
准备重构的示例
2015年1月5日

重构可以融入我们的编程工作流程的方式多种多样。一个有用的概念是准备重构。在这种情况下,我正在添加一个新功能,并且我发现现有代码的结构不利于轻松添加该功能。因此,我首先将代码重构为易于添加该功能的结构,或者正如肯特·贝克简洁地说:“使更改变得容易,然后进行简单的更改”。
在最近的 Ruby Rogues 播客中,杰西卡·凯尔为准备重构提供了一个很好的比喻。
这就像我想向东走 100 英里,但不是直接穿过树林,而是先向北行驶 20 英里到达高速公路,然后以三倍的速度向东行驶 100 英里,如果我直接到达那里,我本可以以三倍的速度行驶。当人们催促你直接到达那里时,有时你需要说:“等等,我需要查看地图并找到最快的路线。”准备重构为我做到了这一点。
-- 杰西卡·凯尔
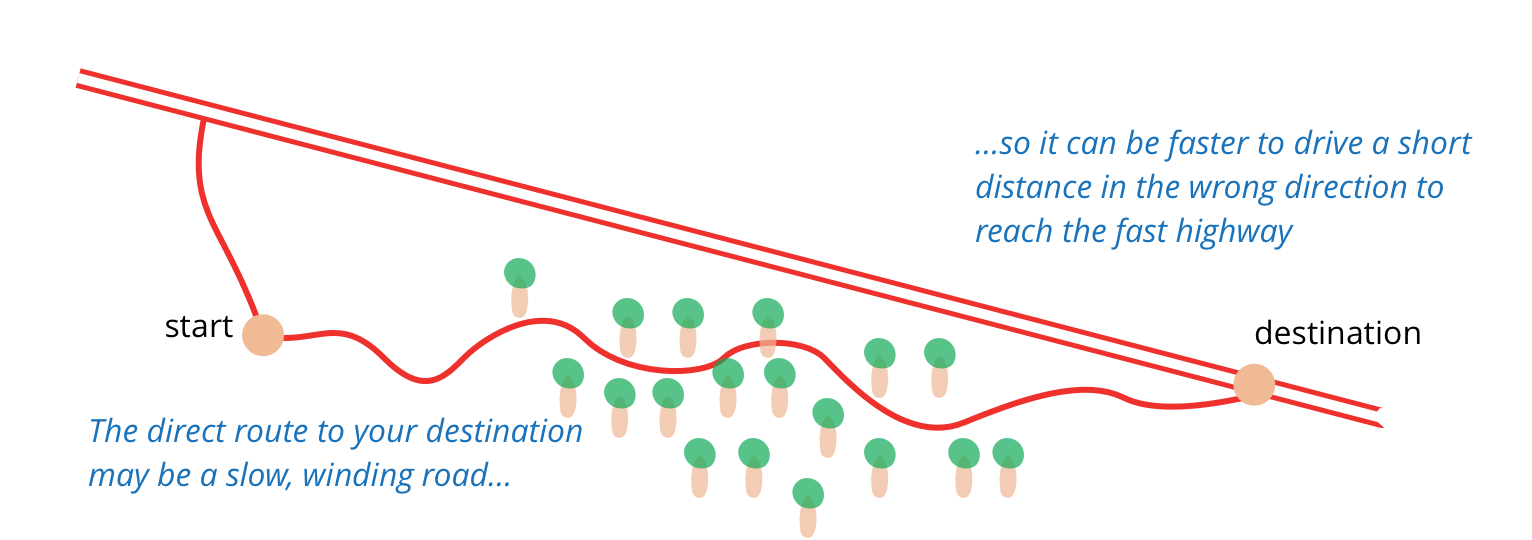
我遇到的另一个很好的比喻是在粉刷墙壁时用胶带覆盖电源插座、门框、踢脚线等。胶带不是用来粉刷的,但通过花时间先把东西盖起来,粉刷可以更快更容易。
一般性陈述和比喻都很好,但展示一个例子会更好。最近我自己遇到一个例子,我认为值得分享。
起点
我的出版工具链包括将来自实时文件的代码插入文章的能力。所谓“实时文件”,是指可以编译和运行的代码,通常是教学性的(即玩具)示例。能够从实时文件中提取代码非常有用,因为它可以避免复制粘贴问题,并让我确信文章中的代码是实际可以编译和通过测试的代码。我通过包含在注释中的标记来标记代码部分。 [1]
我现在正在添加的一项功能是能够突出显示这些代码片段的特定部分。这样,我可以选择一行或一行代码的一部分,并用 span 元素将其包围在 html 中,然后我可以使用 css 以任何我想要的方式突出显示它。你将在本文后面看到我这样做的示例,因为它在讨论重构时特别有用。
在我这里讨论的编程片段开始时,我已经具备了突出显示给定行或给定行内代码跨度的能力。我想添加第三种功能,突出显示一行范围。
在我的文章源文档中,我用 insertCode XML 元素指示我想插入代码片段。我当前的突出显示功能允许我定义一堆突出显示。以下是一个示例
<insertCode file = "Notification.java" fragment = "notification-with-error">
<highlight line="add\(" span="new.*e\)"/>
<highlight line="map"/>
</insertCode>
这将突出显示如下代码
public void addError(String message, Exception e) {
errors.add(new Error(message, e));
}
public String errorMessage() {
return errors.stream()
.map(e -> e.message)
.collect(Collectors.joining(", "));
}
insertCode 元素具有用于文件路径和我想提取的片段名称的属性。然后,我可以使用子元素指定突出显示。每个突出显示都通过提供一个正则表达式来指定一行,我使用该正则表达式来匹配该行。我可以提供一个 span 属性,另一个正则表达式,在这种情况下,突出显示仅适用于匹配该正则表达式的行的一部分。如果我不提供 span,则突出显示将应用于整行。
我把执行突出显示的代码放在一个单独的类中。一些单独的代码(我们不需要担心)从源文件中提取代码片段,然后它会查看是否需要任何突出显示,如果是,它会创建一个 CodeHighlighter 对象并告诉它进行突出显示。代码高亮器的调用看起来像这样
output << CodeHighlighter.new(insertCodeElement, codeFragment).call
这使用了方法对象模式,我使用一个对象来表示一个一等函数。我使用该函数的参数创建对象,调用另一个方法来运行该函数,该函数返回结果,然后让方法对象被垃圾回收。
以下是该高亮器的实现
class CodeHighlighter
def initialize insertCodeElement, fragment
@data = insertCodeElement
@fragment = fragment
end
def call
@fragment.lines.map{|line| highlight_line line}.join
end
def highlight_line line
highlights
.select{|h| Regexp.new(h['line']).match(line)}
.reduce(line){|acc, each| apply_markup acc, each}
end
def highlights
@data.css('highlight')
end
def apply_markup line, element
