
领域逻辑与 SQL
在过去的几十年里,我们看到数据库导向的软件开发人员和内存应用程序软件开发人员之间存在着越来越大的差距。这导致了关于如何使用 SQL 和存储过程等数据库功能的许多争议。在本文中,我将探讨将业务逻辑放在 SQL 查询中还是内存代码中的问题,主要考虑基于一个简单但丰富的 SQL 查询示例的性能和可维护性。
2003 年 2 月

看看任何最近关于构建企业应用程序的书籍(比如我最近的 P of EAA),你会发现逻辑被分解成多个层,这些层将企业应用程序的不同部分隔离开来。不同的作者使用不同的层,但一个共同的主题是将领域逻辑(业务规则)与数据源逻辑(数据来自哪里)分开。由于企业应用程序数据的大部分存储在关系数据库上,因此这种分层方案试图将业务逻辑与关系数据库分开。
许多应用程序开发人员,尤其是像我这样的强大的 OO 开发人员,倾向于将关系数据库视为一种存储机制,最好将其隐藏起来。框架的存在宣称屏蔽应用程序开发人员免受 SQL 复杂性的优势。
然而,SQL 远不止简单的更新和检索数据机制。SQL 的查询处理可以执行许多任务。通过隐藏 SQL,应用程序开发人员排除了一个强大的工具。
在本文中,我想探讨使用可能包含领域逻辑的丰富 SQL 查询的优缺点。我必须声明,我将 OO 偏见带入了讨论,但我也在另一边生活过。(一位前客户的 OO 专家组把我赶出了公司,因为我是一个“数据建模师”。)
复杂查询
所有关系数据库都支持一种标准查询语言——SQL。从根本上说,我相信 SQL 是关系数据库取得如此成功的主要原因。一种与数据库交互的标准方式提供了高度的供应商独立性,这既有助于关系数据库的兴起,也有助于抵御 OO 的挑战。
SQL 具有许多优点,但其中一个特别强大的功能是查询数据库的强大功能,允许客户端使用很少的 SQL 代码行来过滤和汇总大量数据。然而,使用强大的 SQL 查询通常会嵌入领域逻辑,这违背了分层企业应用程序架构的基本原则。
为了进一步探讨这个主题,让我们玩一个简单的例子。我们将从一个类似于 图 1 的数据模型开始。想象一下,我们的公司有一个特殊的折扣,我们称之为 Cuillen。如果客户在一个月内至少有一笔订单包含超过 5000 美元的 Talisker,他们就有资格获得 Cuillen 折扣。请注意,同一个月的两笔 3000 美元的订单不计入,必须有一笔超过 5000 美元的订单。假设您想查看特定客户,并确定他们在过去一年中哪些月份有资格获得 Cuillen 折扣。我将忽略用户界面,只假设我们想要的是一个与他们合格月份相对应的数字列表。
{kind=link}
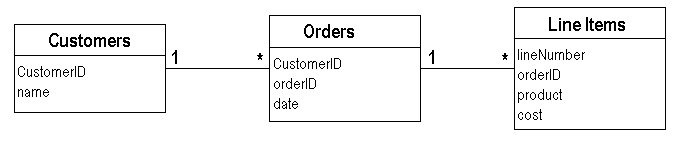
图 1:示例的数据库模式(UML 符号)
我们可以用很多方法来回答这个问题。我将从三个粗略的替代方案开始:事务脚本、领域模型和复杂 SQL。
对于所有这些示例,我将使用 Ruby 编程语言来演示它们。我在这里冒了一点险:通常我使用 Java 和/或 C# 来演示这些东西,因为大多数应用程序开发人员都可以阅读基于 C 的语言。我选择 Ruby 作为一种实验。我喜欢这种语言,因为它鼓励简洁但结构良好的代码,并使以 OO 风格编写代码变得容易。它是我用于脚本编写的首选语言。我添加了一个 简短的 ruby 语法指南,它基于我在这里使用的 ruby。
事务脚本
事务脚本是我在 P of EAA 中为处理请求的程序化风格而创造的模式名称。在这种情况下,该过程读取它可能需要的所有数据,然后在内存中进行选择和操作,以确定需要哪些月份。
def cuillen_months name
customerID = find_customerID_named(name)
result = []
find_orders(customerID).each do |row|
result << row['date'].month if cuillen?(row['orderID'])
end
return result.uniq
end
def cuillen? orderID
talisker_total = 0.dollars
find_line_items_for_orderID(orderID).each do |row|
talisker_total += row['cost'].dollars if 'Talisker' == row['product']
end
return (talisker_total > 5000.dollars)
end
这两个方法,cuillen_months 和 cuillen?,包含领域逻辑。它们使用许多“查找器”方法向数据库发出查询。
def find_customerID_named name
sql = 'SELECT * from customers where name = ?'
