
功能切换(又称功能标志)
功能切换(通常也称为功能标志)是一种强大的技术,允许团队在不更改代码的情况下修改系统行为。它们属于不同的使用类别,在实现和管理切换时,务必考虑到这种分类。切换会带来复杂性。我们可以通过使用智能切换实现实践和适当的工具来管理切换配置,从而控制这种复杂性,但我们也应该致力于限制系统中切换的数量。
2017 年 10 月 9 日

“功能切换”是一组模式,可以帮助团队快速安全地向用户交付新功能。在这篇关于功能切换的文章中,我们将首先讲述一个简短的故事,展示功能切换在哪些典型场景中非常有用。然后,我们将深入探讨细节,涵盖有助于团队成功使用功能切换的特定模式和实践。
功能切换也称为功能标志、功能位或功能翻转器。这些都是同一组技术的同义词。在本文中,我将交替使用功能切换和功能标志。
一个切换的故事
想象一下这个场景。你所在的团队正在开发一款复杂的城市规划模拟游戏。你的团队负责核心模拟引擎。你的任务是提高样条插值算法的效率。你知道这需要对实现进行相当大的修改,这将需要几周的时间。同时,你团队的其他成员需要继续进行代码库相关领域的一些正在进行的工作。
你希望尽可能避免为此工作创建分支,因为你之前有过合并长期分支的痛苦经历。相反,你决定整个团队将继续在主干上工作,但从事样条插值改进的开发人员将使用功能切换来防止他们的工作影响团队的其他成员或破坏代码库的稳定性。
功能标志的诞生
以下是从事该算法的开发人员引入的第一个更改
之前
function reticulateSplines(){
// current implementation lives here
}
这些示例都使用 JavaScript ES2015
之后
function reticulateSplines(){
var useNewAlgorithm = false;
// useNewAlgorithm = true; // UNCOMMENT IF YOU ARE WORKING ON THE NEW SR ALGORITHM
if( useNewAlgorithm ){
return enhancedSplineReticulation();
}else{
return oldFashionedSplineReticulation();
}
}
function oldFashionedSplineReticulation(){
// current implementation lives here
}
function enhancedSplineReticulation(){
// TODO: implement better SR algorithm
}
开发人员已将当前算法实现移至 oldFashionedSplineReticulation 函数中,并将 reticulateSplines 变为一个**切换点**。现在,如果有人正在开发新算法,他们可以通过取消注释 useNewAlgorithm = true 行来启用“使用新算法”**功能**。
使标志动态化
几个小时过去了,开发人员准备通过一些模拟引擎的集成测试来运行他们的新算法。他们还想在相同的集成测试运行中测试旧算法。他们需要能够动态地启用或禁用该功能,这意味着是时候放弃通过注释或取消注释 useNewAlgorithm = true 行来实现的笨拙机制了
function reticulateSplines(){
if( featureIsEnabled("use-new-SR-algorithm") ){
return enhancedSplineReticulation();
}else{
return oldFashionedSplineReticulation();
}
}
我们现在引入了一个 featureIsEnabled 函数,这是一个**切换路由器**,可用于动态控制哪个代码路径处于活动状态。实现切换路由器的方法有很多,从简单的内存存储到具有精美 UI 的高度复杂的分布式系统,不一而足。现在,我们将从一个非常简单的系统开始
function createToggleRouter(featureConfig){
return {
setFeature(featureName,isEnabled){
featureConfig[featureName] = isEnabled;
},
featureIsEnabled(featureName){
return featureConfig[featureName];
}
};
}
请注意,我们正在使用 ES2015 的方法简写
