
重构模块依赖
随着程序规模的增长,将程序拆分为模块非常重要,这样你就不需要理解所有代码才能进行小的修改。通常这些模块可以由不同的团队提供并动态组合。在这篇重构文章中,我使用表示层-领域层-数据层将一个小程序拆分。然后我重构了这些模块之间的依赖关系,引入了服务定位器和依赖注入模式。这些模式适用于不同的语言,但看起来不同,因此我在 Java 和无类 JavaScript 风格中都展示了这些重构。
2015 年 10 月 13 日

当程序的代码行数超过几百行时,你需要考虑如何将它们拆分为模块。至少,将代码拆分为更小的文件有助于更好地管理编辑。但更重要的是,你需要将程序划分,以便在进行更改时不必将所有代码都记在脑海中。
一个设计良好的模块化结构应该允许你只理解一个大型程序中的一小部分,以便在需要对它进行小的更改时。有时,小的更改会跨越模块,但大多数情况下,你只需要理解单个模块及其邻居。
将程序拆分为模块最难的部分是决定模块边界应该在哪里。没有简单的准则可以遵循,事实上,我一生工作的主要主题是试图理解好的模块边界是什么样子。也许绘制好的模块边界最重要的部分是关注你所做的更改,并重构你的代码,以便一起更改的代码位于相同或附近的模块中。
除此之外,还有如何使各个部分相互关联的机制。在最简单的情况下,你有调用供应商的客户端模块。但通常,这些客户端和供应商的配置会变得很复杂,因为你并不总是希望客户端程序了解其供应商如何组合在一起的太多信息。
我将通过一个例子来探讨这个问题,在这个例子中,我将取一段代码,看看它如何被拆分为多个部分。事实上,我将使用两种不同的语言来做两次:Java 和 JavaScript,尽管它们的名字相似,但在模块化的功能方面却截然不同。
起点
我们从一家进行复杂销售数据分析的初创公司开始。他们有一个宝贵的指标,即冈多夫数,它是一个非常有用的销售预测指标。他们的 Web 应用程序获取公司的销售数据,将其输入到他们复杂的算法中,然后打印一个简单的产品及其冈多夫数的表格。
初始状态的代码都在一个文件中,我将分段介绍它。首先是生成 HTML 表格的代码。
app.js
function emitGondorff(products) {
function line(product) {
return [
` <tr>`,
` <td>${product}</td>`,
` <td>${gondorffNumber(product).toFixed(2)}</td>`,
` </tr>`].join('\n');
}
return encodeForHtml(`<table>\n${products.map(line).join('\n')}\n</table>`);
}
我不使用多行字符串,因为输出中的缩进要求与源代码中的缩进不一致。
这不是世界上最复杂的 UI,在单页面和响应式 UI 的世界中,它简直是平淡无奇。对于这个例子来说,唯一重要的是 UI 需要在不同的点调用 gondorffNumber 函数。
接下来,我将转向冈多夫数的计算。
app.js
function gondorffNumber(product) {
return salesDataFor(product, gondorffEpoch(product), hookerExpiry())
.find(r => r.date.match(/01$/))
.quantity * Math.PI
;
}
function gondorffEpoch(product) {
const countingBase = recordCounts(baselineRange(product));
return deriveEpoch(countingBase);
}
function baselineRange(product){
// redacted
}
function deriveEpoch(countingBase) {
// redacted
}
function hookerExpiry() {
// redacted
}
对我们来说,这可能不像一个百万美元的算法,但幸运的是,这不是这段代码中最重要的部分。重要的是,这段关于计算冈多夫数的逻辑需要两个函数(salesDataFor 和 recordCounts),它们只是从某种销售数据源返回基本数据。这些数据源函数并不特别复杂,它们只是过滤从 CSV 文件中获取的一些数据。
app.js
function salesDataFor(product, start, end) {
return salesData()
.filter(r =>
(r.product === product)
&& (new Date(r.date) >= start)
&& (new Date(r.date) < end)
);
}
function recordCounts(start) {
return salesData()
.filter(r => new Date(r.date) >= start)
.length
}
function salesData() {
const data = readFileSync('sales.csv', {encoding: 'utf8'});
return data
.split('\n')
.slice(1)
.map(makeRecord)
;
}
function makeRecord(line) {
const [product,date,quantityString,location] = line.split(/\s*,\s*/);
const quantity = parseInt(quantityString, 10);
return { product, date, quantity, location };
}
就本次讨论而言,这些函数完全是无聊的 - 我之所以展示它们,只是出于完整性的考虑。关于它们重要的是,它们从某个数据源获取数据,将其整理成简单的对象,并以两种不同的形式提供给核心算法代码。
此时,Java 版本看起来非常相似,首先是 HTML 生成。
class App...
public String emitGondorff(List<String> products) {
List<String> result = new ArrayList<>();
result.add("\n<table>");
for (String p : products)
result.add(String.format(" <tr><td>%s</td><td>%4.2f</td></tr>", p, gondorffNumber(p)));
result.add("</table>");
return HtmlUtils.encode(result.stream().collect(Collectors.joining("\n")));
}
冈多夫算法
class App...