return $dbh.select_one(sql, name)['customerID']
end
def find_orders customerID
result = []
sql = 'SELECT * FROM orders WHERE customerID = ?'
$dbh.execute(sql, customerID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
def find_line_items_for_orderID orderID
result = []
sql = 'SELECT * FROM lineItems l WHERE orderID = ?'
$dbh.execute(sql, orderID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
在许多方面,这是一种非常简单的方法,特别是它在使用 SQL 方面非常低效——需要多次查询来提取数据(2 + N,其中 N 是订单数量)。现在不要太担心,我将在后面讨论如何改进它。相反,专注于方法的本质:读取所有需要考虑的数据,然后循环遍历并选择所需的数据。
(顺便说一下,上面的领域逻辑是那样做的,以便于阅读——但这并不是我认为是惯用的 Ruby。我更喜欢下面的方法,它更多地利用了 Ruby 强大的块和集合方法。这段代码对许多人来说看起来很奇怪,但 Smalltalk 程序员应该会喜欢它。)
def cuillen_months2 name
customerID = find_customerID_named(name)
qualifying_orders = find_orders(customerID).select {|row| cuillen?(row['orderID'])}
return (qualifying_orders.collect {|row| row['date'].month}).uniq
end
领域模型
对于第二个起点,我们将考虑一个经典的面向对象的领域模型。在这种情况下,我们创建内存对象,在本例中,它们反映了数据库表(在实际系统中,它们通常不是完全的镜像。)一组查找器对象从数据库加载这些对象,一旦我们在内存中有了这些对象,我们就在它们上运行逻辑。
我们将从查找器开始。它们将查询猛击到数据库并创建对象。
class CustomerMapper
def find name
result = nil
sql = 'SELECT * FROM customers WHERE name = ?'
return load($dbh.select_one(sql, name))
end
def load row
result = Customer.new(row['customerID'], row['NAME'])
result.orders = OrderMapper.new.find_for_customer result
return result
end
end
class OrderMapper
def find_for_customer aCustomer
result = []
sql = "SELECT * FROM orders WHERE customerID = ?"
$dbh.select_all(sql, aCustomer.db_id) {|row| result << load(row)}
load_line_items result
return result
end
def load row
result = Order.new(row['orderID'], row['date'])
return result
end
def load_line_items orders
#Cannot load with load(row) as connection gets busy
orders.each do
|anOrder| anOrder.line_items = LineItemMapper.new.find_for_order anOrder
end
end
end
class LineItemMapper
def find_for_order order
result = []
sql = "select * from lineItems where orderID = ?"