我们可以根据一些默认配置(可能从配置文件中读取)创建一个新的切换路由器,但我们也可以动态地打开或关闭某个功能。这允许自动化测试验证切换功能的两个方面
describe( 'spline reticulation', function(){
let toggleRouter;
let simulationEngine;
beforeEach(function(){
toggleRouter = createToggleRouter();
simulationEngine = createSimulationEngine({toggleRouter:toggleRouter});
});
it('works correctly with old algorithm', function(){
// Given
toggleRouter.setFeature("use-new-SR-algorithm",false);
// When
const result = simulationEngine.doSomethingWhichInvolvesSplineReticulation();
// Then
verifySplineReticulation(result);
});
it('works correctly with new algorithm', function(){
// Given
toggleRouter.setFeature("use-new-SR-algorithm",true);
// When
const result = simulationEngine.doSomethingWhichInvolvesSplineReticulation();
// Then
verifySplineReticulation(result);
});
});
准备发布
更多的时间过去了,团队认为他们的新算法功能已经完成。为了证实这一点,他们一直在修改更高级别的自动化测试,以便在功能关闭和打开的情况下测试系统。团队还想进行一些手动探索性测试,以确保一切按预期工作 - 毕竟,样条插值是系统行为的关键部分。
为了对尚未验证为可供一般用户使用的功能执行手动测试,我们需要能够为我们的一般用户群在生产环境中关闭该功能,但能够为内部用户打开该功能。有很多不同的方法可以实现这一目标
- 让切换路由器根据**切换配置**做出决策,并使该配置特定于环境。仅在预生产环境中打开新功能。
- 允许通过某种形式的管理 UI 在运行时修改切换配置。使用该管理 UI 在测试环境中打开新功能。
- 教会切换路由器如何做出动态的、每个请求的切换决策。这些决策会考虑**切换上下文**,例如,通过查找特殊的 Cookie 或 HTTP 标头。通常,切换上下文用作识别发出请求的用户的代理。
(我们将在后面更详细地介绍这些方法,因此,如果您不熟悉其中的一些概念,请不要担心。)
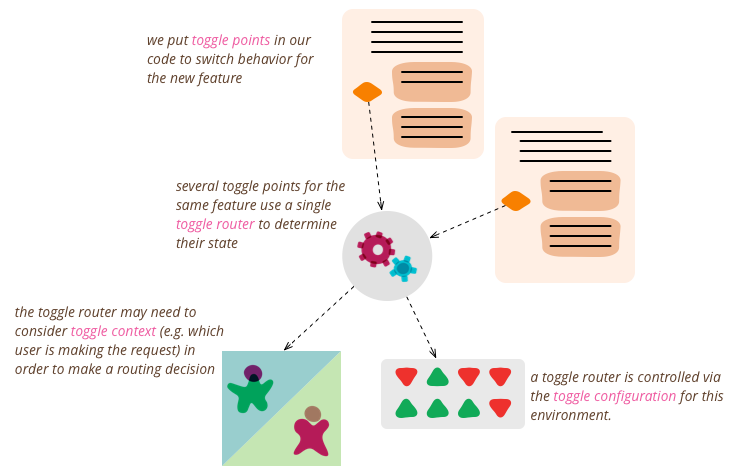
团队决定使用每个请求的切换路由器,因为它为他们提供了很大的灵活性。团队特别赞赏的是,这将允许他们在不需要单独的测试环境的情况下测试他们的新算法。相反,他们可以简单地在生产环境中打开算法,但仅限内部用户使用(通过特殊的 Cookie 检测)。团队现在可以为自己打开该 Cookie,并验证新功能是否按预期执行。
金丝雀发布
根据迄今为止进行的探索性测试,新的样条插值算法看起来不错。然而,由于它是游戏模拟引擎中如此关键的一部分,因此仍然有些不愿为所有用户打开此功能。团队决定使用他们的功能标志基础设施来执行**金丝雀发布**,只为一小部分用户(“金丝雀”队列)打开新功能。
团队通过教会切换路由器用户队列的概念来增强它 - 用户队列是指始终体验到某个功能处于打开或关闭状态的用户组。金丝雀用户队列是通过对 1% 的用户群进行随机抽样创建的 - 可能使用用户 ID 的模数。此金丝雀队列将始终打开该功能,而其他 99% 的用户群仍然使用旧算法。监控两组用户的关键业务指标(用户参与度、总收入等),以确保新算法不会对用户行为产生负面影响。一旦团队确信新功能没有不良影响,他们就会修改切换配置,为所有用户打开该功能。
A/B 测试
团队的产品经理了解了这种方法,并且非常兴奋。她建议团队使用类似的机制来执行一些 A/B 测试。关于修改犯罪率算法以将污染水平考虑在内是会增加还是降低游戏的可玩性,一直存在着长期的争论。他们现在有能力使用数据来解决这场争论。他们计划推出一款能够捕捉这一想法精髓的廉价实现方案,并使用功能标志进行控制。他们将为相当大一部分用户队列打开该功能,然后研究这些用户的行为与“对照”队列相比如何。这种方法将允许团队根据数据而不是最高付费者(HiPPO)的意见来解决有争议的产品争论。
