
Richardson 成熟度模型
迈向 REST 的荣耀之路
一个模型(由 Leonard Richardson 开发),将 REST 方法的主要元素分解为三个步骤。这些步骤引入了资源、HTTP 动词和超媒体控制。
2010 年 3 月 18 日

最近我一直在阅读 Rest In Practice 的草稿:这本书是我的一些同事一直在编写的。他们的目标是解释如何使用 RESTful Web 服务来处理企业面临的许多集成问题。这本书的核心是,Web 是一个大规模可扩展的分布式系统的存在证明,它运行得很好,我们可以借鉴这些想法来更轻松地构建集成系统。
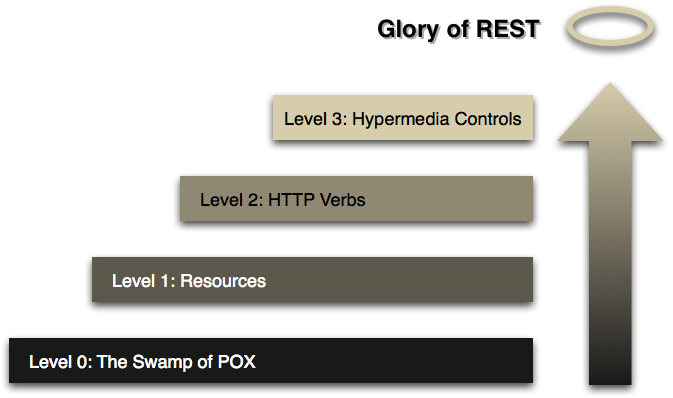
图 1:迈向 REST 的步骤
为了帮助解释 Web 风格系统的特定属性,作者使用了一个 RESTful 成熟度模型,该模型由 Leonard Richardson 开发并在 QCon 演讲中 解释。该模型是思考使用这些技术的一种好方法,所以我认为我会尝试自己解释一下。(这里的协议示例仅供说明,我认为没有必要对它们进行编码和测试,因此细节可能存在问题。)
级别 0
该模型的起点是使用 HTTP 作为远程交互的传输系统,但不使用 Web 的任何机制。本质上,您在这里所做的是使用 HTTP 作为您自己的远程交互机制的隧道机制,通常基于 远程过程调用。
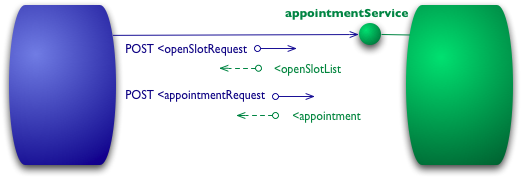
图 2:级别 0 的示例交互
假设我想预约我的医生。我的预约软件首先需要知道我的医生在特定日期有哪些空闲时间,因此它向医院预约系统发出请求以获取该信息。在级别 0 场景中,医院将在某个 URI 处公开一个服务端点。然后,我将包含我的请求详细信息的文档发布到该端点。
POST /appointmentService HTTP/1.1 [various other headers] <openSlotRequest date = "2010-01-04" doctor = "mjones"/>
然后,服务器将返回一个文档,其中包含此信息
HTTP/1.1 200 OK
[various headers]
<openSlotList>
<slot start = "1400" end = "1450">
<doctor id = "mjones"/>
</slot>
<slot start = "1600" end = "1650">
<doctor id = "mjones"/>
</slot>
</openSlotList>
我在这里使用 XML 作为示例,但内容实际上可以是任何东西:JSON、YAML、键值对或任何自定义格式。
我的下一步是预约,我也可以通过将文档发布到端点来完成。
POST /appointmentService HTTP/1.1 [various other headers] <appointmentRequest> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointmentRequest>
如果一切顺利,我会收到一个回复,说明我的预约已成功。
HTTP/1.1 200 OK [various headers] <appointment> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>
如果出现问题,例如其他人先于我预约,那么我会在回复正文中收到某种错误消息。
HTTP/1.1 200 OK [various headers] <appointmentRequestFailure> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> <reason>Slot not available</reason> </appointmentRequestFailure>
到目前为止,这是一个简单的 RPC 风格系统。它很简单,因为它只是来回传递普通的 XML(POX)。如果您使用 SOAP 或 XML-RPC,它基本上是相同的机制,唯一的区别是您将 XML 消息包装在某种信封中。
级别 1 - 资源
在 RMM 中迈向 REST 的荣耀的第一步是引入资源。因此,现在我们不再将所有请求都发送到一个单独的服务端点,而是开始与各个资源进行通信。
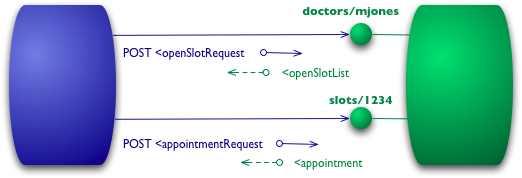
图 3:级别 1 添加了资源
因此,对于我们的初始查询,我们可能有一个给定医生的资源。
POST /doctors/mjones HTTP/1.1 [various other headers] <openSlotRequest date = "2010-01-04"/>
回复包含相同的基本信息,但每个时段现在都是一个可以单独寻址的资源。
HTTP/1.1 200 OK [various headers] <openSlotList> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>
有了特定的资源,预约就意味着发布到特定的时段。
POST /slots/1234 HTTP/1.1 [various other headers] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>
如果一切顺利,我会收到与之前类似的回复。
HTTP/1.1 200 OK [various headers] <appointment> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>
