
语言工作台:领域特定语言的杀手级应用?
软件开发中的大多数新想法实际上都是旧想法的新变体。本文介绍了其中之一,即我称之为语言工作台的一类工具的兴起 - 例如 Intentional Software、JetBrains 的元编程系统和微软的软件工厂。这些工具采用了一种旧的开发风格 - 我称之为面向语言编程,并使用 IDE 工具来使面向语言编程成为一种可行的方法。虽然我不敢断言它们是否会成功实现其目标,但我确实认为这些工具是软件开发领域中最有趣的事物之一。它们有趣到足以让我写这篇文章来尝试解释,至少是概述,它们是如何工作的以及围绕它们未来用途的主要问题。
2005 年 6 月 12 日

长期以来,一直存在一种软件开发风格,它试图使用一组领域特定语言来描述软件系统。你在 Unix 的“小型语言”传统中看到了这一点,这些语言通过 lex 和 yacc 生成代码;你在 Lisp 社区中看到了在 Lisp 内部开发的语言,通常是在 Lisp 宏的帮助下。这种方法深受其倡导者的喜爱,但这种思维方式并没有像许多人希望的那样流行起来。
在过去几年中,人们尝试通过一类新的软件工具来支持这种开发风格。其中最早和最著名的是 Intentional Programming - 最初由 Charles Simonyi 在微软工作时开发。然而,也有人在做类似的事情,这足以引起人们对这种方法的兴趣。
在这里,我将创造一些将在本文其余部分使用的术语。像往常一样,这个领域没有标准的术语,所以不要指望我使用的术语在其他地方也是这样使用的。我将在这里给出一个简要的定义,但会在文章的后面详细解释它们 - 所以如果你没有立即理解这些定义,也不要担心。
我专门为本文创造的两个主要术语是“面向语言编程”和“语言工作台”。我使用**面向语言编程**来指代围绕构建围绕一组领域特定语言的软件这一理念进行的通用开发风格。我使用**语言工作台**作为这类新型工具的通用术语。因此,语言工作台是进行面向语言编程的一种方式。你可能也不熟悉**领域特定语言**(通常缩写为**DSL**)这一术语。它是一种专为特定类别的问题设计的有限形式的计算机语言。有些社区喜欢只将 DSL 用于问题领域语言,但我遵循的是将 DSL 用于任何有限领域的用法。
我将首先通过一个例子、对不同风格的概述以及关于该方法优缺点的各种论点来简要描述面向语言编程的现状。如果你熟悉面向语言编程,你可能想跳过这些内容,但我发现许多(实际上是大多数)开发人员并不熟悉这些概念。一旦解释了这些内容,我将以此为基础来解释什么是语言工作台以及它们如何改变权衡。
在我写这篇文章的时候,它已经超出了一篇文章的范围,所以我将讨论的某些部分分离到了其他文章中。我会在文中提到哪些地方可以继续阅读,它们也在目录下方链接。特别是,请查看使用 MPS 的示例 - 这展示了一个使用当前语言工作台构建的 DSL 示例,并且可能是了解它们将是什么样子的最佳方式。你需要先了解这里对语言工作台的一般描述,然后才能理解它。
面向语言编程的简单示例
我将首先通过一个非常简单的面向语言编程示例以及导致它的情况来开始。假设我们有一个读取文件的系统,需要根据这些文件创建对象。文件格式是每行一个对象。每行可以映射到一个不同的类,该类由行首的四个字符代码表示。该行的其余部分包含类的字段的数据,这些数据根据我们讨论的是哪个类而有所不同。字段由位置而不是分隔符指示。因此,客户 ID 号码可能从字符 4-8 开始。
以下是一些示例数据
#123456789012345678901234567890123456789012345678901234567890 SVCLFOWLER 10101MS0120050313......................... SVCLHOHPE 10201DX0320050315........................ SVCLTWO x10301MRP220050329.............................. USGE10301TWO x50214..7050329...............................
点表示一些难以理解的、不感兴趣的数据。顶部的注释行是为了帮助你查看字符位置。前四个字符表示数据的类型 - SVCL 表示服务调用,USGE 表示使用记录。后面的字符表示对象的数据。因此,服务调用中从位置 5 到 18 的字符表示客户的姓名。
为了将它们转换为对象,你可能会试图为每种情况编写特定的代码,我希望在编写了一些代码之后,你会希望通过编写一个可以使用每个类的字段详细信息进行参数化的单个读取器类来简化任务。
这里我有一个简单的类来做到这一点。读取器类读取文件。读取器可以使用读取器策略类的集合进行参数化 - 每个目标类一个。因此,对于我们的示例,我们将有一个用于服务调用的策略,另一个用于使用情况。我将策略保存在一个以代码为键的映射中。
以下是处理文件的代码
class Reader...
public IList Process(StreamReader input) {
IList result = new ArrayList();
string line;
while ((line = input.ReadLine()) != null)
ProcessLine(line, result);
return result;
}
private void ProcessLine(string line, IList result) {
if (isBlank(line)) return;
if (isComment(line)) return;
string typeCode = GetTypeCode(line);
IReaderStrategy strategy = (IReaderStrategy)_strategies[typeCode];
if (null == strategy)
throw new Exception("Unable to find strategy");
result.Add(strategy.Process(line));
}
private static bool isComment(string line) {
return line[0] == '#';
}
private static bool isBlank(string line) {
return line == "";
}
private string GetTypeCode(string line) {
return line.Substring(0,4);
}
IDictionary _strategies = new Hashtable();
public void AddStrategy(IReaderStrategy arg) {
_strategies[arg.Code] = arg;
}
它只是循环遍历每一行,读取足够的信息以确定要调用哪个策略,然后将其交给策略来完成工作。要让读取器完成这项工作,你需要创建一个新的读取器,为其加载策略,然后让它处理你想要处理的文件。
策略也可以是可参数化的。我们只需要一个策略类,当我们实例化它时,我们可以使用代码、目标类以及输入上的哪些字符位置映射到目标类上的哪些字段的详细信息对其进行参数化。我将后者保存在一个字段提取器类列表中。
class ReaderStrategy...
private string _code;
private Type _target;
private IList extractors = new ArrayList();
public ReaderStrategy(string code, Type target) {
_code = code;
this._target = target;
}
public string Code {
get { return _code; }
}
实例化策略后,我可以向其中添加字段提取器。
class ReaderStrategy...
public void AddFieldExtractor(int begin, int end, string target) {
if (!targetPropertyNames().Contains(target))
throw new NoFieldInTargetException(target, _target.FullName);
extractors.Add(new FieldExtractor(begin, end, target));
}
private IList targetPropertyNames() {
IList result = new ArrayList();
foreach (PropertyInfo p in _target.GetProperties())
result.Add(p.Name);
return result;
}
为了处理该行,策略创建目标类并使用提取器获取字段数据
class ReaderStrategy...
public object Process(string line) {
object result = Activator.CreateInstance(_target);
foreach (FieldExtractor ex in extractors)
ex.extractField(line, result);
return result;
}
提取器只是从该行的正确位置提取数据,并使用反射将值放入目标对象中。
class FieldExtractor...