这个简短的场景旨在说明功能切换的基本概念,同时也强调了这个核心功能可以有多少不同的应用。现在我们已经看到了一些应用示例,让我们更深入地研究一下。我们将探讨不同类别的切换,并了解它们之间的区别。我们将介绍如何编写可维护的切换代码,最后分享避免功能切换系统的一些陷阱的实践。
切换的类别
我们已经看到了功能切换提供的基本功能 - 能够在一个可部署单元中交付备用代码路径,并在运行时在它们之间进行选择。上面的场景还表明,此功能可以在各种上下文中以各种方式使用。将所有功能切换都归为一类可能很诱人,但这很危险。针对不同类别切换的设计力量截然不同,以相同的方式管理它们会导致日后出现问题。
功能切换可以根据两个主要维度进行分类:功能切换的持续时间以及切换决策的动态程度。还有其他因素需要考虑 - 例如,谁将管理功能切换 - 但我认为持续时间和动态性是两个可以帮助指导如何管理切换的重要因素。
让我们从这两个维度来考虑各种类别的切换,看看它们适合在哪里。
发布切换
发布切换允许将不完整且未经测试的代码路径作为潜在代码交付到生产环境中,这些代码可能永远不会被打开。
这些是用于为实践持续交付的团队启用基于主干的开发的功能标志。它们允许将正在进行的功能签入到共享集成分支(例如 master 或 trunk)中,同时仍然允许随时将该分支部署到生产环境中。发布切换允许将不完整且未经测试的代码路径作为潜在代码交付到生产环境中,这些代码可能永远不会被打开。
产品经理也可以使用以产品为中心的相同方法的版本,来防止将完成一半的产品功能暴露给最终用户。例如,电子商务网站的产品经理可能不希望用户看到一个新的“预计发货日期”功能,该功能仅适用于网站的一个发货合作伙伴,而更愿意等到该功能对所有发货合作伙伴都实现后再发布。产品经理可能有其他原因不想公开这些功能,即使这些功能已经完全实现并经过测试。例如,功能发布可能正在与营销活动协调。以这种方式使用发布开关是实现“将 [功能] 发布与 [代码] 部署分离”的持续交付原则的最常见方式。
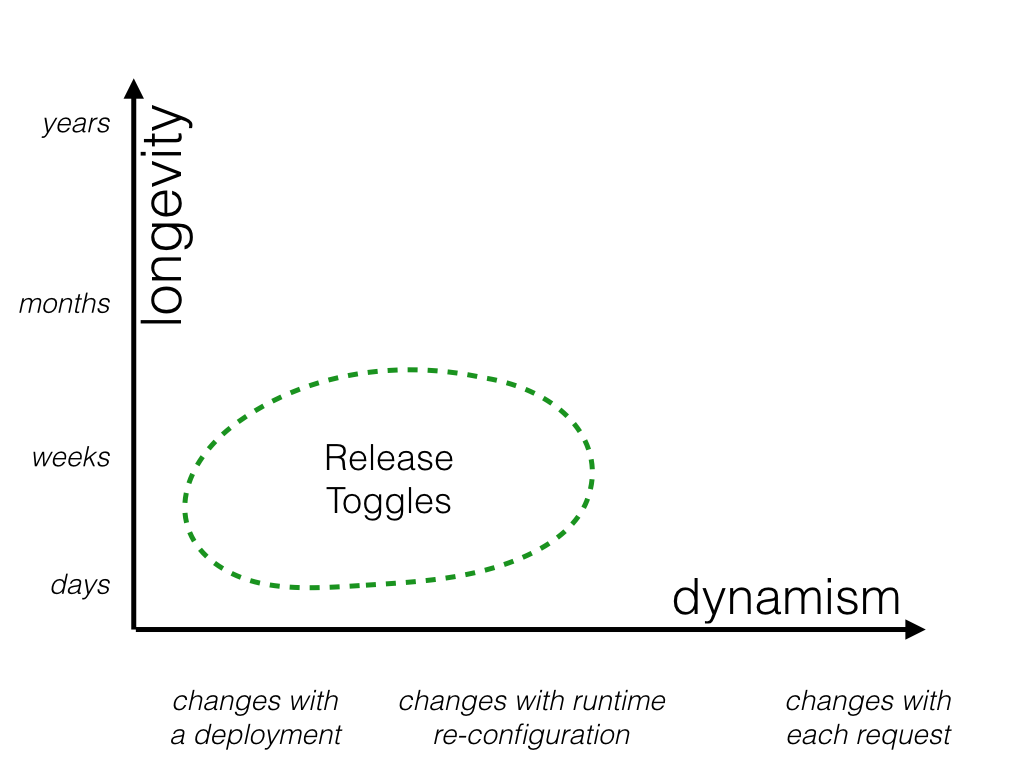
发布开关本质上是过渡性的。它们通常不应该保留超过一两周,尽管以产品为中心的开关可能需要保留更长时间。发布开关的切换决定通常非常静态。给定发布版本的每个切换决定都将相同,并且通过推出具有切换配置更改的新版本来更改该切换决定通常是完全可以接受的。
实验切换
实验开关用于执行多变量或 A/B 测试。系统的每个用户都被放入一个队列中,并且在运行时,开关路由器将根据用户所在的队列,始终将给定用户发送到一个代码路径或另一个代码路径。通过跟踪不同队列的聚合行为,我们可以比较不同代码路径的效果。这种技术通常用于对电子商务系统的购买流程或按钮上的“行动号召”措辞等内容进行数据驱动的优化。
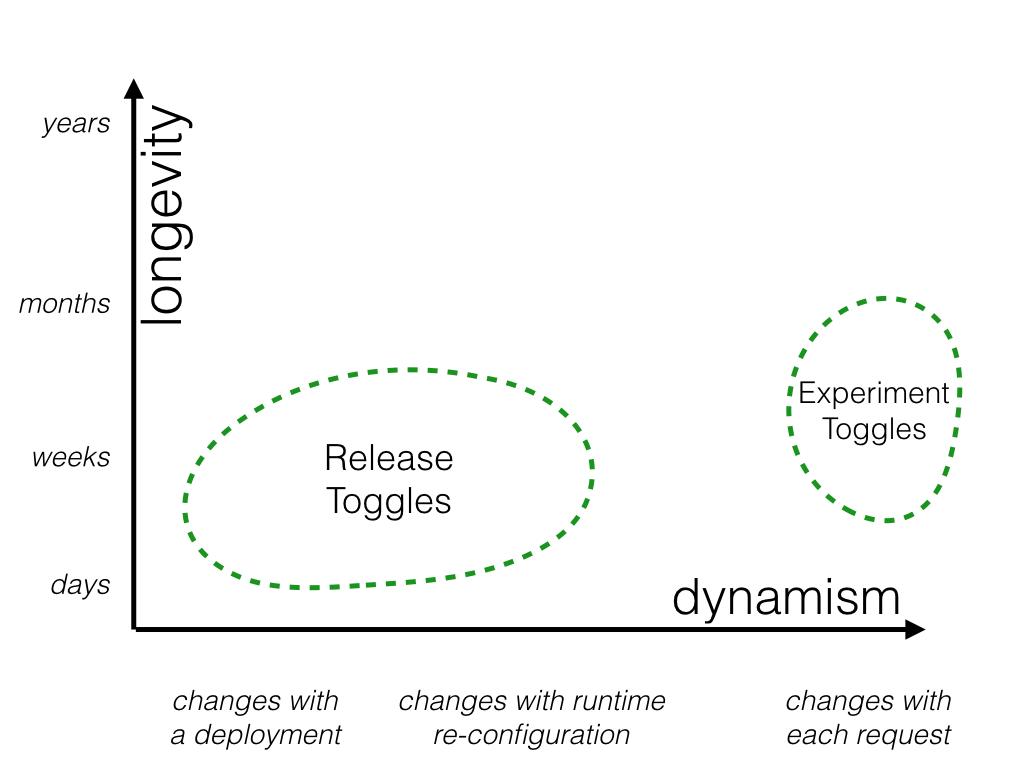
实验开关需要保持相同的配置足够长的时间,以产生具有统计学意义的结果。根据流量模式,这可能意味着持续数小时或数周。更长时间不太可能有用,因为对系统的其他更改可能会使实验结果无效。根据其性质,实验开关是高度动态的 - 每个传入的请求都可能代表不同的用户,因此路由方式可能与上一个请求不同。
运维切换
这些标志用于控制我们系统行为的操作方面。我们可能会在推出一个性能影响不明确的新功能时引入一个操作开关,以便系统操作员可以在需要时在生产环境中快速禁用或降级该功能。
大多数操作开关的寿命相对较短 - 一旦对新功能的操作方面获得了信心,就应该取消该标志。但是,系统拥有一些长期存在的“终止开关”并不少见,这些开关允许生产环境的操作员在系统承受异常高的负载时优雅地降级非关键系统功能。例如,当我们处于高负载状态时,我们可能希望禁用主页上相对昂贵的“推荐”面板。我咨询了一家在线零售商,该零售商维护着操作开关,这些开关可以在高需求产品发布之前故意禁用其网站主要购买流程中的许多非关键功能。这些类型的长期存在的操作开关可以被视为手动管理的断路器。
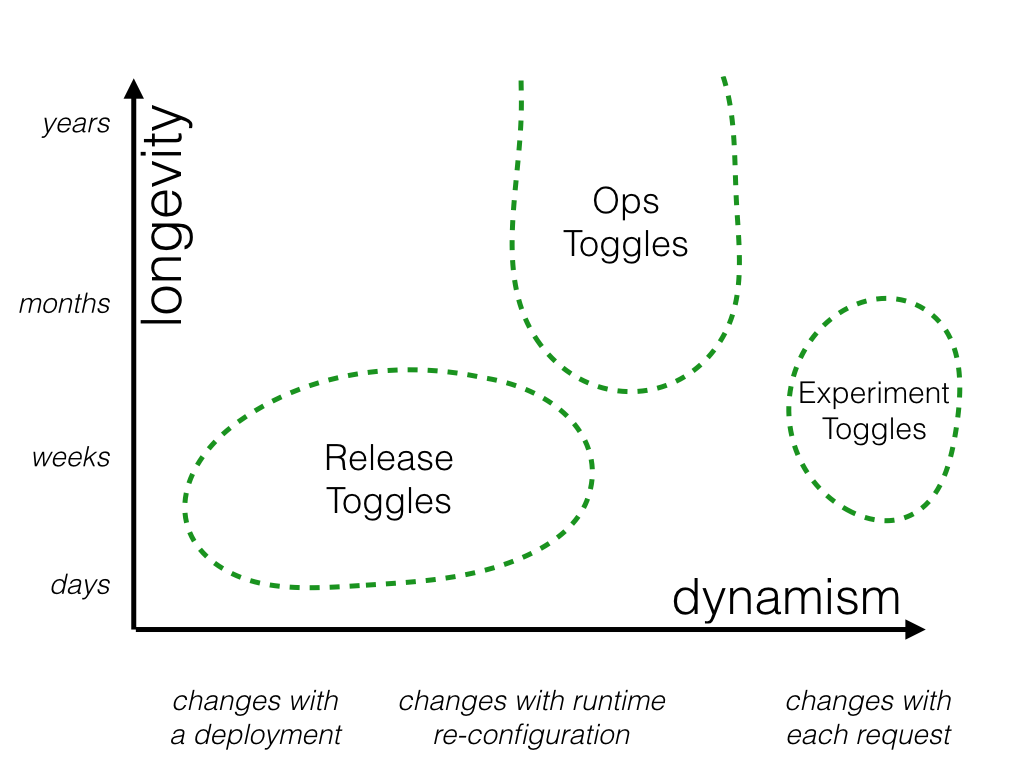
如前所述,其中许多标志只是暂时存在,但一些关键控件可能会留给操作员几乎无限期地使用。由于这些标志的目的是允许操作员快速响应生产问题,因此需要对其进行极其快速的重新配置 - 需要推出新版本才能翻转操作开关不太可能让操作人员满意。
权限切换
为一组内部用户启用新功能 [是] 香槟早午餐 - 一个尽早“喝自己的香槟”的机会
这些标志用于更改某些用户接收到的功能或产品体验。例如,我们可能有一组“高级”功能,我们只为付费客户启用这些功能。或者,我们可能有一组“alpha”功能,这些功能仅供内部用户使用,而另一组“beta”功能仅供内部用户和 beta 用户使用。我将这种为一组内部或 beta 用户启用新功能的技术称为“香槟早午餐” - 一个尽早“喝自己的香槟”的机会。