$dbh.select_all(sql, order.db_id) {|row| result << load(row)}
return result
end
def load row
return LineItem.new(row['lineNumber'], row['product'], row['cost'].to_i.dollars)
end
end
这些加载方法加载以下类
class Customer...
attr_accessor :name, :db_id, :orders
def initialize db_id, name
@db_id, @name = db_id, name
end
class Order...
attr_accessor :date, :db_id, :line_items
def initialize (id, date)
@db_id, @date, @line_items = id, date, []
end
class LineItem...
attr_reader :line_number, :product, :cost
def initialize line_number, product, cost
@line_number, @product, @cost = line_number, product, cost
end
确定 cuillen 月份的逻辑可以在几个方法中描述。
class Customer...
def cuillenMonths
result = []
orders.each do |o|
result << o.date.month if o.cuillen?
end
return result.uniq
end
class Order...
def cuillen?
discountableAmount = 0.dollars
line_items.each do |line|
discountableAmount += line.cost if 'Talisker' == line.product
end
return discountableAmount > 5000.dollars
end
此解决方案比事务脚本版本更长。但是,值得指出的是,加载对象的逻辑和实际的领域逻辑更加分离。对这组领域对象的任何其他处理都将使用相同的加载逻辑。因此,如果我们正在执行许多不同的领域逻辑,加载逻辑的努力将被摊销到所有领域逻辑中,这将使其不那么成为问题。这种成本可以通过 元数据映射 等技术进一步降低。
同样,有很多 SQL 查询(2 + 订单数量)。
SQL 中的逻辑
对于前两个,数据库几乎被用作存储机制。我们所做的只是请求特定表中的所有记录,并进行一些非常简单的过滤。SQL 是一种非常强大的查询语言,可以做比这些示例中使用的简单过滤更多的事情。
充分利用 SQL,我们可以将所有工作都放在 SQL 中
def discount_months customerID
sql = <<-END_SQL
SELECT DISTINCT MONTH(o.date) AS month
FROM lineItems l
INNER JOIN orders o ON l.orderID = o.orderID
INNER JOIN customers c ON o.customerID = c.customerID
WHERE (c.name = ?) AND (l.product = 'Talisker')
GROUP BY o.orderID, o.date, c.NAME
HAVING (SUM(l.cost) > 5000)
END_SQL
result = []
$dbh.select_all(sql, customerID) {|row| result << row['month']}
return result
end
虽然我将此称为复杂查询,但它只是与前面示例中简单的 select 和 where 子句查询相比比较复杂。SQL 查询可以比这个查询复杂得多,尽管许多应用程序开发人员会回避像这样简单的查询。
查看性能
人们首先考虑的第一个问题之一是性能。就我个人而言,我认为性能不应该成为首要问题。我的理念是,大多数时候你应该专注于编写可维护的代码。然后使用分析器来识别热点,然后只用更快的但不太清晰的代码替换这些热点。我这样做主要是因为在大多数系统中,只有很少一部分代码实际上是性能关键的,并且改进结构良好、可维护代码的性能要容易得多。
但无论如何,让我们首先考虑性能权衡。在我的小笔记本电脑上,复杂 SQL 查询的执行速度比其他两种方法快 20 倍。现在,你不能从一台轻巧但老旧的笔记本电脑上得出任何关于数据中心服务器性能的结论,但我认为复杂查询的速度不会比内存方法慢一个数量级。
部分原因是内存方法的编写方式在 SQL 查询方面非常低效。正如我在它们的描述中指出的那样,每个方法都会为客户的每个订单发出一个 SQL 查询——而我的测试数据库每个客户有一千个订单。
我们可以通过重写内存程序来使用单个 SQL 查询来显著减少这种负载。我将从事务脚本开始。
SQL = <<-END_SQL
SELECT * from orders o
INNER JOIN lineItems li ON li.orderID = o.orderID
INNER JOIN customers c ON c.customerID = o.customerID
WHERE c.name = ?