public double gondorffNumber(String product) {
return salesDataFor(product, gondorffEpoch(product), hookerExpiry())
.filter(r -> r.getDate().toString().matches(".*01$"))
.findFirst()
.get()
.getQuantity() * Math.PI
;
}
private LocalDate gondorffEpoch(String product) {
final long countingBase = recordCounts(baselineRange(product));
return deriveEpoch(countingBase);
}
private LocalDate baselineRange(String product) {
//redacted
}
private LocalDate deriveEpoch(long base) {
//redacted
}
private LocalDate hookerExpiry() {
// yup, redacted too
}
由于数据源代码的主体并不重要,我将只展示方法声明
class App
private Stream<SalesRecord> salesDataFor(String product, LocalDate start, LocalDate end) {
// unimportant details
}
private long recordCounts(LocalDate start) {
// unimportant details
}
表示层-领域层-数据层
我之前说过,设置模块边界是一门微妙而细致的艺术,但许多人遵循的一条准则是 表示层-领域层-数据层 - 将表示代码(UI)、业务逻辑和数据访问分离。遵循这种拆分有充分的理由。这三个类别中的每一个都涉及思考不同的问题,并且通常使用不同的框架来帮助完成任务。此外,人们还希望进行替换 - 多个表示使用相同的核心业务逻辑,或者业务逻辑在不同的环境中使用不同的数据源。
因此,对于这个例子,我将遵循这种常见的拆分,并且我还将强调替换的理由。毕竟,这个冈多夫数是一个如此有价值的指标,以至于许多人会想要使用它 - 这促使我将其打包成一个可以轻松地被多个应用程序重用的单元。此外,并非所有应用程序都将销售数据保存在 CSV 文件中,有些应用程序会使用数据库或远程微服务。我们希望应用程序开发人员能够获取冈多夫代码并将其插入到她特定的数据源中,她可以自己编写这个数据源,也可以从另一个开发人员那里获取。
但在我们开始进行重构以实现所有这些之前,我确实需要强调,表示层-领域层-数据层确实有其局限性。模块化的普遍规则是,如果可以,我们希望将更改的后果限制在一个模块中。但是,单独的表示层-领域层-数据层模块通常必须一起更改。添加数据字段的简单操作通常会导致所有三个模块都更新。因此,我更倾向于在较小的范围内使用这种方法,但较大的应用程序需要沿着不同的路线开发高级模块。特别是,你不应该使用表示层-领域层-数据层作为团队边界的依据。
执行拆分
我将从分离表示层开始拆分模块。对于 JavaScript 来说,这几乎只是将代码剪切粘贴到一个新文件中。
gondorff.es6
export default function gondorffNumber …
function gondorffEpoch(product) {…
function baselineRange(product){…
function deriveEpoch(countingBase) { …
function hookerExpiry() { …
function salesDataFor(product, start, end) { …
function recordCounts(start) { …
function salesData() { …
function makeRecord(line) { …
通过使用 export default,我可以导入对 gondorffNumber 的引用,并且我只需要添加一个导入语句。
app.es6
import gondorffNumber from './gondorff.es6'
在 Java 方面,它几乎同样简单。同样,我将除了 emitGondorff 之外的所有内容复制到一个新类中。
class Gondorff…
public double gondorffNumber(String product) { …
private LocalDate gondorffEpoch(String product) { …
private LocalDate baselineRange(String product) { …
private LocalDate deriveEpoch(long base) { …
private LocalDate hookerExpiry() { …
Stream<SalesRecord> salesDataFor(String product, LocalDate start, LocalDate end) { …
long recordCounts(LocalDate start) {…
Stream<SalesRecord> salesData() { …
private SalesRecord makeSalesRecord(String line) { …
对于原始的 App 类,除非我将新类放入一个新的包中,否则我不需要导入,但我需要实例化新类。
class App...
public String emitGondorff(List<String> products) {
List<String> result = new ArrayList<>();
result.add("\n<table>");
for (String p : products)
result.add(String.format(" <tr><td>%s</td><td>%4.2f</td></tr>", p, new Gondorff().gondorffNumber(p)));
result.add("</table>");
return HtmlUtils.encode(result.stream().collect(Collectors.joining("\n")));
}
现在我想进行第二次分离,将计算逻辑与提供数据记录的代码分离。
dataSource.es6…
export function salesDataFor(product, start, end) {
export function recordCounts(start) {
function salesData() { …
function makeRecord(line) { …
此移动与之前移动的区别在于,gondorff 文件需要导入两个函数,而不仅仅是一个函数。它可以使用此导入来完成,其他任何内容都不需要更改。
Gondorff.es6…
import {salesDataFor, recordCounts} from './dataSource.es6'
Java 版本与之前的情况非常相似,移动到一个新类中,并为一个新对象实例化该类。
class DataSource…
public Stream<SalesRecord> salesDataFor(String product, LocalDate start, LocalDate end) { …
public long recordCounts(LocalDate start) {…
Stream<SalesRecord> salesData() { …
private SalesRecord makeSalesRecord(String line) { …
class Gondorff...
