
重构代码以加载文档
许多现代 Web 服务器代码会与上游服务通信,这些服务返回 JSON 数据,对这些 JSON 数据进行一些处理,然后使用流行的单页应用程序框架将其发送到富客户端网页。与使用此类系统的人交谈时,我经常听到他们对处理这些 JSON 文档需要做多少工作感到沮丧。通过封装加载策略的组合,可以避免许多这种沮丧。
2015 年 12 月 17 日

当我加载文档时 - 无论是 JSON、XML 还是任何其他数据层次结构 - 我都必须选择如何在程序中表示它。我自己不会编写太多加载代码,有一些库可以为我完成这项工作,但我仍然需要选择数据的最终去向。这种选择应该基于我将如何使用数据。但我经常遇到将所有内容加载到复杂对象结构中的程序,最终导致不必要的代码,这些代码难以维护。
初始代码
为了说明一些不同的方法,我将使用一个提供有关音乐专辑分类信息的示例服务。它使用的数据看起来像这样。
{
"albums": [
{
"title": "Isla",
"artist": "Portico Quartet",
"tracks": [
{"title": "Paper Scissors Stone", "lengthInSeconds": 327},
{"title": "The Visitor", "lengthInSeconds": 330},
{"title": "Dawn Patrol", "lengthInSeconds": 359},
{"title": "Line", "lengthInSeconds": 449},
{"title": "Life Mask (Interlude)", "lengthInSeconds": 75},
{"title": "Clipper", "lengthInSeconds": 392},
{"title": "Life Mask", "lengthInSeconds": 436},
{"title": "Isla", "lengthInSeconds": 310},
{"title": "Shed Song (Improv No 1)", "lengthInSeconds": 503},
{"title": "Su-Bo's Mental Meltdown", "lengthInSeconds": 347}
]
},
{
"title": "Horizon",
"artist": "Eyot",
"tracks": [
{"title": "Far Afield", "lengthInSeconds": 423},
{"title": "Stone upon stone upon stone", "lengthInSeconds": 479},
{"title": "If I could say what I want to", "lengthInSeconds": 167},
{"title": "All I want to say", "lengthInSeconds": 337},
{"title": "Surge", "lengthInSeconds": 620},
{"title": "3 Months later", "lengthInSeconds": 516},
{"title": "Horizon", "lengthInSeconds": 616},
{"title": "Whale song", "lengthInSeconds": 344},
{"title": "It's time to go home", "lengthInSeconds": 539}
]
}
]
}
该服务是用 Java 编写的,使用 Jackson 库来读取 JSON。通常的做法是定义一系列 Java 类,并使用 Jackson 的巧妙数据绑定功能将 JSON 数据映射到类的字段中。为了处理此数据,我们需要这些类。
class Assortment…
private List<Album> albums;
public List<Album> getAlbums() {
return Collections.unmodifiableList(albums);
}
class Album…
private String artist;
private String title;
private List<Track> tracks;
public String getArtist() {
return artist;
}
public String getTitle() {
return title;
}
public List<Track> getTracks() {
return Collections.unmodifiableList(tracks);
}
class Track…
private String title;
private int lengthInSeconds;
public String getTitle() {
return title;
}
public int getLengthInSeconds() {
return lengthInSeconds;
}
Jackson 使用反射将 JSON 数据自动映射到相应的 Java 对象。由于这一点,我不必编写任何代码来加载对象。但是,我必须定义 JSON 加载到的对象。