END_SQL
def cuillen_months customer_name
orders = {}
$dbh.select_all(SQL, customer_name) do |row|
process_row(row, orders)
end
result = []
orders.each_value do |o|
result << o.date.month if o.talisker_cost > 5000.dollars
end
return result.uniq
end
def process_row row, orders
orderID = row['orderID']
orders[orderID] = Order.new(row['date']) unless orders[orderID]
if 'Talisker' == row['product']
orders[orderID].talisker_cost += row['cost'].dollars
end
end
class Order
attr_accessor :date, :talisker_cost
def initialize date
@date, @talisker_cost = date, 0.dollars
end
end
这对事务脚本来说是一个很大的改变,但它将速度提高了三倍。
我可以对领域模型做类似的技巧。在这里,我们看到了领域模型更复杂结构的优势。我只需要修改加载方法,领域对象本身的业务逻辑不需要改变。
class CustomerMapper
SQL = <<-END_SQL
SELECT c.customerID,
c.NAME as NAME,
o.orderID,
o.date as date,
li.lineNumber as lineNumber,
li.product as product,
li.cost as cost
FROM customers c
INNER JOIN orders o ON o.customerID = c.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE c.name = ?
END_SQL
def find name
result = nil
om = OrderMapper.new
lm = LineItemMapper.new
$dbh.execute (SQL, name) do |sth|
sth.each do |row|
result = load(row) if result == nil
unless result.order(row['orderID'])
result.add_order(om.load(row))
end
result.order(row['orderID']).add_line_item(lm.load(row))
end
end
return result
end
(当我说是说我无需修改领域对象时,我撒了一个小谎。为了获得良好的性能,我需要更改客户的数据结构,以便订单保存在哈希表中而不是数组中。但同样,这是一个非常独立的更改,并没有影响确定折扣的代码。)
这里有几点需要注意。首先,值得记住的是,内存代码通常可以通过更智能的查询来提升。始终值得查看你是否多次调用数据库,以及是否有一种方法可以用单个调用来完成。当你有一个领域模型时,这一点尤其容易被忽视,因为人们通常一次考虑一个类。(我甚至见过有人一次加载一行,但这种病态行为相对罕见。)
事务脚本和领域模型之间最大的区别之一是更改查询结构的影响。对于事务脚本,它几乎意味着更改整个脚本。此外,如果有很多使用类似数据的领域逻辑脚本,每个脚本都必须更改。使用领域模型,你更改代码中一个很好地分离的部分,领域逻辑本身不需要更改。如果你有很多领域逻辑,这将是一件大事。这是事务脚本和领域逻辑之间的一般权衡——在数据库访问的复杂性方面存在初始成本,只有当你有很多领域逻辑时,这种成本才会得到回报。
但即使使用多表查询,内存方法的速度仍然不如复杂 SQL——在我的情况下,速度慢了 6 倍。这是有道理的:复杂 SQL 在数据库中执行选择和成本汇总,只需要将少量值传回客户端,而内存方法需要将五千行数据传回客户端。
性能不是决定走哪条路的唯一因素,但它通常是决定性的因素。如果你有一个绝对需要改进的热点,那么其他因素就排在第二位。因此,许多领域模型的粉丝遵循在内存中执行操作作为默认操作的系统,并且仅在必须时才使用复杂查询等方法来处理热点。
还值得指出的是,这个例子是发挥数据库优势的一个例子。许多查询没有这个查询中强大的选择和聚合元素,并且不会显示出如此大的性能变化。此外,多用户场景通常会导致查询行为发生令人惊讶的变化,因此必须在现实的多用户负载下进行真正的分析。你可能会发现锁定问题超过了你能通过更快的单个查询获得的任何东西。
可修改性
对于任何长寿的企业应用程序,您可以确定一件事 - 它会发生很多变化。因此,您必须确保系统以易于更改的方式组织。可修改性可能是人们将业务逻辑放在内存中的主要原因。
SQL 可以做很多事情,但它的能力也有限。它可以做的一些事情需要非常巧妙的编码,就像浏览数据集的中位数算法一样。其他则不可能在不诉诸非标准扩展的情况下实现,如果您想要可移植性,这是一个问题。
通常,您希望在将数据写入数据库之前运行业务逻辑,尤其是在处理一些待处理信息时。加载到数据库中可能会有问题,因为您通常希望待处理的会话数据与完全接受的数据隔离。这些会话数据通常不应该受到与完全接受的数据相同的验证规则的约束。
可理解性
SQL 通常被视为一种特殊的语言,应用程序开发人员不需要处理它。事实上,许多数据库框架喜欢说,通过使用它们,您可以避免处理 SQL。我一直觉得这是一个奇怪的论点,因为我一直对中等复杂的 SQL 比较熟悉。然而,许多开发人员发现 SQL 比传统语言更难处理,许多 SQL 习语对于除 SQL 专家以外的所有人来说都很难理解。