public double gondorffNumber(String product) {
return new DataSource().salesDataFor(product, gondorffEpoch(product), hookerExpiry())
.filter(r -> r.getDate().toString().matches(".*01$"))
.findFirst()
.get()
.getQuantity() * Math.PI
;
}
private LocalDate gondorffEpoch(String product) {
final long countingBase = new DataSource().recordCounts(baselineRange(product));
return deriveEpoch(countingBase);
}
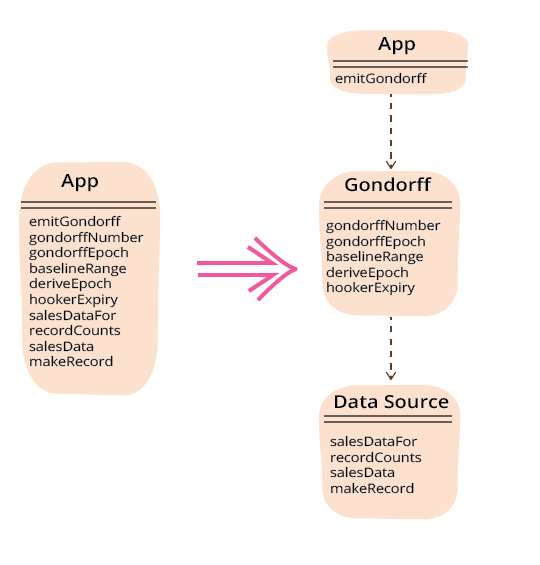
这种将代码拆分为多个模块的过程是机械的,并不真正有趣。但这是在进行有趣的重构之前必须采取的必要步骤。
链接器替换
将代码拆分为多个模块很有帮助,但所有这些中最有趣的困难是希望将冈多夫计算作为单独的组件进行分发。目前,冈多夫计算假设销售数据来自具有特定路径的 CSV 文件。分离数据源逻辑让我可以改变这一点,但目前我拥有的机制很笨拙,还有其他选择可以探索。
那么,目前的机制是什么呢?本质上,这就是我所说的链接器替换。术语“链接器”有点像对 C 这样的编译程序的回归,在编译程序中,链接阶段会解析跨不同编译单元的符号。在 JavaScript 中,我可以通过操作导入命令的文件查找路径来实现与之类似的效果。
假设我想将此应用程序安装在一个环境中,在这个环境中,他们不将销售记录保存在 CSV 文件中,而是对 SQL 数据库运行查询。为了使它工作,我首先需要创建一个 CorporateDatabaseDataSource 文件,其中包含用于 salesDataFor 和 recordCounts 的导出函数,这些函数以冈多夫文件期望的形式返回数据。然后,我用这个新文件替换 DataSource 文件。然后,当我运行应用程序时,它会“链接”到替换的 DataSource 文件。
对于许多依赖于某种路径查找机制进行链接的动态语言来说,链接器替换是一种非常不错的简单组件替换技术。除了我刚刚完成的将代码简单地拆分为文件之外,我不需要对代码做任何事情来使其工作。如果我有一个构建脚本,我可以通过简单地将不同的文件复制到路径中的适当位置来构建针对不同数据源环境的代码。这说明了将程序分解成小块的优势 - 它允许替换这些块,即使最初的编写者没有想到任何替换。它使意想不到的定制成为可能。
在 Java 中进行链接器替换本质上是相同的任务。我需要将 DataSource 打包到一个与 Gondorff 分开的 jar 文件中,然后指示 Gondorff 的用户创建一个名为 DataSource 的类,该类具有适当的方法,并将其放在类路径上。
但是,在 Java 中,我会执行一个额外的步骤,对数据源应用 提取接口。
public interface DataSource {
Stream<SalesRecord> salesDataFor(String product, LocalDate start, LocalDate end);
long recordCounts(LocalDate start);
}
public class CsvDataSource implements DataSource {
使用这样的 必需接口 很有帮助,因为它明确地说明了冈多夫从其数据源期望哪些函数。
动态语言的一个缺点是它们缺乏这种显式性,这在组合单独开发的组件时可能会成为问题。JavaScript 的模块系统在这里很有效,因为它静态地定义了模块依赖关系,因此它们是显式的,可以静态地检查。静态声明有成本和收益,最近语言设计中一个不错的进展是尝试对静态声明采用更细致入微的方法,而不是仅仅将语言视为纯粹的静态或动态语言。
链接器替换的优点是它对组件作者的要求很少,因此适合于不可预见的自定义。但它也有缺点。在某些环境中,例如 Java,它可能很难使用。代码没有揭示替换的工作原理,因此没有机制在代码库中控制替换。
这种在代码中缺乏存在感的一个重要后果是,替换不能动态发生——也就是说,一旦程序被组装并运行,我就无法更改数据源。这在生产中通常不是什么大问题,在某些情况下热交换数据源很有用,但它们只是少数情况。但动态替换的价值在于测试。使用测试替身来提供罐装数据进行测试非常常见,这通常意味着我需要为不同的测试用例投入不同的替身。
对代码库中更高显式性和测试中动态替换的需求,通常会让我们探索其他替代方案,这些方案允许我们明确指定组件的连接方式,而不是仅仅依赖路径查找。
每次调用时将数据源作为参数
如果我们想支持使用不同的数据源调用 gondorff,那么一个显而易见的方法是在每次调用它时将数据源作为参数传递。
让我们先看看这在 Java 版本中可能是什么样子,从 Java 版本的当前状态开始,在提取 DataSource 接口之后。
class App...
public String emitGondorff(List<String> products) {
List<String> result = new ArrayList<>();
result.add("\n<table>");
for (String p : products)
result.add(String.format(
" <tr><td>%s</td><td>%4.2f</td></tr>",
p,
new Gondorff().gondorffNumber(p)
));
result.add("</table>");
return HtmlUtils.encode(result.stream().collect(Collectors.joining("\n")));
}
class Gondorff...
public double gondorffNumber(String product) {
return new CsvDataSource().salesDataFor(product, gondorffEpoch(product), hookerExpiry())
.filter(r -> r.getDate().toString().matches(".*01$"))
.findFirst()
.get()
.getQuantity() * Math.PI
;
}
private LocalDate gondorffEpoch(String product) {
final long countingBase = new CsvDataSource().recordCounts(baselineRange(product));
return deriveEpoch(countingBase);
}
要将数据源作为参数传递,生成的代码如下所示。
class App...
public String emitGondorff(List<String> products) {
List<String> result = new ArrayList<>();
result.add("\n<table>");
for (String p : products)
result.add(String.format(
" <tr><td>%s</td><td>%4.2f</td></tr>",
p,
new Gondorff().gondorffNumber(p, new CsvDataSource())
));
result.add("</table>");
return HtmlUtils.encode(result.stream().collect(Collectors.joining("\n")));
}
class Gondorff...