private int _begin, _end;
private string _targetPropertyName;
public FieldExtractor(int begin, int end, string target) {
_begin = begin;
_end = end;
_targetPropertyName = target;
}
public void extractField(string line, object targetObject) {
string value = line.Substring(_begin, _end - _begin + 1);
setValue(targetObject, value);
}
private void setValue(object targetObject, string value) {
PropertyInfo prop = targetObject.GetType().GetProperty(_targetPropertyName);
prop.SetValue(targetObject, value, null);
}
到目前为止,我所描述的是一个非常简单的库,用于完成这类事情。本质上,我已经构建了一个抽象,然后我可以使用它来指定具体的工作。为了使用抽象,我需要配置策略并将它们加载到读取器中。以下是两个示例用例的示例。
public void Configure(Reader target) {
target.AddStrategy(ConfigureServiceCall());
target.AddStrategy(ConfigureUsage());
}
private ReaderStrategy ConfigureServiceCall() {
ReaderStrategy result = new ReaderStrategy("SVCL", typeof (ServiceCall));
result.AddFieldExtractor(4, 18, "CustomerName");
result.AddFieldExtractor(19, 23, "CustomerID");
result.AddFieldExtractor(24, 27, "CallTypeCode");
result.AddFieldExtractor(28, 35, "DateOfCallString");
return result;
}
private ReaderStrategy ConfigureUsage() {
ReaderStrategy result = new ReaderStrategy("USGE", typeof (Usage));
result.AddFieldExtractor(4, 8, "CustomerID");
result.AddFieldExtractor(9, 22, "CustomerName");
result.AddFieldExtractor(30, 30, "Cycle");
result.AddFieldExtractor(31, 36, "ReadDate");
return result;
}
我认为这是两种不同的代码风格。Reader 和 Strategy 类是一个抽象,最后这段代码是配置。当你构建这类库类时,考虑这两个部分通常会有所帮助:抽象和配置。抽象可以是一个类库、一个框架,或者只是一组函数调用。抽象可以在许多项目中重用,但它不一定是可重用的。配置代码往往是特定于项目的;相当简单、直接的代码。
由于配置非常简单,并且比抽象更容易更改,因此一种常见的方法是进一步分离它,并将配置完全从 C# 中移除。目前的做法是将其放在 XML 文件中。
<ReaderConfiguration>
<Mapping Code = "SVCL" TargetClass = "dsl.ServiceCall">
<Field name = "CustomerName" start = "4" end = "18"/>
<Field name = "CustomerID" start = "19" end = "23"/>
<Field name = "CallTypeCode" start = "24" end = "27"/>
<Field name = "DateOfCallString" start = "28" end = "35"/>
</Mapping>
<Mapping Code = "USGE" TargetClass = "dsl.Usage">
<Field name = "CustomerID" start = "4" end = "8"/>
<Field name = "CustomerName" start = "9" end = "22"/>
<Field name = "Cycle" start = "30" end = "30"/>
<Field name = "ReadDate" start = "31" end = "36"/>
</Mapping>
</ReaderConfiguration>
XML 有其用途,但并不容易阅读。我们可以通过使用自定义语法使其更容易理解。也许像这样
mapping SVCL dsl.ServiceCall 4-18: CustomerName 19-23: CustomerID 24-27 : CallTypeCode 28-35 : DateOfCallString mapping USGE dsl.Usage 4-8 : CustomerID 9-22: CustomerName 30-30: Cycle 31-36: ReadDate
由于你现在已经熟悉了这个问题,所以你应该能够在没有我帮助的情况下阅读语法。
当你查看最后一个示例时,你可以看到我们这里有一个非常小的编程语言 - 它(只)适用于将固定长度字段映射到类。它是 Unix 传统中“小型语言”的典型例子。它是用于该任务的领域特定语言。
这种语言是一种领域特定语言,并且具有 DSL 的许多特征。首先,它只适用于非常狭窄的用途 - 它除了将这些特定的固定长度记录映射到类之外,什么也做不了。因此,DSL 非常简单 - 没有控制结构或其他任何东西的工具。它甚至不是图灵完备的。你不能用这种语言编写整个应用程序 - 你所能做的只是描述应用程序的一小部分。因此,DSL 必须与其他语言结合使用才能完成任何事情。但 DSL 的简单性意味着它易于编辑和翻译。(我将在稍后详细介绍 DSL 的优缺点。)
现在再看看 XML 表示。这是一种 DSL 吗?我认为它是。它采用 XML 语法 - 但它仍然是一种 DSL - 事实上,在许多方面它与前面的示例是相同的 DSL。
现在是介绍编程语言领域中常见区别的好时机 - 抽象语法和具体语法的区别。语言的**具体语法**是我们在其表示中看到的语法。XML 和自定义语言文件具有不同的具体语法。然而,两者都具有相同的基本结构:你有多个映射,每个映射都有一个代码、一个目标类名和一组字段。这种基本结构是**抽象语法**。当大多数开发人员考虑编程语言语法时,他们不会做出这种区分,但当你使用 DSL 时,这是一个重要的区分。你可以从两个方面来理解这一点。你可以说我们有一种语言有两种具体语法,或者说两种语言共享相同的抽象语法。
因此,这个例子提出了一个设计问题 - 为 DSL 使用自定义具体语法还是 XML 具体语法更好。XML 语法可能更容易解析,因为有这么多可用的 XML 工具;尽管在这种情况下,自定义语法实际上更容易。我认为自定义语法更容易阅读,至少在这种情况下是这样。但无论你如何看待这种选择,围绕 DSL 的核心权衡都是一样的。事实上,你可以说任何 XML 配置文件本质上都是 DSL。
让我们再往前走一步,回到 C# 中的配置代码 - 这是一种 DSL 吗?
当你想到这一点时,请看这段代码。这看起来像解决这个问题的 DSL 吗?