我可以使用公共字段或私有字段和公共 getter。getter 会使代码更冗长,但我更喜欢使用它们,因为我喜欢遵循 统一访问原则。IntelliJ 会为我编写 getter,这进一步减少了烦恼。
通过像这样定义类,加载 JSON 数据只是一个简单的函数调用。
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = Json.mapper().readValue(dataSource.getAlbumList(query), Assortment.class);
return Json.mapper().writeValueAsString(data);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
JSON 数据来自某些数据源,通过调用 dataSource.getAlbum(query) 获取。这可能是对另一个服务的调用、对 JSON 导向数据库的访问、从文件读取,或任何其他目前不关心的来源。
class Json…
public static ObjectMapper mapper() {
JsonFactory f = new JsonFactory().enable(JsonParser.Feature.ALLOW_COMMENTS);
return new ObjectMapper(f);
}
虽然我不必编写任何代码来从 JSON 数据加载对象,但我必须编写对象定义。在这种情况下并不多,但我遇到过需要一百个类来表示 JSON 数据的情况。如果这些对象没有被大量使用,那么编写这样的类定义就是令人厌烦的繁琐工作。
正当的用例是我们使用数据绑定中定义的所有对象和方法。因此,如果我定义了十个类和 200 个公共方法,而只使用了其中的五个,那么这表明有些地方不对劲。为了检查其他方法,我们需要查看一些不同的情况,并考虑我们可以采取的各种替代路线。
但无论采用哪种方法,我都会从相同的步骤开始。
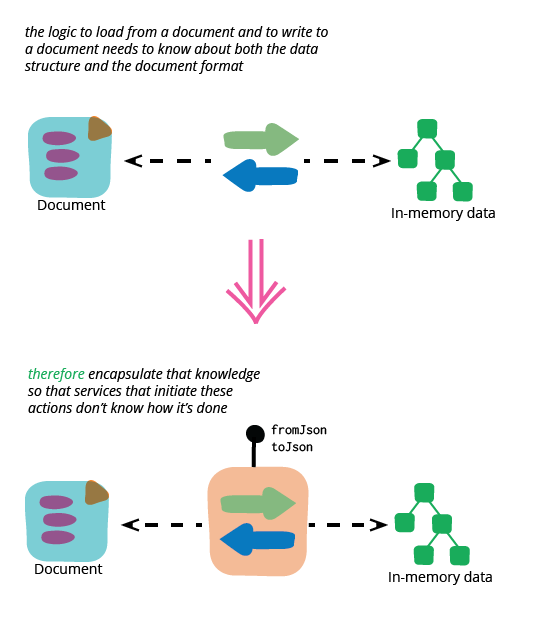
封装分类
每当我进行重构时,我都会查看如何通过将大部分更改封装在一些合适的函数后面来减少更改的可见性。由于我正在处理分类,这意味着将将分类转换为 JSON 和从 JSON 转换分类的责任转移到分类本身。
我首先对加载分类的代码使用 提取函数。
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = loadAssortment(query);
return Json.mapper().writeValueAsString(data);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
private Assortment loadAssortment(String query) throws java.io.IOException {
return Json.mapper().readValue(dataSource.getAlbumList(query), Assortment.class);
}
我不喜欢受检异常,因此我的默认做法是在它们出现时立即将它们包装在运行时异常中。
class Service…
private Assortment loadAssortment(String query) {
try {
return Json.mapper().readValue(dataSource.getAlbumList(query), Assortment.class);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
我希望新函数接受一个 JSON 数据字符串,因此我调整了新函数的参数。
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = loadAssortment(dataSource.getAlbumList(query));
return Json.mapper().writeValueAsString(data);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
private Assortment loadAssortment(String json) {
try {
return Json.mapper().readValue(json, Assortment.class);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
通过很好地提取行为,我就可以将其作为工厂函数移动到分类类中。
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = Assortment.fromJson(dataSource.getAlbumList(query));
return Json.mapper().writeValueAsString(data);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
class Assortment…
public static Assortment fromJson(String json) {