public double gondorffNumber(String product, DataSource dataSource) { return dataSource.salesDataFor(product, gondorffEpoch(product, dataSource), hookerExpiry()) .filter(r -> r.getDate().toString().matches(".*01$")) .findFirst() .get() .getQuantity() * Math.PI ; } private LocalDate gondorffEpoch(String product, DataSource dataSource) { final long countingBase = dataSource.recordCounts(baselineRange(product)); return deriveEpoch(countingBase); }
我可以通过几个小步骤完成这个重构。
- 在
gondorffEpoch上使用添加参数来添加dataSource - 替换对
new CsvDataSource()的调用以使用刚刚添加的dataSource参数 - 编译并测试
- 对
gondorffNumber重复此操作
现在转到 JavaScript 版本,这里再次是当前状态。
app.es6…
import gondorffNumber from './gondorff.es6'
function emitGondorff(products) {
function line(product) {
return [
` <tr>`,
` <td>${product}</td>`,
` <td>${gondorffNumber(product).toFixed(2)}</td>`,
` </tr>`].join('\n');
}
return encodeForHtml(`<table>\n${products.map(line).join('\n')}\n</table>`);
}
Gondorff.es6…
import {salesDataFor, recordCounts} from './dataSource.es6'
export default function gondorffNumber(product) {
return salesDataFor(product, gondorffEpoch(product), hookerExpiry())
.find(r => r.date.match(/01$/))
.quantity * Math.PI
;
}
function gondorffEpoch(product) {
const countingBase = recordCounts(baselineRange(product));
return deriveEpoch(countingBase);
}
在这种情况下,我可以将两个函数都作为参数传递
app.es6…
import gondorffNumber from './gondorff.es6'
import * as dataSource from './dataSource.es6'
function emitGondorff(products) {
function line(product) {
return [
` <tr>`,
` <td>${product}</td>`,
` <td>${gondorffNumber(product, dataSource.salesDataFor, dataSource.recordCounts).toFixed(2)}</td>`,
` </tr>`].join('\n');
}
return encodeForHtml(`<table>\n${products.map(line).join('\n')}\n</table>`);
}
Gondorff.es6…
import {salesDataFor, recordCounts} from './dataSource.es6' export default function gondorffNumber(product, salesDataFor, recordCounts) { return salesDataFor(product, gondorffEpoch(product, recordCounts), hookerExpiry()) .find(r => r.date.match(/01$/)) .quantity * Math.PI ; } function gondorffEpoch(product, recordCounts) { const countingBase = recordCounts(baselineRange(product)); return deriveEpoch(countingBase); }
与 Java 示例一样,我可以先对 gondorffEpoch 应用添加参数,编译并测试,然后对每个函数的 gondoffNumber 做同样的事情。
在这种情况下,我倾向于将 salesDataFor 和 recordCounts 函数都放到一个数据源对象上,然后将其传递进去——本质上是使用引入参数对象。我不会在本文中这样做,主要是因为如果我不这样做,它将更好地演示操作一等函数。但如果 gondorff 需要从数据源中使用更多函数,我会这样做。
参数化数据源文件名
作为进一步的步骤,我可以参数化数据源的文件名。对于 Java 版本,我通过在数据源中添加一个用于文件名的字段并使用添加参数来完成此操作。
class CsvDataSource…
private String filename;
public CsvDataSource(String filename) {
this.filename = filename;
}
class App…
public String emitGondorff(List<String> products) {
DataSource dataSource = new CsvDataSource("sales.csv");
List<String> result = new ArrayList<>();
result.add("\n<table>");
for (String p : products)
result.add(String.format(
" <tr><td>%s</td><td>%4.2f</td></tr>",
p,
new Gondorff().gondorffNumber(p, dataSource)
));
result.add("</table>");
return HtmlUtils.encode(result.stream().collect(Collectors.joining("\n")));
}
对于 JavaScript 版本,我需要在数据源上需要它的函数上使用添加参数。
dataSource.es6…
export function salesDataFor(product, start, end, filename) { return salesData(filename) .filter(r => (r.product === product) && (new Date(r.date) >= start) && (new Date(r.date) < end) ); } export function recordCounts(start, filename) { return salesData(filename) .filter(r => new Date(r.date) >= start) .length }
按原样,这将迫使我将文件名参数放入 gondorff 函数中,但实际上它们不应该知道任何关于它的信息。我可以通过创建一个简单的适配器来解决这个问题。
dataSourceAdapter.es6…