open = "<span class = 'highlight'>"
close = "</span>"
if element.key? 'span'
r = Regexp.new(element['span'])
m = r.match line
m.pre_match + open + m[0] + close + m.post_match
else
open + line.chomp + close + "\n"
end
end
end
工具链代码是 ruby,它使用 Nokogiri 库来操作 XML
我还没有过多地考虑边缘情况,例如,如果我指定了多个重叠的突出显示,这些重叠会以影响显示的方式出现。毕竟,如果我遇到任何这些问题,我知道我住在哪里。这是编写代码的奢侈,因为我是唯一的用户。
测试高亮器
测试高亮器非常简单,它是一个纯函数,它接受一些输入并输出一些输出。但是,我在测试类中添加了一些机制,使编写测试变得更容易。首先,我喜欢将输入和输出的文本块保存在一个单独的文件中,该文件看起来像这样
codeHighlighterHunks.txt…
input
private void validateDate(Notification note) {
if (date == null) {
note.addError("date is missing");
return;
}
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
%% one-line
private void validateDate(Notification note) {
if (date == null) {
<span class = 'highlight'> note.addError("date is missing");</span>
return;
}
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
%% one-span
private void validateDate(Notification note) {
if (date == null) {
note.<span class = 'highlight'>addError</span>("date is missing");
return;
}
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
…
这里你看到三个文本块,用 %% 分隔。第一个块是我的(第一个)输入字符串,接下来的两个是针对一行和一行内跨度的输出。每个块都有一个键,即 %% 后面的文本。然后,我可以在测试类中轻松地获取这些块
class CodeHighlighterTester…
def hunks
raw = File.read('test/codeHighlighterHunks.txt').split("\n%%")
raw.map {|r| process_raw_hunk r}.to_h
end
def process_raw_hunk hunk
lines = hunk.lines
key = lines.first.strip
value = lines
.drop(1)
.drop_while {|line| (/[^[:space:]]/ !~ line)}
.join
return [key, value]
end
有了轻松提取块的能力,我就可以在测试中引用它们。
class CodeHighlighterTester…
def test_no_highlights
assert_equal hunks['input'], with_highlights(form_element(""))
end
def test_one_line_highlight
element = form_element "<highlight line = 'missing'/>"
assert_equal hunks['one-line'], with_highlights(element)
end
def test_highlight_span
element = form_element "<highlight line = 'missing' span = 'addError'/>"
assert_equal hunks['one-span'], with_highlights(element)
end
def form_element s
Nokogiri::XML("<insertCode>" + s + "</insertCode").root
end
def with_highlights element, input = nil
input ||= hunks['input']
CodeHighlighter.new(element,input).call
end
我本可以使用多行字符串或 here docs 来实现这一点,但我认为文本块更容易使用。