香槟早午餐在许多方面类似于金丝雀发布。两者之间的区别在于,金丝雀发布的功能会向随机选择的用户群公开,而香槟早午餐功能会向特定用户群公开。
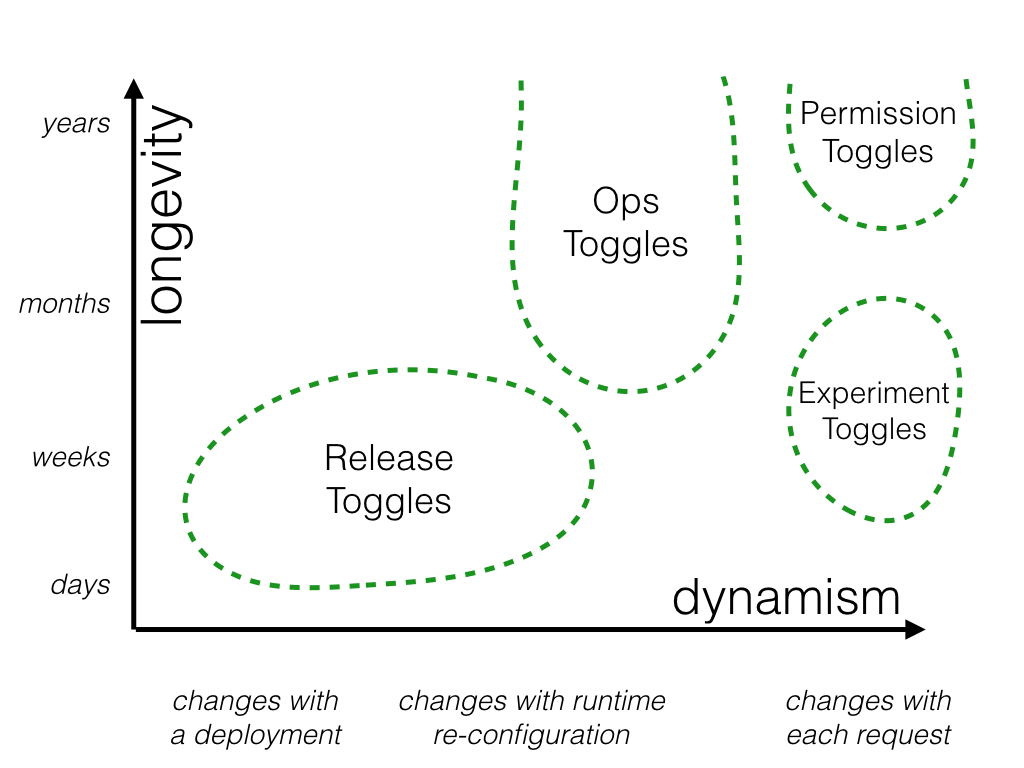
当用作管理仅向高级用户公开的功能的一种方式时,与其他类别的功能开关相比,权限开关的寿命可能非常长 - 长达数年。由于权限是用户特定的,因此权限开关的切换决定将始终是按请求进行的,这使其成为一个非常动态的开关。
管理不同类别的切换
现在我们有了一个开关分类方案,我们可以讨论动态性和寿命这两个维度如何影响我们处理不同类别的功能标志的方式。
静态切换与动态切换
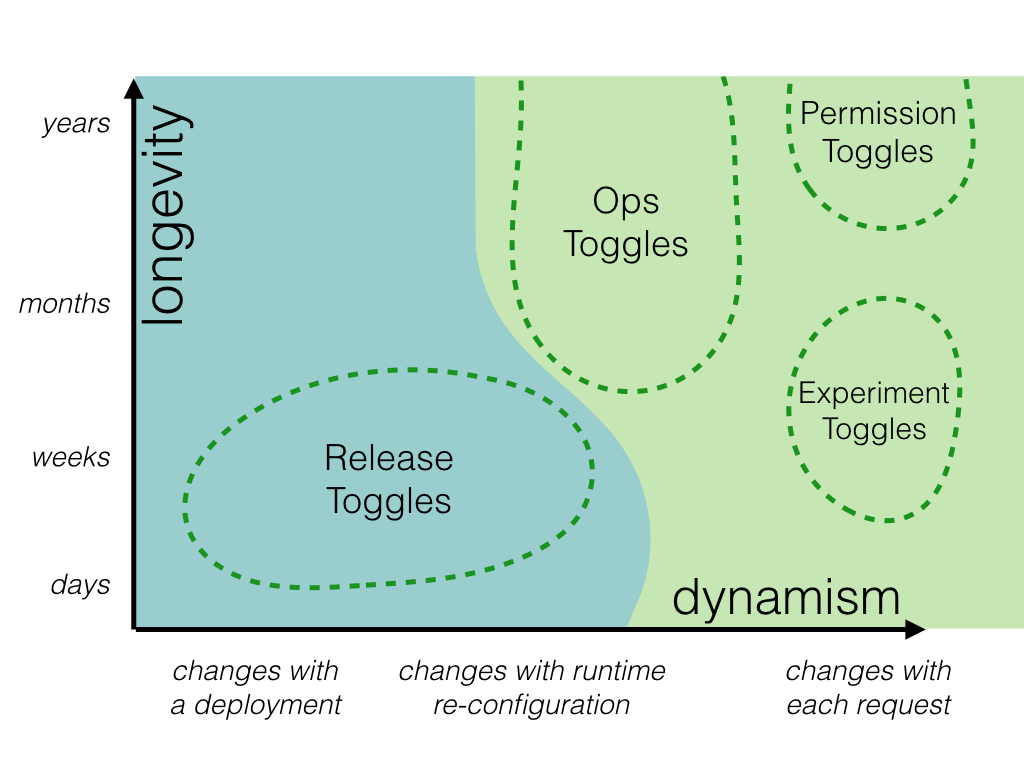
进行运行时路由决策的开关必然需要更复杂的开关路由器,以及这些路由器的更复杂配置。
对于简单的静态路由决策,开关配置可以是每个功能的简单开或关,并带有一个开关路由器,该路由器仅负责将该静态开/关状态传递到开关点。正如我们之前讨论的,其他类别的开关更具动态性,需要更复杂的开关路由器。例如,实验开关的路由器会为给定用户动态地做出路由决策,也许是使用某种基于该用户 ID 的一致队列算法。该开关路由器不是从配置中读取静态开关状态,而是需要读取某种队列配置,该配置定义了实验队列和控制队列的大小等内容。该配置将用作队列算法的输入。
稍后我们将详细介绍管理此开关配置的不同方法。
长期切换与临时切换
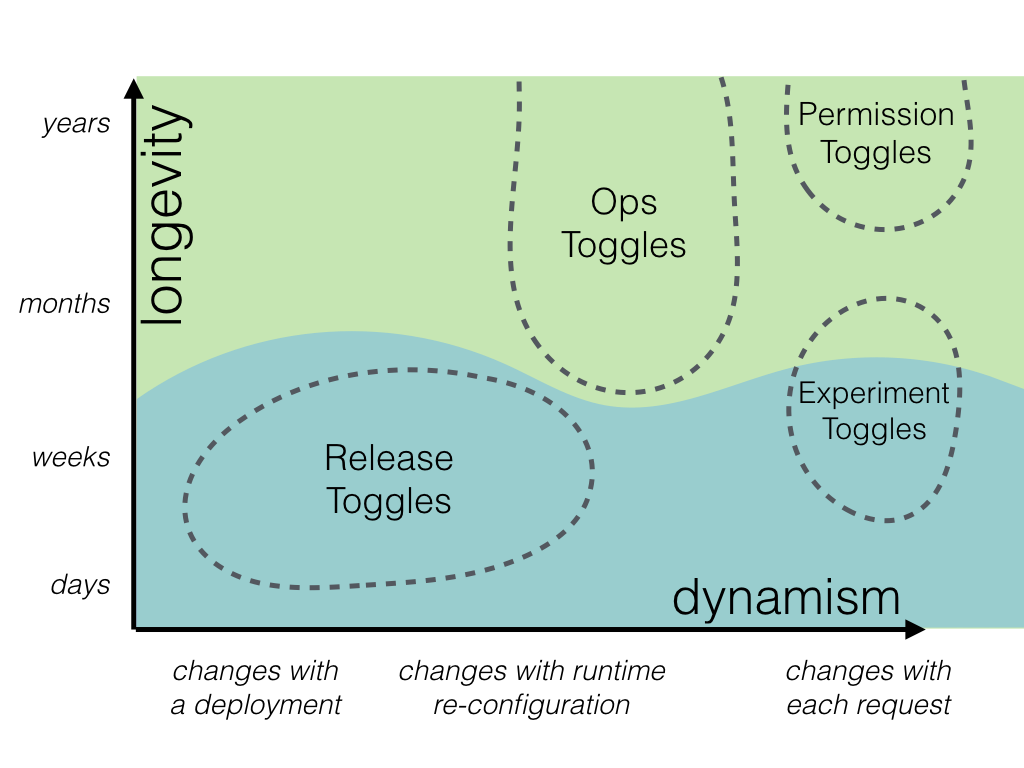
我们还可以将开关类别划分为本质上是瞬态的类别和长期存在的类别,这些类别可能会存在数年。这种区别应该对我们实现功能开关点的方法产生重大影响。如果我们添加一个将在几天后删除的发布开关,那么我们可能可以使用一个对开关路由器进行简单 if/else 检查的开关点。这就是我们之前对样条重网格化示例所做的
function reticulateSplines(){
if( featureIsEnabled("use-new-SR-algorithm") ){
return enhancedSplineReticulation();
}else{
return oldFashionedSplineReticulation();
}
}
但是,如果我们正在创建一个新的权限开关,并且我们希望其开关点能够长期存在,那么我们当然不希望通过不加选择地散布 if/else 检查来实现这些开关点。我们需要使用更易于维护的实现技术。
实现技术
功能标志似乎会导致相当混乱的开关点代码,而且这些开关点也倾向于在代码库中扩散。重要的是要控制代码库中任何功能标志的这种趋势,如果标志是长期存在的,则这一点至关重要。有一些实现模式和实践可以帮助减少这个问题。
将决策点与决策逻辑分离
功能开关的一个常见错误是将做出切换决策的位置(开关点)与决策背后的逻辑(开关路由器)耦合在一起。让我们来看一个例子。我们正在开发下一代电子商务系统。我们的一个新功能将允许用户通过单击其订单确认电子邮件(又称发票电子邮件)中的链接轻松取消订单。我们正在使用功能标志来管理所有下一代功能的推出。我们最初的功能标记实现如下所示
invoiceEmailer.js
const features = fetchFeatureTogglesFromSomewhere();
function generateInvoiceEmail(){
const baseEmail = buildEmailForInvoice(this.invoice);
if( features.isEnabled("next-gen-ecomm") ){
return addOrderCancellationContentToEmail(baseEmail);
}else{
return baseEmail;
}
}
在生成发票电子邮件时,我们的 InvoiceEmailler 会检查是否启用了“next-gen-ecomm”功能。如果是,则电子邮件程序会在电子邮件中添加一些额外的订单取消内容。
虽然这看起来像是一种合理的方法,但它非常脆弱。关于是否在我们的发票电子邮件中包含订单取消功能的决定直接与相当广泛的“next-gen-ecomm”功能相关联 - 使用的是一个神奇的字符串,仅此而已。为什么发票电子邮件代码需要知道订单取消内容是下一代功能集的一部分?如果我们想在不公开订单取消的情况下启用下一代功能的某些部分,会发生什么?反之亦然?如果我们决定只想向某些用户推出订单取消功能,该怎么办?随着功能的开发,这种“切换范围”的变化非常普遍。还要记住,这些切换点往往会在代码库中扩散。使用我们当前的方法,由于切换决策逻辑是切换点的一部分,因此对该决策逻辑的任何更改都需要遍历代码库中所有已传播的切换点。