import * as ds from './dataSource.es6'
export default function(filename) {
return {
salesDataFor(product, start, end) {return ds.salesDataFor(product, start, end, filename)},
recordCounts(start) {return ds.recordCounts(start, filename)}
}
}
应用程序代码在将数据源传递到 gondorff 函数时使用此适配器。
app.es6…
import gondorffNumber from './gondorff.es6' import * as dataSource from './dataSource.es6' import createDataSource from './dataSourceAdapter.es6'
function emitGondorff(products) {
function line(product) {
const dataSource = createDataSource('sales.csv');
return [
` <tr>`,
` <td>${product}</td>`,
` <td>${gondorffNumber(product, dataSource.salesDataFor, dataSource.recordCounts).toFixed(2)}</td>`,
` </tr>`].join('\n');
}
return encodeForHtml(`<table>\n${products.map(line).join('\n')}\n</table>`);
}
参数化的权衡
在每次调用 gondorff 时传入数据源,可以让我获得我想要的动态替换。作为应用程序开发人员,我可以使用任何我喜欢的数据库,我也可以通过在需要时传入存根数据库来轻松地进行测试。
但使用每次调用都带有参数的方法也有缺点。首先,我必须将数据源(或其函数)作为参数传递给 gondorff 中的每个函数,这些函数要么需要它,要么调用另一个需要它的函数。这会导致数据源成为到处游荡的 tramp 数据。
更严重的问题是,现在每次我有一个使用 gondorff 的应用程序模块时,我必须确保我也可以创建和配置数据源。如果我有一个更复杂的配置,并且有一个需要多个必需组件的通用组件,每个组件都有自己的一组必需组件,那么这很容易变得混乱。每次我使用 gondorff 时,我必须将关于如何配置 gondorff 对象的知识嵌入其中。这是一种重复,它使代码变得更难理解和使用。
我可以通过查看依赖关系来可视化这一点。在将数据源作为参数引入之前,依赖关系看起来像这样

当我将数据源作为参数传递时,它看起来像这样。
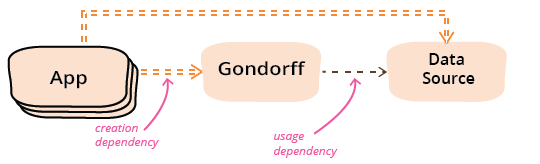
在这些图中,我区分了使用依赖关系和创建依赖关系。使用依赖关系意味着客户端模块调用供应商上定义的函数。gondorff 和数据源之间始终存在使用依赖关系。创建依赖关系是一种更紧密的依赖关系,因为您通常需要了解有关供应商模块的更多信息才能配置和创建它。(创建依赖关系意味着使用依赖关系。)使用每次调用都带有参数的方法将 gondorff 的依赖关系从创建降低到使用,但引入了任何应用程序的创建依赖关系。
除了创建依赖关系问题之外,还有一个问题,因为我实际上并不想在生产代码中更改数据源。每次调用 gondorff 时传递参数意味着我在调用之间更改参数,但在这里,每当我调用 gondorffNumber 时,我始终传递完全相同的数据源。这种不和谐可能会在六个月后让我感到困惑。
如果我始终对数据源使用相同的配置,那么有意义的是将其设置一次,并在每次使用它时引用它。但如果我这样做,我也可以将 gondorff 设置一次,并在每次想要使用它时使用一个完全配置的 gondorff。
因此,在探索了每次使用参数的实现方式之后,我将利用我的版本控制系统并进行硬重置,回到本节开始时的位置,以便我可以探索另一条路径。
单一服务
gondorff 和 dataSource 的一个重要属性是它们都可以充当单一服务对象。服务对象是埃文斯分类的一部分,指的是面向活动的对象,而不是面向数据的实体或值。我通常将服务对象称为“服务”,但它们与 SOA 中的服务不同,因为它们不是网络可访问的组件。在函数式世界中,服务通常只是函数,但有时您确实会遇到想要将一组函数视为单个事物的情况。我们在数据源中看到了这一点,我们在数据源中拥有两个函数,我可以将它们视为单个数据源的一部分。
我还说“单一”,我的意思是,在整个执行上下文中只有一个这样的对象是有概念意义的。由于服务通常是无状态的,因此只有一个服务是有意义的。如果某件事在执行上下文中是单一的,则意味着我们可以在程序中全局引用它。我们甚至可能想强制它成为单例,也许是因为设置它很昂贵,或者因为它正在操作的资源存在并发约束。在整个运行的进程中可能只有一个,或者可能有多个,例如每个线程使用线程特定存储一个。但无论哪种方式,就我们的代码而言,只有一个。
如果我们选择将我们的 gondorff 计算器和数据源设为单一服务,那么在应用程序启动期间将它们配置一次,然后在以后使用它们时引用它们是有意义的。
这在服务处理方式上引入了一种分离:配置和使用的分离。我可以通过几种方式重构此代码来实现这种分离:引入服务定位器模式或依赖注入模式。我将从服务定位器开始。
引入服务定位器
服务定位器模式背后的理念是为组件提供一个单一的定位服务的点。定位器是服务的注册表。在使用中,客户端使用全局查找来查找注册表,然后向注册表请求特定服务。配置使用所有需要的服务来设置定位器。
引入它的重构的第一步是创建定位器。它是一个非常简单的结构,仅仅是一个全局记录,所以我的 JavaScript 版本只是一些变量和一个简单的初始化器。
serviceLocator.es6…
export let salesDataFor;
export let recordCounts;
export let gondorffNumber;
export function initialize(arg) {
salesDataFor: arg.salesDataFor;
recordCounts: arg.recordCounts;
gondorffNumber = arg.gondorffNumber;
}
export let 将变量导出到其他模块作为只读视图。[1]
Java 版本当然要冗长一些。
class ServiceLocator…
private static ServiceLocator soleInstance;
private DataSource dataSource;
private Gondorff gondorff;
public static DataSource dataSource() {
return soleInstance.dataSource;
}
public static Gondorff gondorff() {
return soleInstance.gondorff;
}
public static void initialize(ServiceLocator arg) {
soleInstance = arg;
}
public ServiceLocator(DataSource dataSource, Gondorff gondorff) {
this.dataSource = dataSource;
this.gondorff = gondorff;
}
在这种情况下,我更喜欢提供一个静态方法接口,这样定位器的客户端就不需要知道数据存储在哪里。但我喜欢对数据使用单例实例,因为这使得测试更容易替换。
在这两种情况下,服务定位器都是一组属性。
重构 JavaScript 以使用定位器
定义了定位器后,下一步是开始将服务移到定位器上,我从 gondorff 开始。为了配置服务定位器,我将编写一个小型模块来配置服务定位器。