try {
return Json.mapper().readValue(json, Assortment.class);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
我无法使用 IntelliJ 的移动函数重构来完成此操作,但手动操作很容易。
我使用相同的步骤序列来提取和移动代码以发出 JSON。
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = Assortment.fromJson(dataSource.getAlbumList(query));
return data.toJson();
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
class Assortment…
public String toJson() {
try {
return Json.mapper().writeValueAsString(this);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
如果我有其他使用这种分类的服务函数,我现在将调整所有对这些函数的调用以使用这些新函数。完成后,我将拥有封装了序列化机制的对象,这使得我更容易更改它。
封装的本质是将设计决策变成秘密
有些人可能会觉得我使用“封装它们的序列化机制”这个短语很奇怪。当人们学习面向对象编程时,他们经常被告知数据是封装的,因此将行为视为应该封装的东西可能听起来很奇怪。但是,封装的全部意义在于做出一些决策,这可能是行为或数据结构的选择,并将它变成一个秘密,这样外部代码就不知道封装边界后面的情况。在这种情况下,我不希望分类外部的任何代码知道分类如何与 JSON 相关联,因此我将执行加载的代码封装在分类类中。
传递 JSON
现在我已经封装了分类的 JSON 处理,我可以开始查看根据其使用方式重构它的不同方法。
最简单的情况是,服务只需要与提供给分类的 JSON 相同的 JSON。在这种情况下,我可以将 JSON 字符串本身存储在分类中,而不必理会 jackson。
class Assortment…
private String json;
public static Assortment fromJson(String json) {
Assortment result = new Assortment();
result.json = json;
return result;
}
public String toJson() {
return json;
}
然后我可以完全删除 album 和 track 类。
事实上,在这种情况下,我将完全删除分类类,而只是让服务直接返回数据源调用的结果。
class Service…
public String tuesdayMusic(String query) {
try {
return dataSource.getAlbumList(query);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
内部客户端
接下来,我将考虑在服务器进程中有一个客户端需要从 JSON 数据中收集的一些信息的情况。
class SomeClient…
public List<String> doSomething(Assortment anAssortment) {
List<String> titles = anAssortment.getAlbums().stream()
.map(a -> a.getTitle())
.collect(Collectors.toList());
return somethingCleverWith(titles);
}
这种情况需要一些 Java 代码来操作 JSON 数据,因此我需要的不只是一个字符串。但是,如果这是唯一的客户端,那么我不需要构建我之前显示的整个对象树。相反,我可以使用看起来像这样的 Java 类。
class Assortment…
private List<Album> albums;
public List<Album> getAlbums() {
return Collections.unmodifiableList(albums);
}
class Album…
private String title;
public String getTitle() {
return title;
}
我可以完全删除 track 类。
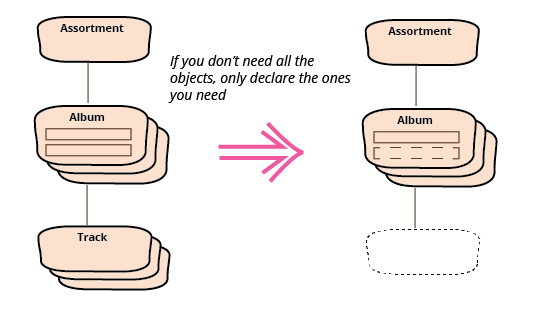
如果我只需要一部分 JSON 数据,那么导入所有数据就没有意义。通过数据绑定指定我需要的部分是一个非常好的方法,可以获取这样的缩减数据集。使用这种数据绑定的库通常有一个配置参数,指示数据绑定应该如何处理目标记录中没有绑定的 JSON 中的字段。默认情况下,Jackson 会抛出 UnrecognizedPropertyException,但可以通过禁用 FAIL_ON_UNKNOWN_PROPERTIES 功能来轻松更改此行为,方法是调用类似以下内容的函数:
anObjectMapper.disable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES)
通过声明一个只包含我需要的属性的类结构,我避免了不必要的努力 - 声明属性的行为与挑选我想要的字段一样好。
这是一个其他 Java 类想要通过 Java API 调用获取分类的专辑标题的情况。类似的情况是,当客户端想要 JSON 数据的子集时,常规的 toJson 调用现在只会返回专辑标题。
{"albums":[
{"title":"Isla"},
{"title":"Horizon"}
]}
如果我只使用输入文档中的一部分数据,我通常发现最好将事情安排好,以便我只绑定到我正在使用的数据。如果我定义了一个完整的对象结构来映射,那么如果供应商在 JSON 中添加了一个我可以安全忽略的字段,我的代码就会崩溃。通过只定义我使用的结构,我创建了一个 容忍读取器,这使得我的程序对输入数据的更改更具弹性。
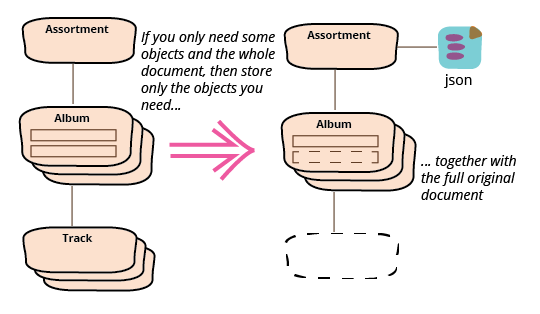
Java API 和完整 JSON
这自然会导致我的第三种情况,如果我们希望服务调用返回完整的 JSON 文档,但同时我们也希望通过 Java API 获取专辑标题列表,该怎么办?
这种情况的答案是将前两种情况结合起来,既存储原始 JSON 字符串,也存储 Java API 所需的任何 Java 对象。因此,在这种情况下,我在工厂函数中添加了字符串。
class Assortment…
private String doc;
public static Assortment fromJson(String json) {
try {
final Assortment result = Json.mapper()
.disable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES)
.readValue(json, Assortment.class);
result.doc = json;
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public String toJson() {
return doc;
}
完成此操作后,我可以删除 Java 数据结构中不需要的函数和类,就像我只使用 Java API 时一样。
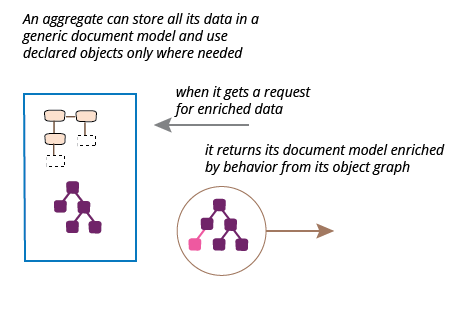
丰富输出 JSON 文档
到目前为止,这些场景都将 JSON 文档视为我们所需信息的完整载体,但有时我们会使用服务器进程来丰富这些信息。考虑我们希望获取每个专辑长度信息的情况。使用完整的对象结构,这很容易。
class Album…
public int getLengthInSeconds() {
return tracks.stream().collect(Collectors.summingInt(Track::getLengthInSeconds));
}
此函数既可以通过 Java 函数调用向 Java 客户端提供信息,也可以在使用 Jackson 的数据绑定创建输出 JSON 时自动将其添加到 JSON 输出中。唯一的问题是,这迫使我将整个 JSON 结构声明为 Java 类,对于这个小例子来说这不是什么大问题,但当有数十或数百个其他不必要的类定义时,就会成为问题。我可以通过使用和丰富文档模型来避免这种情况。
我将从完整的类定义集以及专辑长度方法的原始起点开始重构。我的第一步是,与之前的示例一样,在读取时添加一个额外的 JSON 文档。但是这次我将把它读成一个 Jackson 树模型,并且我还没有修改输出代码。
class Assortment…
private List<Album> albums; private JsonNode doc; public List<Album> getAlbums() { return Collections.unmodifiableList(albums); } public static Assortment fromJson(String json) { try { final Assortment result = Json.mapper().readValue(json, Assortment.class); result.doc = Json.mapper().readTree(json); return result; } catch (IOException e) { throw new RuntimeException(e); } } public String toJson() { try { return Json.mapper().writeValueAsString(this); } catch (JsonProcessingException e) { throw new RuntimeException(e); } }
我的下一步是创建一个方法来输出即将被增强的 JSON 文档模型。我从一个简单的访问器开始,并测试它是否只输出当前文档。
class Assortment…
public String enrichedJson() {
return doc.toString();
}
类测试器…
@Test
public void enrichedJson() throws Exception {