现在的区别是,如果任何人需要对预约做任何事情,例如预约一些测试,他们首先会获取预约资源,该资源可能有一个类似于 http://royalhope.nhs.uk/slots/1234/appointment 的 URI,并发布到该资源。
对于像我这样的面向对象的人来说,这就像对象标识的概念。我们不再调用以太中的某个函数并传递参数,而是对一个特定对象调用方法,并为其他信息提供参数。
级别 2 - HTTP 动词
我在级别 0 和 1 中的所有交互中都使用了 HTTP POST 动词,但有些人使用 GET 而不是或除了 POST 之外。在这些级别上,这没有太大区别,它们都被用作隧道机制,允许您通过 HTTP 隧道化您的交互。级别 2 远离这一点,尽可能地将 HTTP 动词用于 HTTP 本身的使用方式。
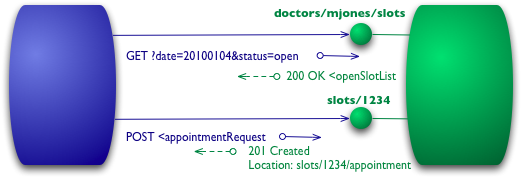
图 4:级别 2 添加了 HTTP 动词
对于时段列表,这意味着我们想要使用 GET。
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1 Host: royalhope.nhs.uk
回复与使用 POST 时相同
HTTP/1.1 200 OK [various headers] <openSlotList> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>
在级别 2 中,对于像这样的请求使用 GET 至关重要。HTTP 将 GET 定义为一个安全操作,也就是说它不会对任何事物的状态进行任何重大更改。这使我们能够安全地以任何顺序调用任意次数的 GET,并每次获得相同的结果。一个重要的结果是,它允许请求路由中的任何参与者使用缓存,这是使 Web 性能达到最佳水平的关键因素。HTTP 包含各种支持缓存的措施,所有通信参与者都可以使用这些措施。通过遵循 HTTP 的规则,我们能够利用这种能力。
要预约,我们需要一个改变状态的 HTTP 动词,一个 POST 或一个 PUT。我将使用与之前相同的 POST。
POST /slots/1234 HTTP/1.1 [various other headers] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>
这里使用 POST 和 PUT 之间的权衡比我想在这里讨论的要多,也许我将来会专门写一篇文章来讨论它们。但我确实想指出,有些人错误地将 POST/PUT 与创建/更新对应起来。它们之间的选择与之大不相同。
即使我使用与级别 1 相同的 POST,远程服务响应的方式也存在另一个重大差异。如果一切顺利,服务将回复一个 201 的响应代码,以表明世界上存在一个新的资源。
HTTP/1.1 201 Created Location: slots/1234/appointment [various headers] <appointment> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>
201 响应包含一个 location 属性,其中包含一个 URI,客户端可以使用该 URI 在将来获取该资源的当前状态。这里的响应还包含该资源的表示,以节省客户端现在进行额外调用的时间。
如果出现问题,例如其他人预约了该时段,则还存在另一个差异。
HTTP/1.1 409 Conflict [various headers] <openSlotList> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>
此响应的重要部分是使用 HTTP 响应代码来指示出现错误。在这种情况下,409 似乎是一个不错的选择,表明其他人已经以不兼容的方式更新了资源。我们不是使用 200 的返回代码,而是包含一个错误响应,在级别 2 中,我们明确地使用某种错误响应,例如这样。由协议设计者决定使用哪些代码,但如果出现错误,应该有一个非 2xx 响应。级别 2 引入了使用 HTTP 动词和 HTTP 响应代码。
这里出现了一个不一致的地方。REST 倡导者谈论使用所有 HTTP 动词。他们还通过说 REST 试图从 Web 的实际成功中吸取教训来证明他们的方法。但实际上,万维网并没有太多地使用 PUT 或 DELETE。使用 PUT 和 DELETE 有合理的理由,但 Web 的存在证明并非其中之一。
Web 的存在所支持的关键要素是安全(例如 GET)和非安全操作之间的严格分离,以及使用状态代码来帮助传达您遇到的错误类型。
级别 3 - 超媒体控制
最后一级介绍了一些您经常听到的用 HATEOAS(超文本作为应用程序状态的引擎)这个难看的缩写来指代的东西。它解决了如何从开放时段列表中知道如何预约的问题。
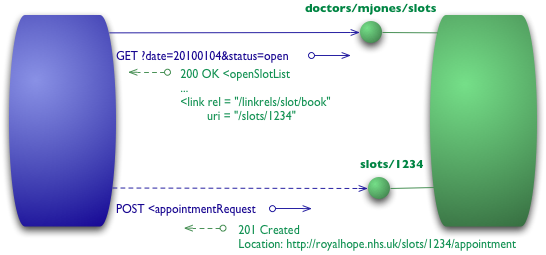
图 5:级别 3 添加了超媒体控制
我们从与级别 2 中发送的相同初始 GET 开始
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1 Host: royalhope.nhs.uk
但响应有一个新的元素
HTTP/1.1 200 OK
[various headers]
<openSlotList>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450">
<link rel = "/linkrels/slot/book"
uri = "/slots/1234"/>
</slot>