mapping('SVCL', ServiceCall) do
extract 4..18, 'customer_name'
extract 19..23, 'customer_ID'
extract 24..27, 'call_type_code'
extract 28..35, 'date_of_call_string'
end
mapping('USGE', Usage) do
extract 9..22, 'customer_name'
extract 4..8, 'customer_ID'
extract 30..30, 'cycle'
extract 31..36, 'read_date'
end
第二段代码与 C# 代码相关。熟悉我语言偏好的人可能已经猜到,最后一个例子实际上是 Ruby 代码。事实上,它与 C# 示例在功能上完全等效。由于 Ruby 的各种特性:最小侵入式语法、范围字面量和灵活的运行时求值,它看起来更像是一种自定义 DSL。这是一个完整的配置文件,可以在运行时读取并在对象实例的范围内进行求值。但它仍然是纯粹的 Ruby 代码,并通过方法调用 mapping 和 extract 与框架代码交互,这两个方法分别对应于 C# 示例中的 AddStrategy 和 AddFieldExtractor。
我认为 C# 和 Ruby 示例都是 DSL。在这两种情况下,我们都使用了宿主语言的一部分功能,并使用我们的 XML 和自定义语法来表达相同的思想。本质上,我们是将 DSL 嵌入到我们的宿主语言中,使用宿主语言的一个子集作为我们抽象语言的自定义语法。在某种程度上,这更多的是一种态度问题,而不是其他任何问题。我选择从面向语言编程的角度来看待 C# 和 Ruby 代码。但这种观点由来已久——Lisp 程序员经常考虑在 Lisp 中创建 DSL。这些内部 DSL 的权衡显然不同于外部 DSL,但仍有许多相似之处。(稍后我也会详细说明这些权衡)。
现在我已经展示了一个 DSL 的例子,我可以更好地定义面向语言编程。面向语言编程是关于通过多个 DSL 来描述一个系统。它是一个渐进的过程,你可以在一个系统中使用少量的面向语言编程,其中只有一部分功能是用 DSL 表示的;或者你也可以用 DSL 表示大部分功能,并大量使用面向语言编程。你使用了多少面向语言编程是很难衡量的,特别是当你使用语言内部的 DSL 时。通常,就像任何可重用代码一样,你自己编写一些 DSL,并使用来自其他地方的其他 DSL。
面向语言编程的传统
正如我的例子所示,面向语言编程并不是什么新鲜事——人们已经进行面向语言编程相当长一段时间了。因此,在我们关注语言工作台为我们带来了什么之前,有必要先了解一下面向语言编程的现状。
目前,面向语言编程的风格有很多种。现在是总结其中几种风格的好时机。
Unix 小型语言
世界上最明显的 DSL 之一是 Unix 传统中编写小型语言。这些是外部 DSL 系统,通常使用 Unix 的内置工具来帮助翻译。在大学期间,我玩过一点 lex 和 yacc——类似的工具是 Unix 工具链的常规部分。这些工具使得编写解析器和为小型语言生成代码(通常是 C 语言)变得容易。Awk 就是这种小型语言的一个很好的例子。
Lisp
Lisp 可能是直接用语言本身表达 DSL 的最好例子。符号处理既体现在 Lisp 的名称中,也体现在 Lisp 的实践中。Lisp 的功能有助于实现这一点——极简的语法、闭包和宏提供了一种令人兴奋的 DSL 工具组合。Paul Graham 写了很多关于这种开发风格的文章。Smalltalk 在这种开发风格方面也有着悠久的传统。
活动数据模型
如果你遇到一些更复杂的数据建模人员,他们会告诉你如何通过数据库表中的数据(通常称为元数据表或表驱动程序)对系统中高度可变的部分进行编码。然后,代码可以解释表中的数据以执行行为。
这本质上是一种 DSL,其具体语法是数据库表。通常,这些表是通过某种形式的 GUI 界面来管理的,以编辑这些活动数据。通常,这样做的人不会考虑创建一种语言,而且通常与关系型具体语法打交道的难度有助于保持语言的小巧和专注。
自适应对象模型
与足够多的硬核面向对象程序员交谈,他们会告诉你他们构建的系统是如何依赖于将对象组合成灵活而强大的环境的。这种系统由复杂的领域模型构建而成,其中大部分行为来自将对象连接到配置中,以处理各种复杂情况。面向对象的人将自适应对象模型视为增强版的活动数据模型。
这种自适应模型是一种语言内部的 DSL。迄今为止的经验表明,一旦模型开发完成并经过检验,它们可以让熟悉自适应模型的人员获得极高的生产力。不利的一面是,这种模型通常很难让新手理解。
XML 配置文件
访问一个现代 Java 项目,你会发现系统中的 XML 比 Java 还多,这情有可原。企业 Java 系统使用了一系列框架,其中大多数框架都拥有复杂的 XML 配置文件。这些文件本质上是 DSL。XML 使得解析变得容易,尽管不像自定义格式那样易于阅读。对于那些觉得尖括号刺眼的人来说,人们确实会为 IDE 编写插件来帮助操作 XML 文件。
GUI 构建器
自从人们开始构建 GUI 以来,就一直存在着允许你通过拖放控件来布局 GUI 的系统。Visual Basic 可能是最著名的例子,但早在 GUI 普及之前,我就已经将类似的屏幕构建器用于字符屏幕。这些工具要么以封闭格式存储布局,生成适合执行的代码;要么尝试将所有必要的信息放入生成的代码中。虽然它们在视觉上很不错,但我们越来越多地看到,尽管这种交互方式可以进行吸引人的演示,但它也存在局限性。以至于许多经验丰富的 GUI 开发人员不鼓励在相当复杂的应用程序中使用 GUI 构建器。
GUI 构建器是 DSL 的一种形式,但其编辑体验与我们习惯的文本编程语言截然不同。因此,构建它们的人通常不认为它们是语言——有些人认为这是它们的问题所在。
面向语言编程的优缺点
回顾这些风格,我们可以看到各种形式的面向语言编程都非常流行。概括地说,我发现将它们分为两种更广泛的风格是很有用的。**外部 DSL** 使用与应用程序主要(宿主)语言不同的语言编写,并使用某种形式的编译器或解释器转换为宿主语言。Unix 小型语言、活动数据模型和 XML 配置文件都属于这一类。**内部 DSL** 将宿主语言本身转换为 DSL——Lisp 传统就是这方面的最佳例子。
我在本文中创造了“外部/内部”这两个术语,因为对于我认为有用的区别,目前还没有一对明确的术语。内部 DSL 通常被称为“嵌入式 DSL”,但我避免使用“嵌入式”一词,因为它与应用程序中的嵌入式语言(例如嵌入到 Word 中的 VBA,如果说它是什么的话,它就是一个外部 DSL)相混淆。然而,如果你查阅更多关于 DSL 的文章,你可能会遇到“嵌入式”一词。
外部 DSL 和内部 DSL 的权衡相当不同,因此最好分别进行 بررسی。