幸运的是,软件中的任何问题都可以通过添加一层间接层来解决。我们可以像这样将切换决策点与其背后的逻辑分离
featureDecisions.js
function createFeatureDecisions(features){
return {
includeOrderCancellationInEmail(){
return features.isEnabled("next-gen-ecomm");
}
// ... additional decision functions also live here ...
};
}
invoiceEmailer.js
const features = fetchFeatureTogglesFromSomewhere();
const featureDecisions = createFeatureDecisions(features);
function generateInvoiceEmail(){
const baseEmail = buildEmailForInvoice(this.invoice);
if( featureDecisions.includeOrderCancellationInEmail() ){
return addOrderCancellationContentToEmail(baseEmail);
}else{
return baseEmail;
}
}
我们引入了一个“FeatureDecisions”对象,它充当任何功能切换决策逻辑的收集点。我们在这个对象上为代码中的每个特定切换决策创建一个决策方法 - 在这种情况下,“我们是否应该在发票电子邮件中包含订单取消功能”由“includeOrderCancellationInEmail”决策方法表示。现在,决策“逻辑”是一个简单的传递,用于检查“next-gen-ecomm”功能的状态,但是现在随着该逻辑的发展,我们有了一个单独的地方来管理它。每当我们想要修改该特定切换决策的逻辑时,我们都有一个地方可以去。我们可能想要修改决策的范围 - 例如,哪个特定的功能标志控制决策。或者,我们可能需要修改决策的原因 - 从由静态切换配置驱动到由 A/B 实验驱动,或者由操作问题驱动,例如我们的一些订单取消基础设施中断。在所有情况下,我们的发票电子邮件程序都可以幸福地不知道该切换决策是如何或为什么做出的。
决策反转
在前面的示例中,我们的发票电子邮件程序负责询问功能标记基础设施它应该如何执行。这意味着我们的发票电子邮件程序需要额外了解一个概念 - 功能标记 - 以及一个它耦合到的额外模块。这使得发票电子邮件程序更难单独使用和思考,包括更难测试。随着功能标记在系统中越来越普遍,我们将看到越来越多的模块作为全局依赖项耦合到功能标记系统。这不是理想的情况。
在软件设计中,我们通常可以通过应用控制反转来解决这些耦合问题。在这种情况下也是如此。以下是我们如何将发票电子邮件程序与功能标记基础设施分离
invoiceEmailer.js
function createInvoiceEmailler(config){
return {
generateInvoiceEmail(){
const baseEmail = buildEmailForInvoice(this.invoice);
if( config.includeOrderCancellationInEmail ){
return addOrderCancellationContentToEmail(email);
}else{
return baseEmail;
}
},
// ... other invoice emailer methods ...
};
}
featureAwareFactory.js
function createFeatureAwareFactoryBasedOn(featureDecisions){
return {
invoiceEmailler(){
return createInvoiceEmailler({
includeOrderCancellationInEmail: featureDecisions.includeOrderCancellationInEmail()
});
},
// ... other factory methods ...