configureServices.es6…
import * as locator from './serviceLocator.es6';
import gondorffImpl from './gondorff.es6';
export default function() {
locator.initialize({gondorffNumber: gondorffImpl});
}
我需要确保此函数在应用程序启动时被导入并调用。
一些启动文件…
import initializeServices from './configureServices.es6';
initializeServices();
为了刷新我们的记忆,以下是当前的应用程序代码(在之前的还原之后)。
app.es6…
import gondorffNumber from './gondorff.es6'
function emitGondorff(products) {
function line(product) {
return [
` <tr>`,
` <td>${product}</td>`,
` <td>${gondorffNumber(product).toFixed(2)}</td>`,
` </tr>`].join('\n');
}
return encodeForHtml(`<table>\n${products.map(line).join('\n')}\n</table>`);
}
要使用服务定位器,我只需要调整导入语句。
app.es6…
import gondorffNumber from './gondorff.es6' import {gondorffNumber} from './serviceLocator.es6';
我可以只进行此更改来运行测试,以确保我没有弄乱它(这听起来比“找出我如何弄乱它”更好)。完成此更改后,我对数据源进行类似的更改。
configureServices.es6…
import * as locator from './serviceLocator.es6'; import gondorffImpl from './gondorff.es6'; import * as dataSource from './dataSource.es6' ; export default function() { locator.initialize({ salesDataFor: dataSource.salesDataFor, recordCounts: dataSource.recordCounts, gondorffNumber: gondorffImpl }); }
Gondorff.es6…
import {salesDataFor, recordCounts} from './serviceLocator.es6'
我可以使用与之前相同的重构来参数化文件名,这次更改只影响服务配置函数。
configureServices.es6…
import * as locator from './serviceLocator.es6'; import gondorffImpl from './gondorff.es6'; import * as dataSource from './dataSource.es6' ; import createDataSource from './dataSourceAdapter.es6' export default function() { const dataSource = createDataSource('sales.csv'); locator.initialize({ salesDataFor: dataSource.salesDataFor, recordCounts: dataSource.recordCounts, gondorffNumber: gondorffImpl }); }
dataSourceAdapter.es6…
import * as ds from './dataSource.es6'
export default function(filename) {
return {
salesDataFor(product, start, end) {return ds.salesDataFor(product, start, end, filename)},
recordCounts(start) {return ds.recordCounts(start, filename)}
}
}
Java
Java 案例看起来很相似。我创建一个配置类来填充服务定位器。
class ServiceConfigurator…
public class ServiceConfigurator {
public static void run() {
ServiceLocator locator = new ServiceLocator(null, new Gondorff());
ServiceLocator.initialize(locator);
}
}
并确保我在应用程序启动时调用它。
当前的应用程序代码如下所示
class App…
public String emitGondorff(List<String> products) {
List<String> result = new ArrayList<>();
result.add("\n<table>");
for (String p : products)
result.add(String.format(
" <tr><td>%s</td><td>%4.2f</td></tr>",
p,
new Gondorff().gondorffNumber(p)
));
result.add("</table>");
return HtmlUtils.encode(result.stream().collect(Collectors.joining("\n")));
}
我现在使用定位器来获取 gondorff 对象。
class App…
public String emitGondorff(List<String> products) {
List<String> result = new ArrayList<>();
result.add("\n<table>");
for (String p : products)
result.add(String.format(
" <tr><td>%s</td><td>%4.2f</td></tr>",
p,
ServiceLocator.gondorff().gondorffNumber(p)
));
result.add("</table>");
return HtmlUtils.encode(result.stream().collect(Collectors.joining("\n")));
}
要将数据源对象添加到混合中,我首先将其添加到定位器中。
class ServiceConfigurator…
public class ServiceConfigurator {
public static void run() {
ServiceLocator locator = new ServiceLocator(new CsvDataSource(), new Gondorff());
ServiceLocator.initialize(locator);
}
}
目前 gondorff 对象看起来像这样
class Gondorff…
public double gondorffNumber(String product) {
return new CsvDataSource().salesDataFor(product, gondorffEpoch(product), hookerExpiry())
.filter(r -> r.getDate().toString().matches(".*01$"))
