

此模式是 "遗留系统置换模式" 的一部分
恢复到源头
识别数据的源头并集成到该源头
2022 年 7 月 7 日
在许多组织中,一旦完成了将新系统集成到大型机中的工作,例如,通过大型机与该系统交互变得容易得多,而不是每次都重复集成。对于许多具有单体架构的遗留系统来说,这样做是有意义的,将同一个系统多次集成到同一个单体中会是浪费的,而且可能会令人困惑。随着时间的推移,其他系统开始访问遗留系统以获取这些数据,而最初的集成系统往往会被“遗忘”。
通常,这会导致遗留系统成为多个系统的单一集成点,因此也成为任何需要该数据的业务流程的关键上游数据源。重复此方法几次,并添加我们经常看到的与遗留数据表示的紧密耦合,例如,如 侵入式关键聚合器 中所述,那么这可能会为遗留系统置换带来重大挑战。
通过追踪数据源和集成点回到遗留系统“之外”,我们通常可以为我们的遗留系统置换工作“恢复到源头”。这可以让我们尽早减少对遗留系统的依赖,并提供改进数据质量和及时性的机会,因为我们可以引入更现代的集成技术。
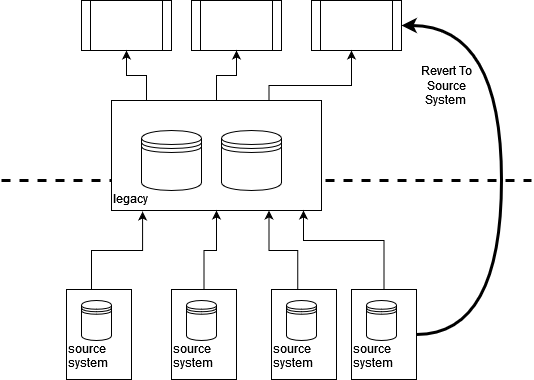
还值得注意的是,出于 GDPR 等商业和法律原因,了解数据的真实来源越来越重要。对于许多拥有大量遗留系统的组织来说,只有在出现故障或问题时,数据的真实来源才会变得更加清晰。
工作原理
作为任何遗留系统置换工作的一部分,我们需要追踪关键数据流的源头和接收器。根据我们选择如何划分整体问题,我们可能不需要对所有系统和数据同时进行此操作;尽管为了了解要完成的工作的总体规模,了解主要流程非常有用。
我们的目标是生成某种类型的数据流图。使用的实际格式并不重要,关键是这种发现不仅限于遗留系统,而是深入挖掘以查看底层的集成点。我们在与客户合作时看到了许多架构图,令人惊讶的是,它们似乎经常忽略了遗留系统背后的东西。
有几种技术可以追踪数据流经系统。从广义上讲,我们可以将这些技术视为追踪上游或下游的路径。虽然通常数据会流向和流出底层源系统,但我们发现组织往往只考虑数据源。也许从遗留系统的角度来看,这是任何集成中最显眼的部分?通常,我们发现从遗留系统流回源系统的数据流是任何集成中最不了解和最少记录的部分。
对于上游,我们通常从业务流程开始,然后尝试追踪数据流入遗留系统,然后流回遗留系统。这可能具有挑战性,尤其是在较旧的系统中,存在许多不同的集成技术组合。一个有用的技术是使用 CRC 卡,目标是为关键业务流程步骤创建数据流图以及时序图。无论我们使用哪种技术,让合适的人参与进来至关重要,理想情况下是那些最初在遗留系统上工作的人,但更常见的是那些现在支持遗留系统的人。如果这些人不可用,并且关于系统工作原理的知识已经丢失,那么从源头开始并向下游工作可能更合适。
追踪下游集成也非常有用,在我们看来,这往往被忽视,部分原因是如果 功能等效性 正在发挥作用,那么重点往往只放在现有的业务流程上。当追踪下游时,我们从底层的集成点开始,然后尝试追踪到它支持的关键业务能力和流程。这与地质学家在河流的可能源头处注入染料,然后观察染料最终出现在下游的哪些溪流和支流中类似。这种方法在遗留集成和相应系统的知识短缺的情况下特别有用,在创建新组件或业务流程时特别有用。当追踪下游时,我们可能会发现这些数据在何处发挥作用,而无需首先知道其确切路径,在这里,您可能需要将其与原始源数据进行比较,以验证数据是否在传输过程中被更改。
一旦我们了解了数据流,我们就可以查看是否可以在源头拦截或创建数据的副本,然后将其流向我们的新解决方案。因此,我们不是集成到遗留系统,而是创建一些新的集成,以允许我们的新组件恢复到源头。我们需要确保我们考虑了上游和下游流,但这些流不必像我们在下面的示例中看到的那样一起实现。