};
}
现在,我们的“InvoiceEmailler”不是直接访问“FeatureDecisions”,而是在构建时通过“config”对象将这些决策注入到其中。“InvoiceEmailler”现在完全不知道功能标记。它只知道其行为的某些方面可以在运行时配置。这也使得测试“InvoiceEmailler”的行为变得更容易 - 我们可以通过在测试期间传递不同的配置选项来测试它生成包含和不包含订单取消内容的电子邮件的方式
describe( 'invoice emailling', function(){
it( 'includes order cancellation content when configured to do so', function(){
// Given
const emailler = createInvoiceEmailler({includeOrderCancellationInEmail:true});
// When
const email = emailler.generateInvoiceEmail();
// Then
verifyEmailContainsOrderCancellationContent(email);
};
it( 'does not includes order cancellation content when configured to not do so', function(){
// Given
const emailler = createInvoiceEmailler({includeOrderCancellationInEmail:false});
// When
const email = emailler.generateInvoiceEmail();
// Then
verifyEmailDoesNotContainOrderCancellationContent(email);
};
});
我们还引入了一个“FeatureAwareFactory”来集中创建这些决策注入对象。这是对通用依赖注入模式的应用。如果我们的代码库中使用了 DI 系统,那么我们可能会使用该系统来实现这种方法。
避免条件语句
在我们到目前为止的示例中,我们的开关点是使用 if 语句实现的。这对于简单、短暂的开关来说可能是有意义的。但是,在需要多个开关点或您希望开关点长期存在的情况下,不建议使用点条件语句。一种更易于维护的替代方法是使用某种策略模式来实现替代代码路径
invoiceEmailler.js
function createInvoiceEmailler(additionalContentEnhancer){
return {
generateInvoiceEmail(){
const baseEmail = buildEmailForInvoice(this.invoice);
return additionalContentEnhancer(baseEmail);
},
// ... other invoice emailer methods ...
};
}
featureAwareFactory.js
function identityFn(x){ return x; }
function createFeatureAwareFactoryBasedOn(featureDecisions){
return {
invoiceEmailler(){
if( featureDecisions.includeOrderCancellationInEmail() ){
return createInvoiceEmailler(addOrderCancellationContentToEmail);
}else{
return createInvoiceEmailler(identityFn);
}
},
// ... other factory methods ...
};
}
在这里,我们通过允许使用内容增强函数配置发票电子邮件程序来应用策略模式。FeatureAwareFactory 在创建发票电子邮件程序时选择策略,并以其 FeatureDecision 为指导。如果电子邮件中应包含订单取消信息,它会传入一个增强函数,将该内容添加到电子邮件中。否则,它会传入一个 identityFn 增强器 - 它没有任何效果,只是在不做任何修改的情况下将电子邮件传回。
切换配置
动态路由与动态配置
之前我们将功能标志分为两类:一类是在给定的代码部署中其切换路由决策本质上是静态的,另一类是在运行时动态变化的。需要注意的是,标志的决策在运行时可能会以两种方式发生变化。首先,像操作切换这样的东西可能会根据系统中断从开启动态地*重新配置*为关闭。其次,某些类别的切换(如权限切换和实验切换)会根据某些请求上下文(如发出请求的用户)为每个请求做出动态路由决策。前者是通过重新配置实现动态的,而后者则本质上是动态的。这些本质上动态的切换可能会做出高度动态的*决策*,但仍然具有非常静态的*配置*,可能只能通过重新部署来更改。实验切换就是这类功能标志的一个例子 - 我们实际上不需要能够在运行时修改实验的参数。事实上,这样做可能会使实验在统计上无效。
优先选择静态配置
如果功能标志的性质允许,最好通过源代码控制和重新部署来管理切换配置。通过源代码控制管理切换配置为我们带来了与将源代码控制用于基础设施即代码等内容相同的优势。它可以允许切换配置与被切换的代码库一起存在,这提供了一个非常大的优势:切换配置将以与代码更改或基础设施更改完全相同的方式通过您的持续交付管道。这实现了 CD 的全部优势 - 可重复的构建,这些构建在跨环境的一致方式中得到验证。它还大大减少了功能标志的测试负担。不需要验证发布版在切换关闭和开启时的执行情况,因为该状态已融入发布版中,并且不会更改(至少对于不太动态的标志而言)。切换配置并排存在于源代码控制中的另一个好处是,我们可以轻松查看先前版本中切换的状态,并在需要时轻松重新创建先前版本。
管理切换配置的方法
虽然静态配置更可取,但在某些情况下(如操作切换),需要更动态的方法。让我们看看管理切换配置的一些选项,从简单但不太动态的方法到高度复杂但会带来很多额外复杂性的方法。
硬编码切换配置
最基本的技术 - 可能基本到不被认为是功能标志 - 是简单地注释或取消注释代码块。例如
function reticulateSplines(){
//return oldFashionedSplineReticulation();
return enhancedSplineReticulation();