外部 DSL
我将外部 DSL 定义为使用与应用程序主要语言不同的语言编写的 DSL,例如我们简单示例中的最后两种形式。Unix 小型语言和 XML 配置文件就是这种风格的很好例子。
外部 DSL 的主要优势在于,你可以自由使用任何你喜欢的形式。因此,你可以在很大程度上以最容易阅读和修改的形式来表达领域。格式的限制只在于你构建一个能够解析配置文件并生成可执行内容(通常是用你的基础语言)的转换器的能力。
由此可见,一个明显的缺点是你必须构建这个转换器。对于像我上面展示的简单语言来说,这并不困难。虽然更复杂的语言会使其变得更加困难——但仍然没有那么糟糕。存在解析器生成器和编译器编译器工具,可以帮助你操作相当复杂的语言,当然,DSL 的重点在于它们通常都非常简单。XML 限制了 DSL 的形式,但使其非常容易解析。
外部 DSL 的一大缺点是它们缺乏我所说的**符号集成**——也就是说,DSL 并没有真正链接到我们的基础语言中。基础语言环境不知道我们在做什么。现在编程环境正变得越来越复杂,这正成为一个越来越严重的问题。
举一个简单的例子,假设我们想重命名我的简单示例中目标类上的属性。使用一流的现代 IDE,重命名的自动重构是司空见惯的。但这种重命名不会传播到 DSL 中。在 C# 世界和文件映射 DSL 之间存在着我所说的**符号障碍**。我们可以将映射转换为 C#,但这种障碍限制了我们操作整个程序的能力。
这种缺乏集成在工具方面给我们带来了很多困扰。首先——我们如何编辑 DSL?一个文本编辑器就可以完成这项工作——但现代 IDE 越来越使文本编辑器看起来很原始。我应该在字段名上获得一个弹出列表和补全,如果字符范围重叠,则应该显示红色波浪线。但要做到这一点,我需要一个能够理解我的 DSL 语义的编辑器。
也许我可以不用语义编辑器。但接下来想想调试。我的调试器可以单步执行 C# 转换后的代码,但不能进入真正的源代码本身。我真正想要的是一个功能齐全的 DSL IDE。在文本编辑器和简单调试器的时代,这不是什么大问题——但我们现在生活在一个后 IntelliJ时代。
对外部 DSL 的一个特别常见的反对意见是**语言杂乱**问题。这种担忧是,语言很难学习,因此使用多种语言将比使用单一语言复杂得多。在某种程度上,这种担忧是基于对 DSL 的误解。那些有这种担忧的人通常会想到多种通用语言,这确实很容易导致杂乱。但 DSL 往往是有限的、简单的,这使得它们更容易学习。它们与领域的接近性也加强了这一点。DSL 看起来不像常规的编程语言。
从根本上说,在任何规模合理的程序中,你都要处理一堆需要操作的抽象,例如介绍性示例中的文件读取示例。通常,我们使用对象和方法来操作这些抽象。这是可行的,但提供了一种有限的语法来表达我们想说的话(尽管有多有限取决于我们的基础语言)。使用外部 DSL 使我们有机会拥有一种更容易操作的语法。问题是,通过外部 DSL 操作所带来的额外便利是否大于首先理解新 DSL 的成本。
与此相关的问题是,人们担心设计 DSL 的难度——语言设计很难,因此对于大多数项目来说,设计多个 DSL 太难了。同样,这种反对意见通常是基于对通用语言而不是 DSL 的思考。我认为,这里的根本问题是获得一个好的抽象——这是任务中最难的部分。API 设计和 DSL 设计之间的区别其实很小——因此,我认为设计 DSL 不会比设计好的 API 难多少。
对于许多人来说,外部 DSL 的一大优势在于 DSL 可以在运行时进行求值。这使得经常更改的参数可以在不重新编译程序的情况下进行更改。这是 XML 配置文件在 Java 世界中如此流行的主要原因。虽然这对于静态编译语言来说是一个重要问题,但重要的是要记住,许多语言可以很容易地在运行时对表达式进行求值,因此对它们来说这不是问题。人们对混合编译时语言和运行时语言的兴趣也越来越大,例如 .NET 中的 IronPython。这将允许你在一个主要使用 C# 的系统中对 IronPython 内部 DSL 进行求值。这是 Unix 世界中将 C/C++ 与脚本语言混合使用的一种常见技术。
内部 DSL
内部 DSL 与外部 DSL 相比,优缺点正好相反。我们可以使用基础语言来消除符号障碍。我们还可以随时使用基础语言的全部功能,以及基础语言中存在的所有工具。Lisp 和自适应对象模型是内部 DSL 的例子。
讨论这个问题的一个难点在于,主流的花括号编程语言(C、C++、Java、C#)与像 Lisp 这样特别适合内部 DSL 的语言之间存在很大差异。在 Lisp 或 Smalltalk 中,内部 DSL 风格比在 Java 或 C# 中更容易实现 - 事实上,动态语言的倡导者指出这是它们的主要优势之一。我们看到脚本语言正在重新发现其中的一些优势 - 比如 Ruby 的元编程能力 以及 Rails 框架 如何使用它们。这个问题更加复杂,因为许多程序员从未认真使用过动态语言,因此不了解它们的功能(以及真正的局限性)。
内部 DSL 受限于基础语言的语法和结构。更动态的语言受到的限制更少。它们具有最小侵入性的语法(例如 Lisp、Smalltalk 和脚本语言),往往比主流的花括号语言效果更好,当你比较 C# 和 Ruby 的例子时,这一点非常明显。闭包和宏等语言特性也很有价值。虽然基于 C 的语言缺少很多这样的机制,但我们看到了一些可以支持这种想法的特性。注解(C# 中的属性)就是一个很好的例子,说明这种语言特性对于这种目的非常有用。
虽然您可以使用基础语言的工具,但基础语言实际上并不知道您要用 DSL 做什么 - 因此这些工具不能完全支持 DSL。您仍然比使用文本编辑器要好,但还有很大的改进空间。
在 DSL 中可以使用语言的全部功能,这有利也有弊。如果您熟悉基础语言,那就没问题。然而,DSL 的优势之一是它允许人们在不知道完整基础语言的情况下进行编程 - 这使得非专业程序员更容易将特定领域的的信息直接输入到系统中。内部 DSL 可能会使这变得困难,因为如果用户不熟悉完整的基语言,他们会在很多地方感到困惑。
一种思考方式是,通用编程语言为您提供了许多工具 - 但您的 DSL 只使用了其中的一小部分。拥有比您需要的工具更多的工具通常会使事情变得更难 - 因为您必须先了解所有这些工具,然后才能弄清楚您使用的那几个工具。理想情况下,您只需要工作中实际需要的工具 - 当然不能少,但只需要多几个。(Charles Simonyi 在 自由度 的概念中讨论了这个想法。)
这里有一个关于办公工具的类比。许多人抱怨现代文字处理器太难用了,因为它们有数百种功能,远远超过任何一个人需要的功能。但由于所有这些功能都有人需要,因此办公程序最终会通过构建一个大型系统来满足所有人。另一种方法是使用多个办公工具,每个工具都专注于一项任务。这样,每个工具都更容易学习和使用。当然,问题在于构建所有这些专用办公工具的成本很高。这与通用编程语言(使用内部 DSL)和外部 DSL 之间的权衡非常相似。