JsonNode expected = Json.mapper().readTree(new File("src/test/enrichedJson.json"));
JsonNode actual = Json.mapper().readTree(getAssortment().enrichedJson());
assertEquals(expected, actual);
}
目前测试只是探测输出文档是否与输入文档相同,但我现在有一个钩子,我可以逐步向输出添加增强步骤。这里不是什么大问题,因为我只有一个,但如果文档有多个增强,那么这样的测试允许我一次添加一个。
所以现在是时候设置增强代码了。
class Assortment…
public String enrichedJson() {
JsonNode result = doc.deepCopy();
getAlbums().forEach(a -> a.enrichJson(result));
return result.toString();
}
class Album…
public void enrichJson(JsonNode parent) {
final ObjectNode albumNode = matchingNode(parent);
albumNode.put("lengthInSeconds", getLengthInSeconds());
}
private ObjectNode matchingNode(JsonNode parent) {
final Stream<JsonNode> albumNodes = StreamSupport.stream(parent.path("albums").spliterator(), false);
return (ObjectNode) albumNodes
.filter(n -> n.path("title").asText().equals(title))
.findFirst()
.get()
;
}
我增强的基本方法是遍历 Java 记录,让每个记录增强其对应的树节点。
一般来说,我更喜欢尽可能地使用集合管道,但我不得不承认,整个与 StreamSupport 和 spliterator 的业务非常痛苦。希望随着时间的推移,Jackson 将直接支持流,以避免不得不这样做。
与其修改嵌入在分类中的文档,我更喜欢创建一个新文档。一般来说,我更喜欢保持数据的读取状态,并按需进行更新。如果构建新的 JSON 文档的成本很高,我总是可以缓存结果。
如果我有一堆增强,我可以使用这种机制一次添加一个,并测试每次更改后的新数据。然后,一旦完成,我可以将数据绑定输出替换为增强的文档。
class Assortment…
public String toJson() {
JsonNode result = doc.deepCopy();
getAlbums().forEach(a -> a.enrichJson(result));
return result.toString();
}
一旦我完成了,我就可以愉快地修剪我的类结构,删除所有现在不再使用的无用数据、方法和类。在这个例子中并不多,但用这种方式从代码中删除 37 个类很有趣。
仅使用树模型
我可以通过使用树模型作为增强的基础,从 Java 类声明中修剪更多内容。在这种方法中,我纯粹通过遍历文档的树来进行增强,而不涉及域对象。在这种情况下,增强代码将如下所示。
class Assortment…
public String toJson() {
JsonNode result = doc.deepCopy();
enrichDoc(result);
return result.toString();
}
private void enrichDoc(JsonNode doc) {
for(JsonNode n : doc.path("albums")) enrichAlbum((ObjectNode)n);
}
private void enrichAlbum(ObjectNode albumNode) {
int length = 0;
for (JsonNode n : albumNode.path("tracks")) length += n.path("lengthInSeconds").asInt();
albumNode.put("lengthInSeconds", length);
}
对于那些习惯于在动态语言中操作 列表和哈希 的人来说,这种代码应该看起来很熟悉。然而,总的来说,我不喜欢在 Java 中这样做。拥有和使用 Java 对象通常是放置行为的最佳位置,尤其是在行为的体积和复杂性不断增加的情况下。
然而,我使用这种风格的一个例外是,如果在层次结构中向下导航到多个层级,通过多个原本不需要的类,尽管在那里我倾向于只使用较低级别的节点来创建对象。
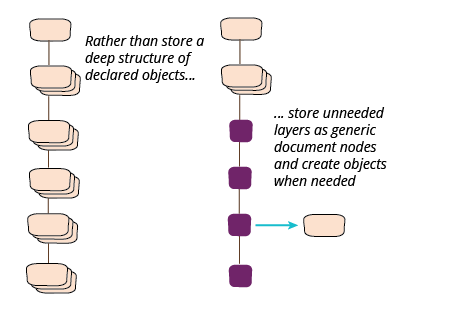
在文档结构中创建深层对象
如果我们有一个大型文档,需要许多类来表示,其中大多数是不必要的,但有一些重要的东西在树的叶子附近?在前面关于专辑标题列表的例子中,我可以通过数据绑定到 JSON 数据的子集来支持它们并删除轨道。但如果我只想要更低层的东西呢?