}
比注释方法稍微复杂一点的是使用预处理器的 #ifdef 功能(如果可用)。
因为这种类型的硬编码不允许动态重新配置切换,所以它只适用于我们愿意遵循部署代码模式以重新配置标志的功能标志。
参数化切换配置
硬编码配置提供的构建时配置对于许多用例(包括许多测试场景)来说不够灵活。一种至少允许在不重新构建应用程序或服务的情况下重新配置功能标志的简单方法是通过命令行参数或环境变量指定切换配置。这是一种简单而历史悠久的切换方法,早在有人将该技术称为功能切换或功能标志之前就已经存在。但是,它也有局限性。协调大量进程的配置可能会变得很麻烦,并且对切换配置的更改需要重新部署,或者至少需要重新启动进程(并且可能还需要重新配置切换的人员对服务器具有特权访问权限)。
切换配置文件
另一种选择是从某种结构化文件中读取切换配置。对于这种切换配置方法来说,作为更通用的应用程序配置文件的一部分开始使用是很常见的。
使用切换配置文件,您现在可以通过简单地更改该文件来重新配置功能标志,而无需重新构建应用程序代码本身。但是,尽管您在大多数情况下不需要重新构建应用程序即可切换功能,但您可能仍然需要执行重新部署才能重新配置标志。
应用程序数据库中的切换配置
一旦达到一定规模,使用静态文件来管理切换配置就会变得很麻烦。通过文件修改配置相对繁琐。确保服务器群中的一致性成为一个挑战,更不用说一致地进行更改了。为了解决这个问题,许多组织将切换配置转移到某种类型的集中式存储中,通常是现有的应用程序数据库。这通常伴随着某种形式的管理 UI 的构建,该 UI 允许系统操作员、测试人员和产品经理查看和修改功能标志及其配置。
分布式切换配置
使用已经是系统架构一部分的通用数据库来存储切换配置非常普遍;这是引入功能标志并开始获得关注后显而易见的地方。但是,现在出现了一系列专用分层键值存储,它们更适合管理应用程序配置 - 例如 Zookeeper、etcd 或 Consul 等服务。这些服务形成一个分布式集群,为连接到集群的所有节点提供环境配置的共享源。可以根据需要动态修改配置,并且集群中的所有节点都会自动收到更改通知 - 这是一个非常方便的附加功能。使用这些系统管理切换配置意味着我们可以在服务器群中的每个节点上都设置切换路由器,根据在整个服务器群中协调的切换配置做出决策。
其中一些系统(如 Consul)带有一个管理 UI,它提供了一种管理切换配置的基本方法。但是,在某些时候,通常会创建一个用于管理切换配置的小型自定义应用程序。
覆盖配置
到目前为止,我们的讨论假设所有配置都由单一机制提供。许多系统的现实情况更为复杂,来自各种来源的覆盖配置层。使用切换配置,通常会使用默认配置以及特定于环境的覆盖。这些覆盖可能来自简单的东西(如额外的配置文件)或复杂的东西(如 Zookeeper 集群)。请注意,任何特定于环境的覆盖都与持续交付的理想背道而驰,即完全相同的位和配置在整个交付管道中流动。通常,实用主义决定了使用一些特定于环境的覆盖,但努力使可部署单元和配置尽可能与环境无关,将导致更简单、更安全的管道。我们将在稍后讨论测试功能切换系统时重新讨论这个主题。
每个请求的覆盖
特定于环境的配置覆盖的另一种方法是允许通过特殊的 cookie、查询参数或 HTTP 标头在每次请求的基础上覆盖切换的开启/关闭状态。与完全配置覆盖相比,这有一些优势。如果服务是负载均衡的,您仍然可以确信无论您访问哪个服务实例,覆盖都将被应用。您还可以在生产环境中覆盖功能标志,而不会影响其他用户,并且您也不太可能意外地保留覆盖。如果每次请求的覆盖机制使用持久性 cookie,则测试您系统的人员可以配置他们自己的自定义切换覆盖集,这些覆盖将在他们的浏览器中保持一致应用。
这种每次请求方法的缺点是,它引入了一种风险,即好奇或恶意的最终用户可能会自己修改功能切换状态。一些组织可能会对某些未发布的功能可能会公开给有足够决心的团体这一想法感到不安。对覆盖配置进行加密签名是缓解这种担忧的一种选择,但无论如何,这种方法都会增加功能切换系统的复杂性和攻击面。
我在这篇文章中详细阐述了这种基于 cookie 的覆盖技术,并且还描述了我和一位 Thoughtworks 同事开源的 ruby 实现。
使用功能标记系统
虽然功能切换绝对是一种有用的技术,但它确实也带来了额外的复杂性。有一些技术可以帮助您在使用功能标记系统时更轻松地工作。
公开当前功能切换配置
将构建/版本号嵌入到已部署的工件中,并在某个地方公开该元数据,以便开发人员、测试人员或操作员可以找出在给定环境中运行的特定代码,这一直是一种有用的做法。同样的想法也应该应用于功能标志。任何使用功能标志的系统都应该公开某种方式,以便操作员能够发现切换配置的当前状态。在面向 HTTP 的 SOA 系统中,这通常是通过某种元数据 API 端点或多个端点来完成的。例如,请参阅 Spring Boot 的执行器端点。
利用结构化的切换配置文件
通常将基本切换配置存储在某种结构化的、人类可读的文件中(通常采用 YAML 格式),并通过源代码控制进行管理。我们可以从这个文件中获得一些额外的好处。为每个切换包含一个人类可读的描述非常有用,特别是对于由核心交付团队以外的人员管理的切换。在尝试决定是否在生产中断事件期间启用操作切换时,您希望看到什么:basic-rec-algo 还是 “使用简单的推荐算法。这速度很快,并且对后端系统的负载更小,但准确性远低于我们的标准算法。”?一些团队还选择在其切换配置文件中包含其他元数据,例如创建日期、主要开发人员联系人,甚至用于预期寿命较短的切换的到期日期。
区别对待不同的切换
如前所述,功能切换有多种类别,具有不同的特征。应该接受这些差异,并以不同的方式管理不同的切换,即使所有不同的切换都可能使用相同的技术机制进行控制。
让我们回顾一下之前关于电子商务网站的示例,该网站在主页上有一个推荐产品部分。最初,我们可能在开发该部分时将其置于发布切换之后。然后,我们可能已将其移至实验切换之后,以验证它是否有助于增加收入。最后,我们可能会将其移至操作切换之后,以便我们能够在负载过大时将其关闭。如果我们遵循了之前关于将决策逻辑与切换点分离的建议,那么切换类别中的这些差异应该对切换点代码没有任何影响。
但是,从功能标志管理的角度来看,这些转换绝对应该产生影响。作为从发布切换到实验切换的一部分,切换的配置方式将会改变,并且可能会移动到不同的区域 - 可能移动到管理 UI 而不是源代码控制中的 yaml 文件。产品人员现在可能会管理配置,而不是开发人员。同样,从实验切换到操作切换的转换将意味着切换配置方式、配置位置以及谁管理配置的又一次改变。
功能切换增加了验证的复杂性