一个好的测试是查看这三种解决方案,看看哪一种使领域逻辑最容易理解,从而也最容易修改。我发现领域模型版本,它只有几个方法,是最容易理解的;很大程度上是因为数据访问是分离的。接下来,我更喜欢 SQL 版本而不是内存中的事务脚本。但我相信其他读者会有不同的偏好。
如果大多数团队成员对 SQL 不太熟悉,那么这是一个将领域逻辑与 SQL 分开的理由。(这也是考虑培训更多人员学习 SQL 的一个理由 - 至少要达到中等水平。)这是一种需要考虑团队构成的情况 - 人员会影响架构决策。
避免重复
我遇到的最简单但最强大的设计原则之一是避免重复 - 由 Pragmatic Programmers 称为 DRY(不要重复自己)原则。
为了考虑 DRY 原则在这种情况下,让我们考虑此应用程序的另一个需求 - 一个特定月份客户订单列表,显示订单 ID、日期、总成本以及该订单是否符合 Cuillen 计划的合格订单。所有这些都按总成本排序。
使用领域对象方法来处理此查询,我们需要在订单中添加一个方法来计算总成本。
class Order...
def total_cost
result = 0.dollars
line_items.each {|line| result += line.cost}
return result
end
有了它,就可以轻松地打印订单列表。
class Customer
def order_list month
result = ''
selected_orders = orders.select {|o| month == o.date.month}
selected_orders.sort! {|o1, o2| o2.total_cost <=> o1.total_cost}
selected_orders.each do |o|
result << sprintf("%10d %20s %10s %3s\n",
o.db_id, o.date, o.total_cost, o.discount?)
end
return result
end
使用单个 SQL 语句定义相同的查询需要一个相关子查询 - 一些人觉得它很令人生畏。
def order_list customerName, month
sql = <<-END_SQL
SELECT o.orderID, o.date, sum(li.cost) as totalCost,
CASE WHEN
(SELECT SUM(li.cost)
FROM lineitems li
WHERE li.product = 'Talisker'
AND o.orderID = li.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE (c.name = ?)
AND (MONTH(o.date) = ?)
GROUP by o.orderID, o.date
ORDER BY totalCost desc
END_SQL
result = ""
$dbh.select_all(sql, customerName, month) do |row|
result << sprintf("%10d %20s %10s %3s\n",
row['orderID'],
row['date'],
row['totalCost'],
row['isCuillen'])
end
return result
end
不同的人对这两个哪个更容易理解会有不同的看法。但我在这里咀嚼的问题是重复问题。此查询重复了原始查询中的逻辑,该查询只给出月份。领域对象方法没有这种重复 - 如果我想要更改 Cuillen 计划的定义,我只需要更改 cuillen? 的定义,所有使用都会更新。
现在,在重复问题上贬低 SQL 是不公平的 - 因为您也可以在丰富的 SQL 方法中避免重复。诀窍,正如数据库爱好者必须急于指出,是使用视图。
为了简单起见,我可以定义一个名为 Orders2 的视图,它基于以下查询。
SELECT TOP 100 PERCENT
o.orderID, c.name, c.customerID, o.date,
SUM(li.cost) AS totalCost,
CASE WHEN
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker'
AND o.orderID = li2.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.orders o
INNER JOIN dbo.lineItems li ON o.orderID = li.orderID
INNER JOIN dbo.CUSTOMERS c ON o.customerID = c.customerID
GROUP BY o.orderID, c.name, c.customerID, o.date
ORDER BY totalCost DESC
我现在可以使用此视图来获取月份和生成订单列表。
def cuillen_months_view customerID
sql = "SELECT DISTINCT month(date) FROM orders2 WHERE name = ? AND isCuillen = 'Y'"
result = []
$dbh.select_all(sql, customerID) {|row| result << row[0]}
return result
end
def order_list_from_view customerName, month
result = ''
sql = "SELECT * FROM Orders2 WHERE name = ? AND month(date) = ?"