.findFirst()
.get()
.getQuantity() * Math.PI
;
}
private LocalDate gondorffEpoch(String product) {
final long countingBase = new CsvDataSource().recordCounts(baselineRange(product));
return deriveEpoch(countingBase);
}
使用服务定位器会将其更改为
class Gondorff…
public double gondorffNumber(String product) {
return ServiceLocator.dataSource().salesDataFor(product, gondorffEpoch(product), hookerExpiry())
.filter(r -> r.getDate().toString().matches(".*01$"))
.findFirst()
.get()
.getQuantity() * Math.PI
;
}
private LocalDate gondorffEpoch(String product) {
final long countingBase = ServiceLocator.dataSource().recordCounts(baselineRange(product));
return deriveEpoch(countingBase);
}
与 JavaScript 案例一样,参数化文件名只会更改服务配置代码。
class ServiceConfigurator…
public class ServiceConfigurator {
public static void run() {
ServiceLocator locator = new ServiceLocator(new CsvDataSource("sales.csv"), new Gondorff());
ServiceLocator.initialize(locator);
}
}
使用服务定位器的后果
使用服务定位器的直接影响是改变了我们三个组件之间的依赖关系。在简单地划分组件之后,我们可以看到依赖关系看起来像这样。
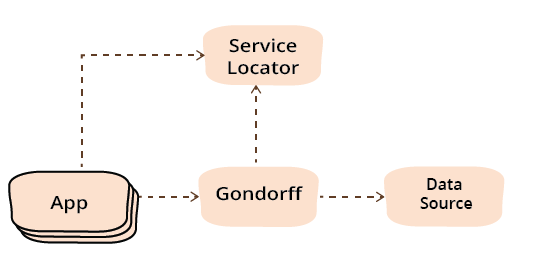
引入服务定位器消除了主模块之间的所有创建依赖关系。[2]。当然,这忽略了配置服务模块,它具有所有创建依赖关系。
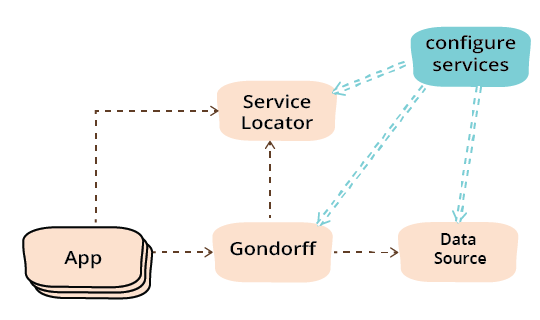
我相信你们中有些人可能已经注意到,应用程序定制是通过服务配置功能完成的,这意味着任何定制都是通过与我之前提到的需要摆脱的链接器替换机制相同的机制完成的。在某种程度上这是正确的,但服务配置模块明显独立的事实给了我更大的灵活性。库提供者可以提供一系列数据源实现,而客户端可以编写一个服务配置模块,该模块将根据配置参数(如配置文件、环境变量或命令行变量)在运行时选择一个。这里有一个潜在的重构,可以从配置文件中引入参数,但我将把它留到以后再做。
但是使用服务定位器的一个特殊结果是,我现在可以轻松地替换服务以进行测试。我可以像这样为 gondorff 的数据源添加一个测试存根
测试…
it('can stub a data source', function() {
const data = [
{product: "p", date: "2015-07-01", quantity: 175}
];
const newLocator = {
recordCounts: () => 500,
salesDataFor: () => data,
gondorffNumber: serviceLocator.gondorffNumber
};
serviceLocator.initialize(newLocator);
assert.closeTo(549.7787, serviceLocator.gondorffNumber("p"), 0.001);
});
类测试者…
@Test
public void can_stub_data_source() throws Exception {
ServiceLocator.initialize(new ServiceLocator(new DataSourceStub(), ServiceLocator.gondorff()));
assertEquals(549.7787, ServiceLocator.gondorff().gondorffNumber("p"), 0.001);
}
private class DataSourceStub implements DataSource {
@Override
public Stream<SalesRecord> salesDataFor(String product, LocalDate start, LocalDate end) {
return Collections.singletonList(new SalesRecord("p", LocalDate.of(2015, 7, 1), 175)).stream();
}
@Override
public long recordCounts(LocalDate start) {
return 500;
}
}
拆分阶段
在我写这篇文章的时候,我去拜访了肯特·贝克。在吃了他的自制奶酪后,我们的谈话转向了重构主题,他告诉我他十年前就认识到一个重要的重构,但从未写成一篇像样的文章。这个重构涉及将一个复杂的计算分成两个阶段,第一个阶段将结果传递给第二个阶段,并使用一些中间结果数据结构。这个模式的一个大规模例子是编译器使用的模式,它们将工作分成多个阶段:标记化、解析、代码生成,使用标记流和解析树等数据结构作为中间结果。
当我回到家,重新开始写这篇文章时,我很快意识到,引入像这样的服务定位器是拆分阶段重构的一个例子。我已经使用服务定位器将服务对象的配置提取到它自己的阶段,并将配置服务阶段的结果作为中间结果传递给程序的其余部分。
将计算像这样分成不同的阶段是一个有用的重构,因为它允许我们分别考虑每个阶段的不同需求,每个阶段的结果都有明确的指示(在中间结果中),并且每个阶段都可以通过检查或提供中间结果来独立测试。当我们将中间结果视为一个不可变的数据结构时,这种重构效果尤其好,它让我们在不考虑早期阶段生成的所有数据的变异行为的情况下,就能使用后期阶段的代码带来的好处。
当我写这篇文章的时候,距离我和肯特的谈话还不到一个月,但我感觉拆分阶段的概念是一个强大的重构工具。就像许多伟大的模式一样,它具有明显的概念——我觉得它只是给一个我几十年来一直在做的事情起了个名字。但这样的名字并非小事,一旦你给一个经常使用的技术起了个名字,它就更容易与他人交流,并改变我自己的思考方式:赋予它更中心的角色,并比无意识地使用它时更加刻意地使用它。
依赖注入
使用服务定位器有一个缺点,即组件对象需要知道服务定位器的工作原理。如果 gondorff 计算器只在使用相同服务定位器机制的易于理解的应用程序范围内使用,这不是问题,但如果我想把它卖出去以发财,这种耦合就是一个问题。即使我所有热切的买家都使用服务定位器,他们也不太可能都使用相同的 API。我需要一种方法来配置 gondorff 和数据源,这种方法不需要除语言本身内置的机制之外的任何其他机制。
这就是导致另一种称为依赖注入的配置形式的需求。依赖注入被广泛宣传,尤其是在 Java 世界,有各种各样的框架来实现它。虽然这些框架可能有用,但基本思想实际上非常简单,我将通过重构这个例子来实现一个简单的实现来说明它。
Java 示例
这个想法的核心是,你应该能够编写像 gondorff 对象这样的组件,而无需了解任何用于配置依赖组件的特殊约定或工具。在 Java 中,这样做最自然的方式是让 gondorff 对象有一个字段来保存数据源。这个字段可以通过服务配置以你填充任何字段的通常方式填充——要么使用 setter,要么在构造期间填充。由于 gondorff 对象需要一个数据源才能执行任何有用的操作,我通常的做法是把它放到构造函数中。