添加高亮范围
我想添加的新功能是突出显示一行范围,如下所示。
<insertCode file = "BookingRequest.java" fragment = "done"> <highlight-range start-line = "missing" end-line = "return"/> </insertCode>
start-line 和 end-line 属性再次是正则表达式,用于匹配范围中的第一行和最后一行。
我首先为新的标记行为添加了一个测试,检查它是否失败,然后标记它为跳过。我喜欢先编写最终行为的测试,因为这可以让我清楚地了解我想要的结果是什么,以及我想要 API 如何工作。但是,如果我要进行任何准备重构,我不希望该测试的失败弄乱我的测试输出,因此在观察它失败一次后,我在处理它时会跳过它。
class CodeHighlighterTester…
def test_highlight_range
skip
e = '<highlight-range start-line = "(date == null)" end-line = "}"/>'
assert_equal hunks['range'], with_highlights(form_element(e))
end
codeHighlighterHunks.txt…
%% range
private void validateDate(Notification note) {
<span class = 'highlight'> if (date == null) {
note.addError("date is missing");
return;
}</span>
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
当我思考如何处理它时,我首先决定可以将代码突出显示视为对提供的文本的一系列转换。我可以先应用任何突出显示范围转换,然后用现有的突出显示跟随它们。我现在可以将这种想法从我的脑海转移到代码中。
我的第一步是简单地对 call 的整个主体使用 提取方法
class CodeHighlighter…
def call
apply_highlights @fragment.lines
end
def apply_highlights lines
lines.map{|line| highlight_line line}.join
end
现在我引入了一个嵌套的无操作函数 - 也就是说,一个只返回你给它的东西,没有任何更改的函数。
class CodeHighlighter…
def call
apply_highlights(apply_ranges(@fragment.lines))
end
def apply_ranges lines
lines
end
这个单一的重构实际上是整篇文章的精华,简化为一个简单的步骤。通过这个重构,我做了一些事情。首先,通过将 apply_ranges 方法放入调用中,我为我的新功能创建了一个位置。但其次,也许更重要的是,我立即以一种保留当前行为的方式实现了这个新函数。在某种程度上,这种能够轻松插入占位符函数的能力是将突出显示行为结构化为一系列较小的转换的巨大优势之一 - 这是 管道和过滤器模式 成为结构化计算如此强大的方式的原因之一。
通过用这种简单的行为保留实现来定义 apply_ranges,而不是简单地将其留空,我可以继续运行我的测试并保持我的重构帽子。
我可能需要应用任意数量的突出显示范围元素,因此我将让每个元素在其他元素之上进行组合。
class CodeHighlighter…
def apply_ranges lines
highlight_ranges.reduce(lines){|acc, each| apply_one_range(acc, each)}
end
def highlight_ranges
@data.css('highlight-range')
end
def apply_one_range lines, element
lines
end
你会看到我再次使用相同的技巧,我通过减少对每个突出显示范围元素运行 apply_one_range 的结果来实现 apply_ranges。我提供了一个保留现有行为的 apply_one_range 的初始实现,并可以继续戴着我的软呢帽。我正在做的是逐步缩小我即将添加的行为变化的范围。
在这一点上,我为突出显示范围条件添加了一个无操作测试。
class CodeHighlighterTester…
def test_highlight_range_noop
e = '<highlight-range start-line = "(date == null)" end-line = "}"/>'
assert_equal hunks['input'], with_highlights(form_element(e))
end