$dbh.select_all(SQL, customerName, month) do |row|
result << sprintf("%10d %10s %10s\n",
row['orderID'],
row['date'],
row['isCuillen'])
end
return result
end
视图简化了这两个查询,并将关键业务逻辑放在一个地方。
似乎人们很少讨论使用这种视图来避免重复。我看到的关于 SQL 的书籍似乎没有讨论做这种事情。在某些环境中,由于数据库和应用程序开发人员之间的组织和文化差异,这很困难。应用程序开发人员通常不允许定义视图,而数据库开发人员形成了一个瓶颈,阻止应用程序开发人员完成这种视图。DBA 甚至可能拒绝构建仅供单个应用程序使用的视图。但我的观点是,SQL 应该像其他任何东西一样得到同等的关注。
封装
封装是面向对象设计的一个众所周知的原则,我认为它也适用于通用软件设计。本质上,它说一个程序应该被分成模块,这些模块将数据结构隐藏在过程调用的接口后面。这样做是为了允许您更改底层数据结构,而不会在整个系统中造成大的连锁反应。
在这种情况下,问题是如何封装数据库?一个好的封装方案将允许我们更改数据库模式,而不会导致应用程序中进行痛苦的编辑。
对于企业应用程序,一种常见的封装形式是分层,我们努力将领域逻辑与数据源逻辑分离。这样,当我们更改数据库设计时,处理业务逻辑的代码就不会受到影响。
领域模型版本是这种封装的一个很好的例子。业务逻辑只在内存对象上工作。数据如何到达那里是完全分离的。事务脚本方法通过查找方法进行了一些数据库封装,尽管数据库结构通过返回的结果集更明显地显示出来。
在应用程序世界中,您可以通过过程和对象的 API 实现封装。SQL 等效于使用视图。如果您更改了一个表,您可以创建一个支持旧表的视图。这里最大的问题是更新,更新通常无法通过视图正确完成。这就是为什么许多商店将所有 DML 包裹在存储过程中。
封装不仅仅是支持对视图的更改。它还与访问数据和定义业务逻辑之间的区别有关。使用 SQL,这两个可以很容易地模糊,但您仍然可以进行某种形式的分离。
例如,考虑我上面定义的视图以避免查询中的重复。该视图是一个可以沿数据源和业务逻辑分离线拆分的单个视图。数据源视图看起来像这样
SELECT o.orderID, o.date, c.customerID, c.name,
SUM(li.cost) AS total_cost,
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker' AND o.orderID =li2.orderID
) AS taliskerCost
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN dbo.lineItems li ON li.orderID = o.orderID
GROUP BY o.orderID, o.date, c.customerID, c.name
然后,我们可以在其他更关注领域逻辑的视图中使用此视图。以下是一个指示 Cuillen 资格的视图
SELECT orderID, date, customerID, name, total_cost,
CASE WHEN taliskerCost > 5000 THEN 'Y' ELSE 'N' END AS isCuillen
FROM dbo.OrdersTal
这种思维方式也可以应用于我们将数据加载到领域模型中的情况。之前我谈到过如何通过将 Cuillen 月份的整个查询替换为单个 SQL 查询来处理领域模型的性能问题。另一种方法是使用上述数据源视图。这将允许我们保持更高的性能,同时仍然将领域逻辑保留在领域模型中。只有在必要时才使用 延迟加载 加载行项目,但可以通过视图引入合适的摘要信息。