采用功能标记系统后,我们的持续交付流程变得更加复杂,尤其是在测试方面。当同一个制品在 CD 管道中移动时,我们通常需要测试多个代码路径。为了说明原因,假设我们正在发布一个系统,如果开启了一个开关,它可以使用一种新的优化税费计算算法,否则将继续使用我们现有的算法。在给定的可部署制品在我们的 CD 管道中移动时,我们无法知道该开关在生产环境中是否会在某个时候被打开或关闭——毕竟这就是功能标记的意义所在。因此,为了验证所有可能在生产环境中生效的代码路径,我们必须在两种状态下测试我们的制品:开关打开和关闭。
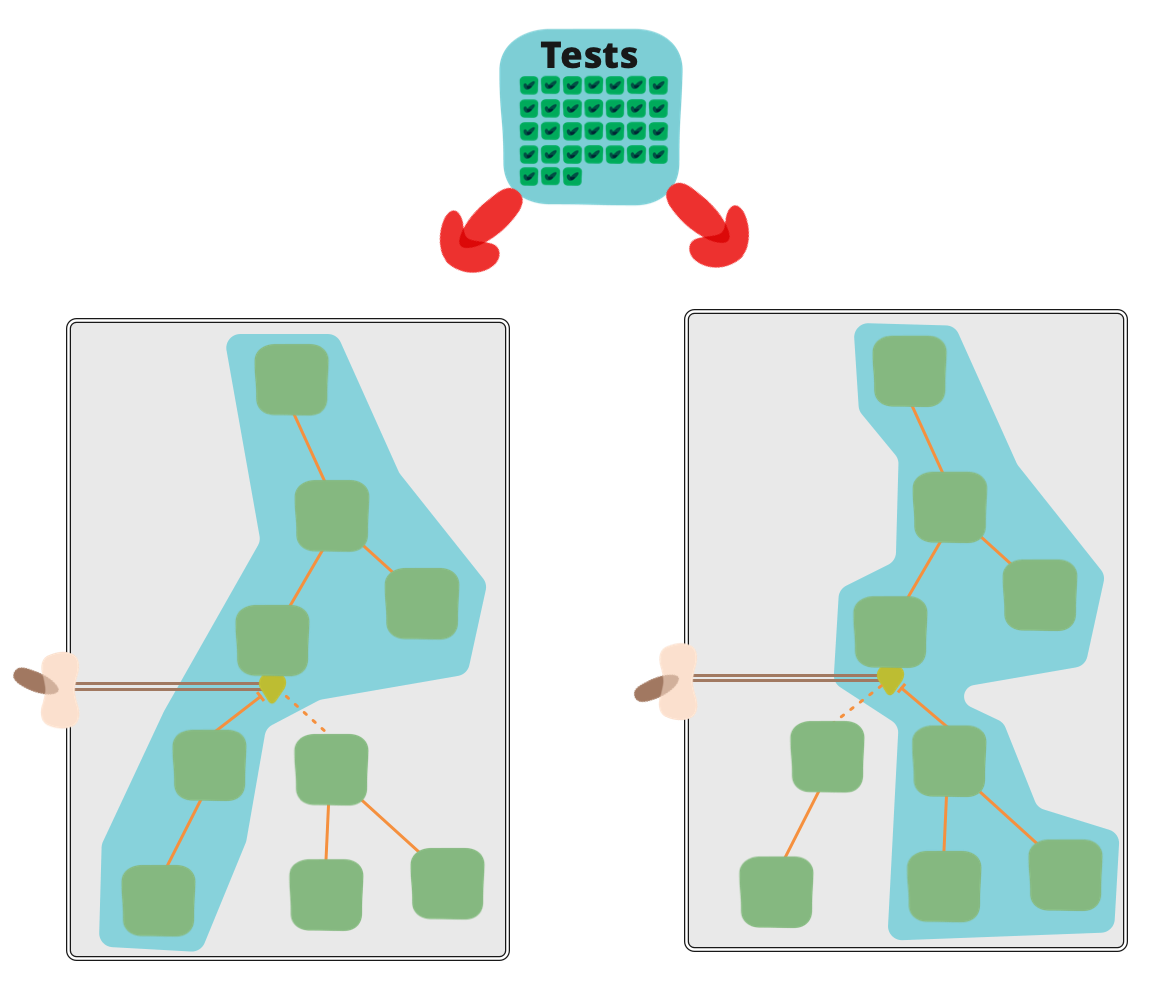
我们可以看到,仅使用一个开关,就需要我们将至少一部分测试工作量加倍。如果使用多个开关,我们就会面临可能的开关状态组合爆炸的问题。验证每种状态下的行为将是一项艰巨的任务。这可能会导致一些注重测试的人员对功能标记产生合理的怀疑。
令人高兴的是,情况并不像一些测试人员最初想象的那么糟糕。虽然功能标记的候选版本确实需要使用一些开关配置进行测试,但没有必要测试*每一种*可能的组合。大多数功能标记不会相互影响,而且大多数版本不会涉及多个功能标记配置的更改。
一个好的惯例是,当功能标记关闭时启用现有或旧的行为,当功能标记打开时启用新的或未来的行为。
那么,团队应该测试哪些功能开关配置呢?最重要的是测试您希望在生产环境中生效的开关配置,这意味着当前的生产环境开关配置加上您打算发布的任何打开的开关。同样明智的做法是测试回退配置,在该配置中,您打算发布的那些开关也被关闭。为了避免在未来的版本中出现任何意外的回归,许多团队还会在所有开关都打开的情况下执行一些测试。请注意,只有当您坚持开关语义的惯例时,这些建议才有意义,即当功能关闭时启用现有或旧的行为,当功能打开时启用新的或未来的行为。
如果您的功能标记系统不支持运行时配置,那么您可能必须重新启动您正在测试的进程才能切换开关,或者更糟糕的是,将制品重新部署到测试环境中。这会对您的验证过程的周期时间产生非常不利的影响,进而影响 CI/CD 提供的至关重要的反馈循环。为了避免这个问题,请考虑公开一个端点,该端点允许对功能标记进行动态内存中重新配置。当您使用实验性开关之类的东西时,这种类型的覆盖变得更加必要,因为使用实验性开关时,要执行开关的两个路径更加麻烦。
这种动态重新配置特定服务实例的能力是一把非常锋利的工具。如果使用不当,它会在共享环境中造成很多痛苦和混乱。此功能应该只由自动化测试使用,并且可能作为手动探索性测试和调试的一部分使用。如果需要一个更通用的开关控制机制用于生产环境,那么最好使用上面“开关配置”部分中讨论的真正的分布式配置系统来构建。
放置切换的位置
边缘切换
对于需要按请求上下文(实验性开关、权限开关)的开关类别,将开关点放在系统的边缘服务中是有意义的——即向最终用户公开功能的公开 Web 应用程序。这是用户的个人请求首次进入您的域的地方,因此也是您的开关路由器拥有最多可用上下文来根据用户及其请求做出开关决策的地方。将开关点放在系统边缘的一个附带好处是,它可以将繁琐的条件开关逻辑排除在系统的核心之外。在许多情况下,您可以将开关点直接放在您渲染 HTML 的地方,如下面的 Rails 示例所示
someFile.erb
<%= if featureDecisions.showRecommendationsSection? %>
<%= render 'recommendations_section' %>
<% end %>
当您控制对尚未准备好发布的新用户功能的访问时,将开关点放在边缘也是有意义的。在这种情况下,您可以再次使用简单地显示或隐藏 UI 元素的开关来控制访问。例如,假设您正在构建使用 Facebook 登录到您的应用程序的功能,但还没有准备好向用户推出。此功能的实现可能涉及到体系结构中各个部分的更改,但您可以使用 UI 层的一个简单功能开关来控制功能的公开,该开关可以隐藏“使用 Facebook 登录”按钮。
有趣的是,对于某些类型的功能标记,大部分未发布的功能本身实际上可能是公开的,但位于用户无法发现的 URL 上。
核心切换
还有其他类型的较低级别的开关必须放置在体系结构的更深处。这些开关通常是技术性的,用于控制某些功能在内部的实现方式。例如,一个发布开关,它控制是使用一个新的缓存基础设施放在第三方 API 的前面,还是直接将请求路由到该 API。在这些情况下,唯一明智的选择是在功能被切换的服务中本地化这些切换决策。
管理功能切换的维护成本
功能标记有迅速增长的趋势,尤其是在首次引入时。它们创建起来既有用又便宜,因此经常会创建很多。然而,开关确实有其维护成本。它们要求您在代码中引入新的抽象或条件逻辑。它们还引入了沉重的测试负担。Knight Capital Group 4.6 亿美元的错误就是一个警示故事,说明了如果管理不当(以及其他原因),功能标记可能会导致什么问题。
精明的团队将他们的功能开关视为有维护成本的库存,并努力尽可能地减少库存。
精明的团队将代码库中的功能开关视为有维护成本的库存,并力求尽可能地减少库存。为了保持功能标记的数量可控,团队必须积极主动地删除不再需要的功能标记。有些团队有一条规则,即每当首次引入发布开关时,都要在团队的积压工作中添加一个开关删除任务。其他团队则为他们的开关设定“到期日期”。有些团队甚至会创建“定时炸弹”,如果一个功能标记在其到期日期之后仍然存在,就会导致测试失败(甚至拒绝启动应用程序!)。我们也可以应用精益方法来减少库存,限制系统在任何时候允许拥有的功能标记的数量。一旦达到该限制,如果有人想添加一个新的开关,他们首先需要完成删除现有开关的工作。
致谢
感谢 Brandon Byars 和 Max Lincoln 对本文早期草稿提供的详细反馈和建议。非常感谢 Martin Fowler 的支持、建议和鼓励。感谢我的同事 Michael Wongwaisayawan 和 Leo Shaw 对本文进行的编辑审阅,以及 Fernanda Alcocer 使我的图表看起来不那么难看。
重大修订
2017 年 10 月 9 日:突出显示功能标记作为同义词
2016 年 2 月 8 日:最后一部分:完整文章发布
2016 年 2 月 5 日:第 7 部分:使用开关系统
2016 年 2 月 2 日:第 6 部分:开关配置
2016 年 1 月 28 日:第 5 部分:实现技术
2016 年 1 月 27 日:第 4 部分:管理不同类别的开关
2016 年 1 月 22 日:第 3 部分:运维和权限开关
2016 年 1 月 21 日:第二部分:发布和实验开关
2016 年 1 月 19 日:发布第一部分:开关的故事