<slot id = "5678" doctor = "mjones" start = "1600" end = "1650">
<link rel = "/linkrels/slot/book"
uri = "/slots/5678"/>
</slot>
</openSlotList>
每个时段现在都有一个 link 元素,其中包含一个 URI,告诉我们如何预约。
超媒体控制的重点是,它们告诉我们接下来可以做什么,以及我们需要操作以执行该操作的资源的 URI。我们不必知道在哪里发布我们的预约请求,响应中的超媒体控制会告诉我们如何操作。
POST 将再次复制级别 2 中的 POST
POST /slots/1234 HTTP/1.1 [various other headers] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>
回复包含许多用于执行下一步的不同操作的超媒体控制。
HTTP/1.1 201 Created
Location: http://royalhope.nhs.uk/slots/1234/appointment
[various headers]
<appointment>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/>
<patient id = "jsmith"/>
<link rel = "/linkrels/appointment/cancel"
uri = "/slots/1234/appointment"/>
<link rel = "/linkrels/appointment/addTest"
uri = "/slots/1234/appointment/tests"/>
<link rel = "self"
uri = "/slots/1234/appointment"/>
<link rel = "/linkrels/appointment/changeTime"
uri = "/doctors/mjones/slots?date=20100104&status=open"/>
<link rel = "/linkrels/appointment/updateContactInfo"
uri = "/patients/jsmith/contactInfo"/>
<link rel = "/linkrels/help"
uri = "/help/appointment"/>
</appointment>
超媒体控制的一个明显好处是,它允许服务器更改其 URI 方案而不会破坏客户端。只要客户端查找“addTest”链接 URI,服务器团队就可以调整除初始入口点以外的所有 URI。
另一个好处是,它有助于客户端开发人员探索协议。链接为客户端开发人员提供了关于接下来可能发生什么的提示。它不会提供所有信息:“self”和“cancel”控制都指向同一个 URI - 他们需要弄清楚一个是 GET,另一个是 DELETE。但至少它为他们提供了一个关于要考虑哪些信息的起点,以及在协议文档中寻找类似的 URI。
同样,它允许服务器团队通过在响应中添加新链接来宣传新功能。如果客户端开发人员一直在关注未知链接,那么这些链接可以作为进一步探索的触发器。
关于如何表示超媒体控制没有绝对的标准。我在这里所做的是遵循 REST In Practice 团队的当前建议,即遵循 ATOM (RFC 4287) 我使用一个 <link> 元素,其中包含一个 uri 属性用于目标 URI,以及一个 rel 属性用于描述关系类型。一个众所周知的关联(例如 self 用于对元素本身的引用)是裸露的,任何特定于该服务器的关联都是一个完全限定的 URI。ATOM 指出,众所周知的 linkrel 的定义是 链接关系注册表 。当我写这些的时候,它们仅限于 ATOM 所做的,ATOM 通常被认为是级别 3 RESTful 的领导者。
级别的含义
我应该强调,RMM 虽然是思考 REST 元素的一种好方法,但它本身并不是 REST 级别定义。Roy Fielding 已经明确表示 级别 3 RMM 是 REST 的先决条件。像软件中的许多术语一样,REST 有很多定义,但由于 Roy Fielding 创造了这个术语,因此他的定义应该比大多数定义更有分量。
我发现 RMM 有用之处在于,它提供了一种很好的逐步方法来理解 RESTful 思维背后的基本思想。因此,我认为它是一个帮助我们学习这些概念的工具,而不是应该用在某种评估机制中的工具。我认为我们还没有足够的例子来真正确定 RESTful 方法是否是集成系统的正确方法,但我确实认为它是一种非常有吸引力的方法,也是我推荐在大多数情况下使用的方法。
与 Ian Robinson 讨论这个问题时,他强调,当 Leonard Richardson 首次提出这个模型时,他发现这个模型吸引人的地方是它与常见设计技术的联系。
- 级别 1 解决了通过使用分治法来处理复杂性的问题,将一个大型服务端点分解为多个资源。
- 级别 2 引入了一组标准动词,以便我们以相同的方式处理类似的情况,从而消除不必要的差异。
- 第三级引入了可发现性,提供了一种使协议更具自文档性的方法。
其结果是一个模型,帮助我们思考想要提供的 HTTP 服务类型,并设定与之交互的人员的期望。
致谢
Savas Parastatidis、Ian Robinson 和 Jim Webber 对草案提出了宝贵的意见。Leonard Richardson 在回答我的问题方面非常有帮助,使我能够最大程度地减少对他的想法的误解。Aaron Swartz 修正了我第三级 URI 中的一些错误。
重大修订
2010 年 3 月 18 日: 首次发布