由于内部 DSL 接近编程语言,因此当您想要表达一些不能很好地映射到编程语言本身的东西时,这可能会带来困难。例如,在企业应用程序中,通常会有层的概念。这些层可以在很大程度上通过使用编程语言的包结构来定义,但是很难定义层之间的依赖关系。因此,您可以将所有 UI 代码放在 MyApp.Presentation 中,将域逻辑放在 MyApp.Domain 中,但是内部 DSL 中没有机制可以指示 MyApp.Domain 中的类不应该引用 MyApp.Presentation 中的类。在某种程度上,这再次反映了常见语言的动态性有限 - 这种事情在 Smalltalk 中是可能的,因为您可以更深入地访问元级别。
(作为比较,看看我的 更复杂的例子 在其中一种动态语言中的开发将会很有趣。我可能不会去做,但我怀疑其他人可能会去做,如果是这样的话,我会更新 进一步阅读。)
让非程序员参与进来
贯穿两种面向语言编程形式的一个主题是 **非专业程序员** 的参与:领域专家不是专业程序员,而是作为开发工作的一部分在 DSL 中编程。非专业编程的目标一直是软件世界的永恒目标 - 事实上,许多人认为早期的 高级语言(COBOL 和 FORTRAN)预示着程序员的终结,因为用户将使用它们。这让我们想起了我所说的 **COBOL 推论** - 大多数旨在淘汰专业程序员的技术都没有做到这一点。
尽管有 COBOL 推论,但人们确实不时成功地将用户的直接输入纳入程序中。一种方法是找出问题的一部分,这部分足够简单和有限,用户可以安全舒适地在这个空间中编程。然后,您将这些用户可编程区域中的每一个都变成一个 DSL。这些 DSL 可能非常复杂 - MatLab 就是一个很好的例子,它是一个非常复杂的 DSL,之所以有效是因为它专注于一个领域。
对于用户可编程的 DSL,外部 DSL 的优势在于您可以放弃宿主语言的所有包袱,并呈现对用户来说非常清晰的东西。这对于语法更严格的语言尤其重要。但即使使用简单的语言,您也会遇到内部 DSL 的问题,即用户很容易做一些在语言中有意义但在 DSL 范围之外的事情。这会让用户对看起来很奇怪的行为和难以理解的错误消息感到困惑。
许多面向语言编程的支持者都对未来抱有这样的愿景:系统的 所有领域逻辑都由用户完成。然后,程序员编写必要的支持工具,让他们能够编辑和编译这些程序。虽然这并不意味着专业程序员的终结 - 但这将大大减少您需要的程序员数量(因为这些工具中的大部分都是可重用的),并且将消除当今阻碍软件开发的许多沟通问题。这种非专业程序员的愿景很有吸引力 - 但 COBOL 推论却在嘲弄着它。
最后,我认为非专业编程是一件很有价值的事情,但这并不是面向语言编程的全部意义所在。一个好的 DSL 可以让专业程序员提高工作效率,即使它没有被用户程序员所接受。一个好的 DSL 最终可能需要专业程序员来编写 - 但可以由领域专家进行有用的审查。
非专业程序员的论点是一个高风险的赌注。如果有人主要根据支持大规模用户编程来证明某种技术的合理性,我会充满怀疑。然而,如果这种方法能够成功,它将带来巨大的好处。这并不是因为淘汰了专业程序员,而是因为改善了领域专家和程序员之间通常很糟糕的沟通状况。这种缺乏沟通往往是软件开发项目中最大的障碍。
总结面向语言编程的权衡
对我来说,面向语言编程的根本问题是使用 DSL 的好处与构建有效支持它们的必要工具的成本之间的权衡。使用内部 DSL 降低了工具成本 - 但由此产生的对 DSL 本身的限制也会大大降低好处,特别是当您局限于基于 C 的语言时。外部 DSL 为您提供了最大限度地实现效益的潜力,但设计语言、构建翻译器以及考虑支持编程的工具的成本更高。
这就是为什么面向语言编程没有流行起来的原因。语言内和语言外技术都有明显的缺点。因此,存在着一种挥之不去的差距 - 一种感觉,我们应该能够用 DSL 做更多的事情,而不是我们目前所做的。
这就很好地引出了语言工作台的理由。从本质上讲,语言工作台的承诺是,它们提供了外部 DSL 的灵活性,而没有语义障碍。此外,它们还可以轻松构建与现代 IDE 相媲美的工具。其结果是使面向语言编程更容易构建和支持,降低了使面向语言编程对许多人来说如此尴尬的障碍。
今天的语言工作台
我将首先简要介绍一些我遇到过的属于语言工作台类别的工具。请记住,所有这些工具都处于开发的早期阶段。我们还需要几年的时间才能看到可用于大规模软件开发的语言工作台。
Intentional Software
这些工具的鼻祖是有意编程。有意编程最初是由微软研究院的 Charles Simonyi 开发的。几年前,Simonyi 离开了微软,创建了自己的公司,独立开发 有意软件。与这类初创公司一样,他一直不太愿意公开开发进展。因此,关于有意软件中有什么以及如何使用它的信息非常少。
我有机会花了一点时间研究有意软件,而且我在 Thoughtworks 的几位同事在过去一年左右的时间里与有意软件公司进行了密切的合作。因此,我有机会一窥有意软件的幕后 - 尽管我对我所看到的内容的描述受到限制。幸运的是,他们打算在未来一年左右的时间里开始公开他们的工作。
(作为术语说明,有意软件公司使用“有意编程”一词来指代他们在微软所做的早期工作,而使用“有意软件”来指代他们自那以后所做的事情。)
元编程系统
一个更新的举措是由 JetBrains 开发的 元编程系统。JetBrains 因其卓越的 IDE 工具而在软件开发人员中享有盛誉。
JetBrains 在 IDE 方面的经验与语言工作台相关,这体现在两个方面。首先,他们在 IntelliJ 方面的成功为他们在工具领域赢得了很高的声誉 - 无论是在技术能力方面,还是在务实精神方面。其次,语言工作台的许多功能都与使后 IntelliJ 时代 IDE 如此强大的功能紧密相连。
JetBrains 花了几年时间构建了一个用于开发 Web 应用程序的复杂环境,称为 Fabrique。构建 Fabrique 的经验让他们相信,他们需要一个平台来更有效地构建这类工具 - 这种愿望促使他们开发了 MPS。
MPS 深受有意软件公开内容的影响。它的开发时间比有意软件的工作要短得多,但 JetBrains 相信非常开放的开发周期。一旦他们有了一些可用的东西,他们就会在早期访问计划下提供 MPS。目前,他们希望在 2005 年上半年做到这一点。
我很幸运最近与 MPS 的负责人 Sergey Dmitriev 密切合作。MPS 活动来自 JetBrains 的马萨诸塞州办事处,这让我很容易拜访他们。由于这种地理上的相似性和他们的开放性,我使用 MPS 帮助描述了一些 详细的例子(尽管在我进一步完成这篇文章之前,它们不会有什么意义。别担心,我会在适当的时候再次给你链接。)
软件工厂