如果新的集成不可行,我们可以使用 事件拦截 或类似方法来创建数据流的副本,并将该副本路由到我们的新组件,我们希望尽可能在上游执行此操作,以减少对现有遗留行为的任何依赖。
何时使用
恢复到源头在我们要提取依赖于最终来自“隐藏在”遗留系统背后的集成点的数据的特定业务能力或流程时最为有用。它在数据大体上未经修改地流经遗留系统的情况下效果最佳,在数据在使用之前几乎没有进行处理或丰富的情况下效果最佳。虽然这在实践中听起来可能不太可能,但我们发现许多情况下遗留系统只是充当集成中心。我们看到这些情况下数据发生的 主要变化是数据丢失和数据及时性降低。数据丢失,因为字段和元素通常被过滤掉,仅仅是因为遗留系统无法表示它们,或者因为对遗留系统进行必要的更改成本过高且风险过大。及时性降低,因为许多遗留系统使用批处理作业进行数据导入,并且如 关键聚合器 中所述,“安全数据更新周期”通常是预定义的,并且几乎不可能更改。
我们可以将恢复到源头与并行运行和协调结合起来,以验证遗留系统中是否没有对数据进行其他更改。这是一种在一般情况下使用起来很可靠的方法,但在数据通过不同的路径流向不同的终点,但最终必须产生相同结果的情况下特别有用。
使用恢复到源头也可能有一个强大的商业案例,因为通常可以获得更丰富和更及时的数据。源系统通常会进行多次升级或更改,而这些更改实际上隐藏在遗留系统之后。我们已经看到了多个示例,其中对数据的改进实际上是这些升级的核心理由,但好处从未完全实现,因为更频繁和更丰富的更新无法通过遗留路径提供。
我们也可以在存在双向数据流且存在底层集成点的情况下使用此模式,尽管这里需要更加小心。最终流向源系统的任何更新都必须首先流经遗留系统,在这里它们可能会触发或更新其他流程。幸运的是,完全可以拆分上游和下游流。因此,例如,流回源系统的更改可以继续通过遗留系统流,而我们可以直接从源头获取更新。
务必注意源系统中可能存在的任何跨职能需求和约束,我们不想过载该系统,也不想发现它不可靠或无法直接提供所需数据。
零售店示例
对于一家零售客户,我们能够使用恢复到源头来提取新组件并改进现有的业务能力。该客户拥有大量商店,以及最近创建的用于在线购物的网站。最初,新网站从遗留系统获取其所有库存信息,而这些数据又来自仓库库存跟踪系统和商店本身。
这些集成是通过隔夜批处理作业完成的。对于仓库来说,这工作得很好,因为库存每天只离开仓库一次,因此企业可以确信,每天早上收到的批处理更新将在大约 18 小时内保持有效。对于商店来说,这会造成问题,因为库存显然可以在工作日的任何时间离开商店。
鉴于此约束,网站只提供仓库中可供出售的库存。来自网站的分析以及第二天收到的商店库存数据清楚地表明,由于此原因导致了销售损失:所需的库存全天都可以在商店中获得,但遗留集成的批处理性质使得无法利用这些库存。
在这种情况下,创建了一个新的库存组件,最初仅供网站使用,但目标是成为整个组织的新系统记录。该组件直接与店内收银系统集成,这些系统完全能够在销售发生时提供近乎实时的更新。事实上,企业已经投资了一个高度可靠的网络,将他们的商店连接起来,以支持电子支付,该网络拥有大量备用容量。仓库库存水平最初是从遗留系统中提取的,长期目标是在稍后阶段也将其恢复到源头。
最终结果是一个网站,可以安全地提供店内库存,用于店内预订和在线销售,以及一个新的库存组件,提供更丰富和更及时的库存流动数据。通过将新库存组件恢复到源头,该组织还意识到他们可以获得更及时的销售数据,而这些数据当时也只通过批处理流程更新到遗留系统中。产品线和价格等参考数据继续通过大型机流向店内系统,考虑到这些数据很少更改,这是完全可以接受的。
重大修订
2022 年 7 月 7 日:发布