class Gondorff…
private DataSource dataSource; public Gondorff(DataSource dataSource) { this.dataSource = dataSource; } private DataSource getDataSource() { return (dataSource != null) ? dataSource : ServiceLocator.dataSource(); } public double gondorffNumber(String product) { return getDataSource().salesDataFor(product, gondorffEpoch(product), hookerExpiry()) .filter(r -> r.getDate().toString().matches(".*01$")) .findFirst() .get() .getQuantity() * Math.PI ; } private LocalDate gondorffEpoch(String product) { final long countingBase = getDataSource().recordCounts(baselineRange(product)); return deriveEpoch(countingBase); }
class ServiceConfigurator…
public class ServiceConfigurator {
public static void run() {
ServiceLocator locator = new ServiceLocator(new CsvDataSource("sales.csv"), new Gondorff(null));
ServiceLocator.initialize(locator);
}
}
通过添加访问器 getDataSource,我可以以更小的步骤进行重构。这段代码使用服务定位器完成的配置可以正常工作,我可以逐渐用使用这种新的依赖注入机制的测试来替换设置定位器的测试。第一个重构只是添加了字段并应用了 添加参数。调用者最初可以使用带有空参数的构造函数,我可以一次处理一个调用者来提供数据源,并在每次更改后进行测试。(当然,由于我们在配置阶段完成了所有服务配置,因此通常没有多少调用者。我们获得更多调用者的位置是在测试中的存根。)
class ServiceConfigurator…
public class ServiceConfigurator {
public static void run() {
DataSource dataSource = new CsvDataSource("sales.csv");
ServiceLocator locator = new ServiceLocator(dataSource, new Gondorff(dataSource));
ServiceLocator.initialize(locator);
}
}
一旦我完成了所有操作,我就可以从 gondorff 对象中删除所有对服务定位器的引用。
class Gondorff…
private DataSource getDataSource() {
return (dataSource != null) ? dataSource : ServiceLocator.dataSource();
return dataSource;
}
如果我愿意,我也可以内联 getDataSource
JavaScript 示例
由于我在 JavaScript 示例中避免使用类,因此确保 gondorff 计算器获得数据源函数而无需额外框架的一种方法是将它们作为参数传递给每个调用。
Gondorff.es6…
import {recordCounts} from './serviceLocator.es6'
export default function gondorffNumber(product, salesDataFor, recordCounts) {
return salesDataFor(product, gondorffEpoch(product, recordCounts), hookerExpiry())
.find(r => r.date.match(/01$/))
.quantity * Math.PI
;
}
function gondorffEpoch(product, recordCounts) {
const countingBase = recordCounts(baselineRange(product));
return deriveEpoch(countingBase);
}
我之前做过这种方法,但这次需要确保客户端不需要在每次调用时进行任何设置。我可以通过向客户端提供一个部分应用的 gondorff 函数来做到这一点。
configureServices.es6…
import * as locator from './serviceLocator.es6';
import gondorffImpl from './gondorff.es6';
import createDataSource from './dataSourceAdapter.es6'
export default function() {
const dataSource = createDataSource('sales.csv');
locator.initialize({
salesDataFor: dataSource.salesDataFor,
recordCounts: dataSource.recordCounts,
gondorffNumber: (product) => gondorffImpl(product, dataSource.salesDataFor, dataSource.recordCounts)
});
}
后果
如果我们查看使用阶段的依赖关系,图表看起来像这样。
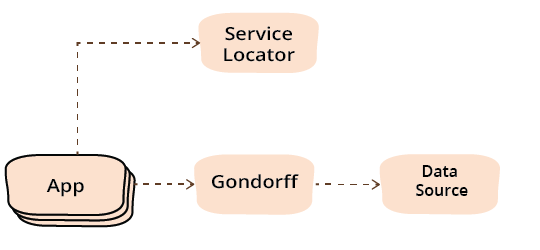
这与之前使用服务定位器的唯一区别是,gondorff 和服务定位器之间不再有任何依赖关系,这就是使用依赖注入的全部目的。(配置阶段的依赖关系是相同的创建依赖关系集。)
一旦我从 gondorff 到服务定位器的依赖关系中删除了依赖关系,如果没有任何其他类需要从服务定位器获取数据源,我也可以完全从服务定位器中删除数据源字段。我也可以使用依赖注入将 gondorff 对象提供给应用程序类,尽管这样做价值不大,因为应用程序类不是共享的,因此不会因为使用定位器而处于不利地位。通常会看到服务定位器和依赖注入模式像这样一起使用,使用服务定位器获取一个初始服务,其进一步配置是通过依赖注入完成的。依赖注入容器通常通过提供查找服务的机制来用作服务定位器。
最后的想法
这个重构事件的关键信息是将服务配置阶段与服务的使用阶段分离。你究竟如何使用服务定位器和依赖注入来执行此操作并不重要,这取决于你所处的具体情况。这些情况可能会让你使用一个打包的框架来管理这些依赖关系,或者如果你的情况很简单,自己编写一个框架也可能没问题。
脚注
2: 人们可能会争辩说,服务定位器的 Java 版本由于在类型签名中提到了 gondorff 和数据源,因此依赖于它们。我在这里不考虑这一点,因为定位器实际上并没有调用这些类上的任何方法。我也可以通过一些类型体操来消除这些静态类型依赖关系,尽管我怀疑这种治疗方法会比疾病更糟糕。
致谢
Pete Hodgson 和 Axel Rauschmayer 在改进我的 JavaScript 方面给了我宝贵的帮助。Ben Wu (伍斌) 建议了一个有用的说明。Jean-Noël Rouvignac 纠正了几个错别字。
重大修订
2015 年 10 月 13 日: 首次发布