这可能看起来是一个奇怪的举动,本质上这个测试只是说,当我添加一个突出显示范围元素时,我不希望输出有任何变化。这是一个临时的测试,只是在我进行准备重构时使用。在我进行重构时,我假设我正在进行的重构不会导致任何变化,即使元素存在也是如此。因此,我想用一个测试来确认这个假设,因为编写起来很容易。(这遵循我的一个一般规则:如果我曾经想运行代码并查看一些输出以查看事情是否正确,我应该编写一个测试。有了测试,计算机可以检查输出是否正确,因此我不必这样做。)
我的下一步是回到高亮器本身。我现在已经隔离了一个方法来突出显示单个范围。我认为下一步要做的是确定我想添加开始标记的行,并将这些行分成三个列表:匹配行之前、单独的行和匹配行之后。我稍后会处理结束标记。
class CodeHighlighter…
def apply_one_range lines, element
start_ix = lines.find_index {|line| line =~ Regexp.new(element['start-line'])}
pre = 0 == start_ix ? [] : lines[0..(start_ix - 1)]
start = [lines[start_ix]]
rest = lines.size == (start_ix + 1) ? [] : lines[(start_ix + 1)..-1]
return pre + start + rest
end
这个重构的本质是分解文本并将其重新组合在一起,直到我将其分解到正确的位置,以便插入新的行为。
通过这样做,我可以测试我是否可以正确地将行列表分解成几部分并将其重新组合在一起。由于并不总是存在三个部分,因此这比你最初想象的要麻烦一些。由于我不得不添加条件逻辑来检查范围是否从第一行或倒数第二行开始,因此我添加了一些测试来检查这些情况。
到目前为止,我只检查了开始部分,并且几乎准备好实际改变可观察的行为,但首先我需要将 html span 字符串移动到对象范围内的某个位置。
class CodeHighlighter…
def apply_markup line, element open = "<span class = 'highlight'>" close = "</span>" if element.key? 'span' r = Regexp.new(element['span']) m = r.match line raise "unable to match span %s" % element['span'] unless m m.pre_match + opening + m[0] + closing + m.post_match else opening + line.chomp + closing + "\n" end end def opening "<span class = 'highlight'>" end def closing "</span>" end
我可以将它们设为常量,但我习惯在这种情况下使用方法。 [2]
现在我终于准备好戴上我的安全帽了,我需要做的改变太微不足道,以至于很容易。
class CodeHighlighter…
def apply_one_range lines, element
start_ix = lines.find_index {|line| line =~ Regexp.new(element['start-line'])}
raise "unable to match %s in code insert" % element['start-line'] unless start_ix
pre = 0 == start_ix ? [] : lines[0..(start_ix - 1)]
start = [opening + lines[start_ix]]
rest = lines.size == (start_ix + 1) ? [] : lines[(start_ix + 1)..-1]
return pre + start + rest
end
我现在删除了我在几分钟前添加的无操作测试,并修改了跳过的测试,使其只包含开始部分。
class CodeHighlighterTester…
def test_highlight_range
skip
e = '<highlight-range start-line = "(date == null)" end-line = "}"/>'
assert_equal hunks['range'], with_highlights(form_element(e))
end
codeHighlighterHunks.txt…
%% range
private void validateDate(Notification note) {
<span class = 'highlight'> if (date == null) {
note.addError("date is missing");
return;