软件工厂是由微软的 Jack Greenfield 和 Keith Short 发起的一项计划。软件工厂涉及多个方面,我在这里不作详细介绍(只是说不要被这个糟糕的名字吓跑)。与本文相关的方面是 DSL 工作——面向语言编程在软件工厂中扮演着重要角色。
软件工厂团队拥有模型驱动开发的背景。他们中既有积极参与 CASE 工具开发的人员,也有许多英国面向对象社区的领军人物。因此,他们的 DSL 倾向于更图形化的方式也就不足为奇了。然而,与大多数 CASE 工具人员不同的是,他们对语义和代码生成的控制非常感兴趣。
我在这里讨论的大部分内容都是指应用程序的传统编程。软件工厂团队还对将 DSL 用于软件开发的其他领域非常感兴趣,这些领域通常不会自动化,例如部署、测试和文档。他们还在探索模拟器,用于您不想在开发中直接执行 DSL 的情况,例如部署 DSL。
几个月来,微软的 DSL 团队一直在提供作为 Visual Studio 2005 Team System 一部分的下载。
模型驱动架构 (MDA)
如果您一直在跟踪 OMG 的 MDA,您会注意到我一直在谈论的语言工作台与 MDA 愿景之间有许多相似之处。这是一个有争议的问题,但现在我要说的是,MDA 的某些愿景是语言工作台的形式,但并非所有愿景都是如此。我还想说,我认为在 MDA 之上构建语言工作台存在严重缺陷。我写了一篇相关文章来更详细地讨论这个问题,但在您读完这篇文章之前,它不会有什么意义。
语言工作台的要素
尽管这些工具各不相同,但它们确实有一些共同的特征和相似的部分。
语言工作台最强大的优势之一是,它们改变了编辑和编译程序之间的关系。从本质上讲,它们从编辑文本文件转变为编辑程序的抽象表示。让我用几段话来解释最后一句话。
在传统编程中,我们使用文本编辑器编辑文本文件中的程序文本。然后,我们通过运行将这些文本文件转换为计算机可以理解和执行的内容的转换器,使该文件可执行。这种转换可以在执行时进行,例如 Python 或 Ruby 等脚本语言,也可以作为编译语言(例如 Java、C# 和 C)的单独步骤进行。
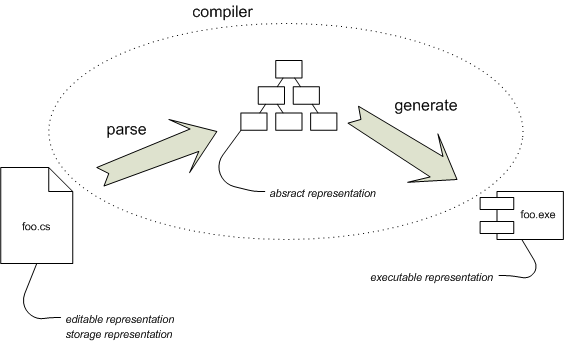
图 1:传统编译的概要。
让我把这个过程分解一下。图 1显示了编译过程的简化视图。为了将 foo.cs 转换为可执行文件,我们在其上运行编译器。为了便于讨论,我们可以将编译过程分为两个步骤。第一步从文件 foo.cs 中获取文本并将其解析为抽象语法树 (AST)。第二步遍历此树,生成 CLR 字节码并将其放入程序集(exe 文件)中。
{kind=link}
我们可以将程序视为具有多种表示形式,编译器在这些表示形式之间进行转换。源文件是可编辑表示形式,也就是说,这是我们想要更改程序时操作的表示形式。它也是存储表示形式,即保存在源代码管理中的表示形式,如果我们想再次访问程序,可以使用它。当我们运行编译器时,第一阶段将可编辑表示形式映射到抽象表示形式(抽象语法树),然后代码生成器将其转换为可执行表示形式(CLR 字节码)。
(在可执行代码真正成为最终可执行文件之前,还有更多的转换。但是,一旦我们有了字节码,编译器的工作就完成了,剩下的所有内容都留给其范围之外的后续阶段。)
抽象表示形式非常短暂——它只在编译器运行时存在,并且仅用于将编译分为两个逻辑步骤。当然,这种短暂性也是外部 DSL 之间难以实现符号集成的很大一部分原因。每种语言都经过单独的编译,因此抽象表示形式之间没有链接。只有在生成代码时,事物才会结合在一起,此时关键的抽象就会丢失。
更复杂的 IntelliJ 后 IDE 为此模型带来了重大变化。当 IDE 加载文件时,它会在内存中创建一个抽象表示形式,用于帮助您编辑文件。(Smalltalk 也做了一个有限的版本。)这种抽象表示形式有助于完成简单的事情,例如方法名称完成,以及复杂的事情,例如重构(自动重构是对抽象表示形式的转换)。
我的同事 Matt Foemmel 描述了有一次他在 IntelliJ 中工作时,这种情况是如何让他印象深刻的。他做了一个由这些功能大力协助的更改,突然意识到他不是在键入文本,而是在对抽象表示形式运行命令。尽管 IDE 将抽象表示形式中的这些更改转换回了文本,但他真正操作的是抽象表示形式。如果您在使用现代 IDE 时也有类似的感觉,那么您就会明白语言工作台的作用。
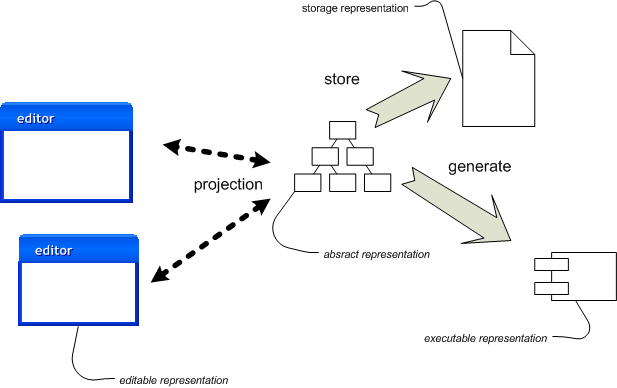
图 2:使用语言工作台操作表示形式。
图 2显示了此过程如何与语言工作台一起工作。这里的关键区别在于“源”不再是可编辑的文本文件。您操作的关键源是抽象表示形式本身。为了对其进行编辑,语言工作台将抽象表示形式投影到某种形式的可编辑表示形式中。但是,这种可编辑的表示形式纯粹是短暂的——它只是为了帮助人类。真正的来源是持久的抽象表示形式。
{kind=link}
可编辑表示形式仅仅是抽象表示形式的投影这一事实引出了几点。也许最重要的是,可编辑表示形式不需要完整——如果抽象表示形式的某些方面对当前任务不重要,则可以省略它们。此外,您可以拥有多个投影,每个投影都显示抽象表示形式的不同方面。由于投影位于语言工作台中,因此可编辑表示形式比文本文件更加活跃。这种**投影编辑器**与语言本身紧密相连。因此,在考虑可编辑表示形式时,您会积极地考虑编辑器如何处理它们。这会导致与您从纯被动可编辑表示形式(例如文本)获得的想法不同。
语言工作台将存储表示形式与可编辑表示形式分开。存储表示形式现在是抽象表示形式的序列化。一种常见的方法是使用 XML,但这种 XML 不是为人工编辑而设计的。将 XML 作为存储表示形式有助于工具互操作性,尽管这种互操作性可能非常困难。
代码生成几乎相同,尽管此类工具可能会将传统源代码视为可执行表示形式。如果它们确实生成了常规语言源文件,则这些文件实际上并不是源文件,并且像其他生成的代码一样,不应直接编辑。随着语言工作台的成熟,我们应该会看到更多地依赖于生成不可编辑的结构,例如字节码。
语言工作台的一个不明显但很重要的特性是,抽象表示形式必须能够容忍错误和歧义。传统上,人们认为,如果您要使用抽象表示形式,则需要保持其正确性——您不应该能够在其中放入不正确的信息。然而,这种假设导致了糟糕的可用性。IntelliJ 后的 IDE 意识到了这一点,并对错误状态做出了优雅的反应。例如,您可以对具有编译错误的程序执行重构(这对良好的可用性非常必要)。
如果您想从多个来源捕获复杂信息,这一点就变得更加重要。您不可能始终保持所有内容的一致性和正确性。因此,您必须处理模糊和错误的状态——突出显示错误而不是拒绝输入。您还应该允许人们轻松地将不可计算的信息(例如文档)输入到模型中。这样,扫描的餐巾纸就可以直接链接到生成的 DSL 代码。
定义新的 DSL
有了这种设置,定义新的 DSL 主要有三个部分
- 定义抽象语法,即抽象表示形式的**模式**。
- 定义一个**编辑器**,让人们可以通过投影来操作抽象表示形式。