对于我的示例,让我们想象一个想要轨道列表的客户端。由于轨道和分类之间只有一个专辑类,我会通过数据绑定来处理这种情况。但让我们假设有十几个不需要的层级在中间,那该怎么办呢?
在这种情况下,我想避免数据绑定所有这些层级,但我仍然想要客户端的适当对象。为了说明我如何处理这个问题,让我们假设到目前为止,我只有一个想要整个 JSON 字符串的客户端,所以我遵循了之前的重构路径,只将它存储在我的分类中。
class Assortment…
private String json;
public static Assortment fromJson(String json) {
Assortment result = new Assortment();
result.json = json;
return result;
}
public String toJson() {
return json;
}
很好,这是一个很好的最小解决方案。但后来我得到一个需要新的 Java API 来访问文档的新功能。
class SomeClient…
public String doSomething(Assortment anAssortment) {
final List<Track> tracks = anAssortment.getTracks();
return somethingCleverWith(tracks);
}
同样,对于这个文档,我只会切换到数据绑定,但相反,我们将继续假装,我实际上有十几个东西,而不是在分类和轨道之间只有一个专辑类——足以让我放弃数据绑定。
我想使用文档树,所以我的第一步是从字符串重构到树。
class Assortment…
private JsonNode doc;
public static Assortment fromJson(String json) {
Assortment result = new Assortment();
try {
result.doc = Json.mapper().readTree(json);
} catch (IOException e) {
throw new RuntimeException(e);
}
return result;
}
public String toJson() {
return doc.toString();
}
完成这段准备性重构后,我就可以开始创建轨道了。我通过只选择轨道节点,然后使用数据绑定将轨道节点作为源来实现这一点。
class Assortment…
public List<Track> getTracks() {
return StreamSupport.stream(doc.path("albums").spliterator(), false)
.map(a -> a.path("tracks"))
.flatMap(i -> StreamSupport.stream(i.spliterator(), false))
.map(Track::fromJson)
.collect(Collectors.toList())
;
}
class Track…
private String title;
private int lengthInSeconds;
public String getTitle() {
return title;
}
public int getLengthInSeconds() {
return lengthInSeconds;
}
public static Track fromJson (JsonNode node) {
try {
return Json.mapper().treeToValue(node, Track.class);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
我已经用一个记录展示了这一点,但用小的子树做这件事同样容易,这允许我从更大的文档中提取出重要的信息。如果我正在对文档进行更严肃的重构,这种方法非常方便,我可以使用这些类型的本地 API 作为数据源来构建一个输出 数据传输对象,然后我可以将其序列化为适当的输出表示。
我也可以从一个完整的数据绑定模型进行类似的重构。
总结
我们很大一部分编程工作都集中在操作和处理通过层次数据文档传入的数据。值得记住的是,有几种方法可以处理这些信息,并选择合适的组合来保持代码库的小巧和灵活。人们经常忘记封装意味着隐藏数据结构和处理方法,我们不应该期望模块的接口应该与其内部存储相对应。
致谢
我的同事 Carlyle Davis、Chris Birch 和 Peter Hodgson 在我起草这篇文章时与我讨论了这篇文章。
重大修订
2015 年 12 月 17 日:发布最终的初始部分
2015 年 12 月 15 日:发布了增强输出 json 部分
2015 年 12 月 14 日:发布了第一部分