使用视图,或者实际上是存储过程,只能在一定程度上提供封装。在许多企业应用程序中,数据来自多个来源,不仅仅是多个关系数据库,还包括遗留系统、其他应用程序和文件。事实上,XML 的增长可能会看到更多数据来自通过网络共享的平面文件。在这种情况下,真正的完全封装只能通过应用程序代码中的一个层来完成,这进一步意味着领域逻辑也应该驻留在内存中。
数据库可移植性
许多开发人员回避复杂 SQL 的一个原因是数据库可移植性问题。毕竟,SQL 的承诺是它允许您在众多数据库平台上使用相同的标准 SQL,从而可以轻松地更改数据库供应商。
实际上,这始终是一个有点模糊的问题。实际上,SQL 大部分是标准的,但到处都有各种各样的陷阱。但是,小心谨慎,您可以创建 SQL,它在数据库服务器之间切换时不会太痛苦。但要做到这一点,您会失去很多功能。
关于数据库可移植性的决定最终取决于您的项目。如今,这已经不像以前那么重要了。数据库市场已经洗牌,大多数地方都属于三大阵营之一。公司通常会对他们所在的阵营有强烈的承诺。如果您认为由于这种投资,更改数据库非常不可能,那么您不妨开始利用您的数据库提供的特殊功能。
有些人仍然需要可移植性,例如提供可以安装并与多个数据库交互的产品的人员。在这种情况下,反对将逻辑放入 SQL 的论据更强,因为您必须非常小心地使用哪些部分的 SQL。
可测试性
可测试性不是在关于设计讨论中经常出现的话题。测试驱动开发 (TDD) 的一个好处是,它重新燃起了可测试性是设计的重要组成部分的观念。
SQL 中的常见做法似乎是不进行测试。事实上,发现基本视图和存储过程甚至没有保存在配置管理工具中并不罕见。然而,完全有可能拥有可测试的 SQL。流行的 xunit 系列有很多工具可以用于在数据库环境中进行测试。诸如测试数据库之类的 演化数据库技术 可用于提供与 TDD 程序员享受的非常相似的可测试环境。
主要影响因素是性能。虽然直接 SQL 在生产中通常更快,但如果数据库接口设计得可以将实际数据库连接替换为 服务存根,那么在内存中运行业务逻辑测试可能会快得多。
总结
到目前为止,我已经讨论了问题。现在是得出结论的时候了。从根本上说,您必须考虑我在这里讨论的各种问题,根据您的偏见判断它们,并决定采用哪种策略来使用丰富的查询并将领域逻辑放在其中。
我观察到的情况是,最关键的因素之一是您的数据是否来自单个逻辑关系数据库,还是分散在大量不同的、通常是非 SQL 的来源中。如果它分散了,那么您应该在内存中构建一个数据源层来封装您的数据源并将您的领域逻辑保留在内存中。在这种情况下,SQL 作为一种语言的优势就不是问题,因为并非所有数据都在 SQL 中。
当您的绝大多数数据位于单个逻辑数据库中时,情况就变得有趣了。在这种情况下,您有两个主要问题需要考虑。一个是编程语言的选择:SQL 与您的应用程序语言。另一个是代码运行的位置,SQL 在数据库中,还是在内存中。
SQL 使某些事情变得容易,但其他事情却更难。有些人发现 SQL 很容易使用,而另一些人则发现它非常神秘。团队的个人舒适度在这里是一个大问题。我建议,如果您选择将大量逻辑放入 SQL 中,不要指望它具有可移植性 - 使用您供应商的所有扩展,并愉快地将自己绑定到他们的技术。如果您想要可移植性,请将逻辑保留在 SQL 之外。
到目前为止,我已经讨论了可修改性问题。我认为这些问题应该放在首位,但应该被任何关键的性能问题所取代。如果您使用内存中方法,并且有可以通过更强大的查询解决的热点,那么就这样做。我建议看看您如何将性能增强查询组织为数据源查询,如上所述。这样,您可以最大限度地减少将领域逻辑放入 SQL 中。
重大修订
2003 年 2 月