- 定义一个**生成器**。这描述了如何将抽象表示形式转换为可执行表示形式。在实践中,生成器定义了 DSL 的语义。
这是主要的三要素,但会有所变化。正如我之前指出的,您没有理由不能为 DSL 使用多个编辑器或生成器。多个编辑器可能很常见。不同的人可能喜欢不同的编辑体验。例如,Intentional 的编辑器允许您轻松地在同一模型的不同投影之间切换,以便您可以将分层数据结构视为 lispy 列表、嵌套框或树。
出现多个生成器的原因可能有多种。您可能希望它们绑定到执行类似操作的不同框架。SQL 的多种方言就是一个很好的例子。另一个原因是为了不同的实现权衡,具有不同的性能特征或库依赖关系。第三个原因是生成不同的语言:例如,允许单个 DSL 生成 Java 或 C#。
另一个可选的额外功能可能是为存储表示形式定义转换器。我们可以假设语言工作台将附带一个默认的存储模式,该模式可以自动处理抽象表示形式的序列化。但是,您可能希望生成替代的存储表示形式,以实现互操作性或工具之间的传输。与生成器不同,这必须是双向表示形式。
另一种生成器将定义人类可读的文档——语言工作台相当于 javadoc。尽管与语言工作台的大多数交互将通过编辑器进行,但仍然需要生成 Web 或纸质文档。
定义语言工作台
目前还没有普遍接受的定义来界定什么是语言工作台。这并不奇怪,因为这个词是我在这篇文章中刚刚创造出来的!但我认为,为了避免软件行业中许多主题(例如组件、面向服务的体系结构)普遍存在的歧义,我应该尝试对语言工作台的基本特征进行初步的定义,我现在可以简要地做到这一点,因为我已经提供了必要的背景。
- 用户可以自由定义彼此完全集成的新语言。
- 主要信息来源是持久的抽象表示形式。
- 语言设计者通过三个主要部分定义 DSL:模式、编辑器和生成器。
- 语言用户通过投影编辑器来操作 DSL。
- 语言工作台可以在其抽象表示形式中保留不完整或矛盾的信息。
语言工作台如何改变面向语言编程的权衡。
不久前,我讨论了面向语言编程的权衡。语言工作台显然会影响这种权衡,并带来许多需要考虑的新事物。
语言工作台对等式做出的最明显改变是创建外部 DSL 的容易程度。您不再需要编写解析器。您确实需要定义抽象语法,但这实际上是一个非常简单的数据库建模步骤。此外,您的 DSL 还获得了一个强大的 IDE,尽管您确实需要花一些时间来定义该编辑器。生成器仍然是您必须做的事情,我的感觉是它并不比以往更容易。但是,为一个优秀而简单的 DSL 构建生成器是这项工作中最简单的部分之一。
语言工作台的第二个优点是您可以获得符号集成。能够使用类似 Excel 的公式语言,并将其插入到您自己的专用语言中,这是非常棒的。同样,能够在一个语言中更改符号,并让这些更改在整个系统中传播,这也是使用语言工作台时可以考虑的一个合理的事情(我不确定它们中是否已经有哪个可以做到这一点)。
重构这个问题是语言工作台中的一大问题。当我解释如何使用语言工作台时,很容易落入将其描述为“首先定义 DSL,然后使用它构建东西”的陷阱。如果您阅读过我过去写过的很多东西,那么这个概念应该会敲响许多警钟。我非常提倡演进式设计——在这个语境下,这意味着您需要能够同时演进 DSL 和用 DSL 构建的任何代码。这是一个难题,但在 Intentional 的早期开发中就已得到承认。现在就断言在成熟的语言工作台中,与 DSL 的使用同时演进 DSL 会有多成功还为时过早——但缺乏这种能力将是它们的一大缺陷。
我认为语言工作台中期面临的最大问题是供应商锁定的风险。目前还没有定义模式、编辑器和生成器三者的标准。一旦您在语言工作台中定义了一种语言,您就被绑定到该语言工作台。不同的语言工作台之间没有交换的标准——如果您想更换语言工作台,这将导致您不得不重新实现这三者。随着时间的推移,我们可能会看到某种专门用于交换 DSL 的特殊存储表示——一种交换表示。但是,除非在这方面出现一个可靠的解决方案,否则供应商锁定仍然是一个很大的风险。(MDA 声称可以解决这个问题,但它充其量只是部分解决方案。)
对此的一种缓解措施是,将语言工作台视为帮助您生成源代码的工具。例如,可以使用语言工作台来控制所有 Java XML 配置文件。如果最坏的情况发生,您不得不放弃语言工作台,那么您仍然拥有生成的配置文件。只要您注意生成的代码是否清晰易懂,您甚至可能不会比自己编写更糟糕。即使对于更深层次的功能,您仍然可以生成结构良好的 Java 代码。这在一定程度上降低了风险,至少您不会完全陷入困境。但是,供应商锁定仍然是需要考虑的问题。
关于工具的这个问题是放弃文本文件作为源代码的后果之一。其他问题也随之而来——我们已经设法用文本解决了这些问题,但现在必须重新思考抽象表示的中心作用。在我的清单上,最重要的是版本控制。我们知道如何对文本源代码进行有效的版本控制,并具有良好的差异和合并功能。为了提高效率,语言工作台需要能够提供抽象表示本身的差异和合并功能。从理论上讲,这应该是可以解决的,并且可以实现真正的语义差异(其中重命名符号被理解为该行为,而不仅仅是像使用文本那样从其结果中推断出的东西)。Intentional 似乎在这方面有一个很好的解决方案,但我们还没有在实践中尝试过。
回到积极的一面,自定义语言和编辑器的结合可能最终为非程序员编辑 DSL 铺平了道路。此外,符号集成消除了用户代码和核心程序不同步的问题。编辑器的使用可能是帮助打破 COBOL 推论的最大工具——提供为用户交互定制工具的环境。
这种让领域专家更直接地参与开发工作的承诺,也许是语言工作台承诺中最诱人的部分。我们一次又一次地看到,无论我们程序员使用什么工具来提高生产力,都有一种感觉,我们正在优化空闲循环。在我访问的大多数项目中,最大的问题是开发人员和业务人员之间的沟通。如果这方面进展顺利,那么即使使用二流的技术,您也可以取得进展。如果这种关系破裂,那么即使是 Smalltalk 也救不了你。
大多数面向语言编程的支持者都在谈论更多地让领域专家参与进来。事实上,我甚至听说过秘书们愉快地用 Lisp 的内部 DSL 编程的例子。然而,大多数情况下,这些努力都没有真正取得成功。通过将专注的外部 DSL 与复杂的编辑器和开发环境相结合,也许我们最终可以开始解决这个问题。如果真是这样,那么好处将是巨大的。事实上,令人惊讶的是,这种用户参与似乎是 Charles Simonyi 工作背后的主要驱动力,支撑着 Intentional Software 中的大多数决策。
这些工具短期内最大的限制是成熟度。这些工具要达到甚至领先的开发人员水平还需要一段时间。但正如我们所知,这种情况可能会迅速改变——想想十年前与现在的工具和语言选择相比就知道了。
改变我们对 DSL 的理解
