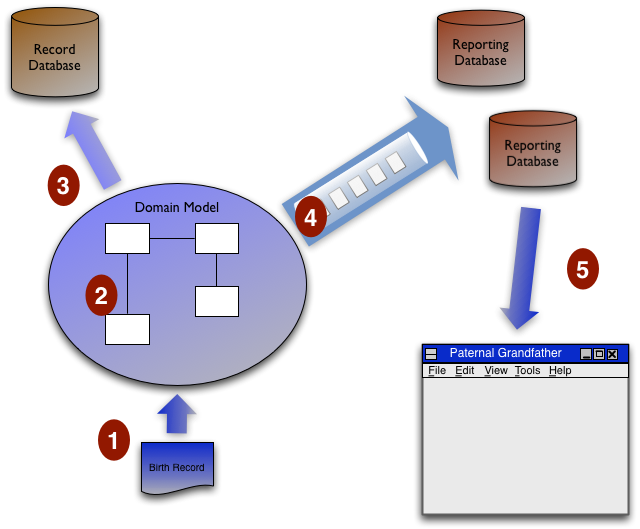
- 我们收到来自 UI 的出生记录。
- 领域模型运行所有验证和后果逻辑。
- 领域模型将核心信息更新到记录数据库。
- 领域模型运行所有读取(包括每个 UI 显示)所需的推导逻辑,并将更新消息发布到消息队列以填充报表数据库。每个报表数据库从这些消息中选择它需要的数据来更新其数据。
- 来自父亲的父亲 UI 的读取请求进来,并通过直接从报表数据库中的父亲的父亲表中读取来满足。
在 Greg 的例子中,所有这些都是通过异步消息完成的,所有输入都被捕获为事件 (事件溯源),领域模型从输入队列中处理消息并将输出事件发布到输出队列以加载报表数据库。异步执行所有这些操作有助于提高整体性能和可扩展性。但这确实意味着存在一个不一致窗口,您可能进行更新,立即进行读取,并且看不到更新的结果,因为您单击的速度比消息处理速度快。这种异步方案是最终一致的,但不是强一致的。但这是事物的本质:在分布式系统中,您可以获得 一致性或可用性,但不能同时获得两者。
现在,您可以在非分布式、强一致的方式下进行提前读取推导。我一时想不出我见过这种情况的例子。我认为提前读取推导在您处理高需求分布式情况时变得更有吸引力。
进行提前评估并不新鲜。这种技术比我还要古老(可能甚至比 Ron Jeffries 还要古老),大多数高流量网站一直在用派生数据填充数据库。但这并不是我经常看到人们考虑的技术,我喜欢 Greg 在他的设计中积极使用它。