}</span>
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
这个测试允许我在添加结束标记之前进行一些准备重构。
class CodeHighlighter…
def apply_one_range lines, element
start_ix = lines.find_index {|line| line =~ Regexp.new(element['start-line'])}
raise "unable to match %s in code insert" % element['start-line'] unless start_ix
finish_offset = lines[start_ix..-1].find_index do |line|
line =~ Regexp.new(element['end-line'])
end
raise "unable to match %s in code insert" % element['end-line'] unless finish_offset
finish_ix = start_ix + finish_offset
pre = 0 == start_ix ? [] : lines[0..(start_ix - 1)]
start = [opening + lines[start_ix]]
mid = (lines[(start_ix + 1)..(finish_ix -1)])
finish = [lines[finish_ix]]
rest = lines.size == (finish_ix + 1) ? [] : lines[(finish_ix + 1)..-1]
return pre + start + mid + finish + rest
end
这个方法对我来说有点长,但我不知道如何明智地缩短它。它确实保持了所有测试通过,并为我的最终简单更改做好了准备。
class CodeHighlighter…
def apply_one_range lines, element
start_ix = lines.find_index {|line| line =~ Regexp.new(element['start-line'])}
raise "unable to match %s in code insert" % element['start-line'] unless start_ix
finish_offset = lines[start_ix..-1].find_index do |line|
line =~ Regexp.new(element['end-line'])
end
raise "unable to match %s in code insert" % element['end-line'] unless finish_offset
raise "start and end match same line" unless finish_offset > 0
finish_ix = start_ix + finish_offset
pre = 0 == start_ix ? [] : lines[0..(start_ix - 1)]
start = [opening + lines[start_ix]]
mid = (lines[(start_ix + 1)..(finish_ix -1)])
finish = [lines[finish_ix].chomp + closing + "\n"]
rest = lines.size == (finish_ix + 1) ? [] : lines[(finish_ix + 1)..-1]
return pre + start + mid + finish + rest
end
最后的想法
我希望这个小片段让你对准备重构是什么样子有了一些了解。
对于每个想要的变化,先让变化变得容易(警告:这可能很难),然后再进行容易的变化。
-- Kent Beck
我通过创建一个简单的返回输入值的空操作函数来简化了更改,然后分解该函数,逐步将其分解,同时保持其空操作性。然后,一旦添加新功能变得简单,它就自然而然地融入其中。
每次准备重构的过程都不一样。有些只需要几分钟,有些可能需要几天。但我发现,当我能够找到如何进行准备重构的方法时,它会带来更快、更轻松的编程体验,因为便帽比安全帽更快、更轻松。
脚注
1: 这其中有一个有趣的讽刺,这种方法在描述像这样的重构时并不太有效。我仍然使用代码导入机制,因为我发现它在写作时将代码与文本分开很方便,但我必须从一个(已失效的)代码片段文件中导入它。
2: 你可能想知道这段代码是如何让我用删除线突出显示一些代码的,就像我在这里做的那样。我只是在写这篇文章时才在代码高亮器中添加了这个功能。(我是通过添加一个属性来指定一个 CSS 类来实现的。)
重大修订
2015 年 1 月 5 日: 首次发布