我在本文中使用的例子实际上是 DSL 中相当无趣的例子。我使用它们是因为它们易于讨论和构建。但即使是更复杂的协议 DSL 也相当传统——很容易看出它如何可以作为传统的文本 DSL 来完成。许多人希望生成图形化的 DSL,但即使是这些 DSL 也不能完全发挥其潜力。使用“语言”一词的最大危险在于,它可能会导致人们忽略语言工作台真正能做的事情。
当我与我的同事们谈论 OOPSLA 2004 时,最热门的话题是 Jonathon Edwards 关于以示例为中心的编程的一些演示。其关键思想是一个编辑器,它不仅显示程序代码,还显示该代码中示例执行的结果。这个想法是,虽然我们操纵的是抽象,但我们经常发现用具体案例来思考更容易。这种对示例的倾向是以测试驱动开发的吸引力很大一部分——我认为它是以示例说明。
Edwards 将他的想法进一步发展成一个名为Subtext的工具。Subtext 与语言工作台有一些共同的原则——特别是放弃文本源代码的想法。虽然 subtext 在支持轻松定义新语言方面不那么有趣,但它提供了一个有趣的视角,让我们了解随着语言工作台让我们深入思考语言和工具的紧密联系,可能会发展出什么样的想法。
事实上,这可能是语言工作台能够避免 COBOL 推论的不利影响的最强有力的理由。正如我之前所说,我们不断地提出技术来赋予用户作为非专业程序员的能力,但却经常失败。让我们考虑一项真正成功地使非专业程序员变得高效的技术——电子表格。
大多数程序员并不认为电子表格是一种编程环境。然而,许多非专业程序员使用它们创建了复杂的系统。电子表格是一个迷人的编程环境,它暗示了非专业编程工具可能需要的特性
- 即时反馈——包括立即显示示例计算的结果。
- 工具和语言的深度集成
- 没有文本源代码
- 不需要始终显示所有信息——公式仅在您编辑包含它们的单元格时可见,否则将显示值。
电子表格也非常令人沮丧。它们缺乏结构鼓励实验,但我经常觉得稍微多一点结构可以让某些问题更容易处理。
因此,当我们考虑语言工作台中的 DSL 时,我们不应该再局限于我在这里展示的那些语言——或者建模者所钟爱的图形语言。相反,我们应该考虑下一代电子表格之类的东西。
结论
我写这篇文章的主要目的是向您介绍语言工作台。至少我希望您现在已经了解了足够多的知识,以便在您的经理要求您用它们替换整个编程环境时,能够应对自如。
在我看来,语言工作台提供了两个主要优势。一是通过为程序员提供更好的工具来提高他们的生产力。另一个是通过让领域专家有更多机会直接贡献于开发基础,从而加强与领域专家的关系,从而提高开发效率。只有时间才能证明这些优势是否能够真正实现。看看这两点,我会说提高生产力更有可能实现,但影响较小。如果语言工作台对开发和领域专家之间的关系产生了重大影响,那么它可能会产生巨大的影响——但它必须克服 COBOL 推论才能取得成功。
也许我意识到最有趣的事情是,一旦我们有了使用语言工作台的经验,我们可能就不知道 DSL 会是什么样子了。到目前为止,我的想法仍然很大程度上局限于对文本和图形语言的思考。然而,编辑器和模式的相互作用开辟了与大多数人对外部 DSL 的想法截然不同的可能性。如果语言工作台不负众望,那么十年后,我们会回顾过去,嘲笑我们现在对 DSL 应该是什么样子的想法。
正如我所指出的,语言工作台仍处于非常早期的开发阶段。要认真评估它们还需要几年的时间。我不打算预测它们是否会像它们的倡导者所希望的那样改变软件开发的面貌。我不是一个技术未来学家。但我相信,语言工作台是我们视野边缘最有趣的想法之一。如果它们真的发挥了潜力,它们肯定会对我们的行业产生巨大的影响。即使没有,我怀疑它们也会带来很多有趣的想法。
所以我建议你密切关注这个领域。这是一个有趣的领域,而且有足够的生命力在未来许多年里保持有趣。我很幸运,在最近几个月里对它有了一个很好的了解,我打算在未来一段时间内继续保持对它的兴趣。
延伸阅读
我决定将延伸阅读的参考资料放在我的 bliki 上。这样更容易跟踪更新。
致谢
我衷心感谢我的 ThoughtWorker 同事 Matt Foemmel。Matt 长期以来一直是 Thoughtworks 的中坚力量工具匠,并且一直在寻找推动我们开发工作前进的方法。他从 2004 年初开始对意图编程产生兴趣,我从他的研究中受益匪浅。去年,他积极参与了 Intentional Software 的开发工作,这对我理解这个环境非常有帮助。
当我听说我所钦佩的为数不多的软件工具公司中有一家正在这个领域工作时,我立刻就产生了兴趣。Sergey Dmitriev 在波士顿,离我只有几英里远,这让我更加兴奋。Sergey 在开发 MPS 的过程中,让我有机会接触到 MPS。他和他的团队以这个协议示例为例,并在 MPS 中实现了它,这样我就可以描述一些并非完全是空中楼阁的东西。Igor Alshannikov 在我遇到尚处于开发中的软件不可避免的问题时帮助了我。
Intentional Software 在过去几年里一直非常低调,因为他们一直在发展自己的想法。Charles Simonyi 让我有机会接触到他们的工具和计划。我还得以与 Magnus Christerson 恢复合作,他现在也在 Intentional 工作。
和许多在 80 年代和 90 年代身处英国的人一样,我从 Steve Cook 领导的面向对象社区中受益匪浅。从那时起,他帮助我理解了 UML 规范的复杂之处,并且在这篇文章中,他就微软的软件工厂计划提供了非常有用的信息。很高兴看到我的许多老朋友参与了这个项目:Keith Short、Jack Greenfield、Alan Wills 和 Stuart Kent 都是重要的信息来源。
多亏了 Daniel Jackson 教授,我才得以多次访问麻省理工学院,并度过了愉快的时光。特别是,他把我介绍给了 Jonathon Edwards。我并不是第一次在最初接触到戏剧性的想法时无法理解,但我最终还是会明白的。
在 Thoughtworks 工作的最大好处之一就是能够随时接触到正在做有趣事情的优秀人才。在这种情况下,能够接触到与 Intentional 工具密切合作的人员非常有用:Matt Foemmel、Jeremy Stell-Smith 和 Jason Wadsworth。
说到 Thoughtworks 的同事,Rebecca Parsons 和 Dave Rice 一直是我很好的思想交流对象,这对保持我的思路清晰至关重要。
除了提供这类背景信息来撰写这些文章之外,我还收到了 Rebecca Parsons、Dave 'Bedarra' Thomas、Steve Cook、Jack Greenfield、Bill Caputo、Obie Fernandez、Magnus Christerson 和 Igor Alshannikov 对早期草稿的有益评论。
感谢 Reuven Yagel、Dave Hoover 和 Ravi Mohan 发现并向我发送了拼写错误。
重大修订
2005 年 6 月 12 日:首次出版。