
构建 Boba AI
在构建 LLM 驱动的生成式应用程序中学习的一些经验教训和模式
我们正在构建一个名为“Boba”的用于产品策略和生成式创意的实验性 AI 协同驾驶程序。在此过程中,我们学习了一些关于如何构建此类应用程序的有用经验教训,这些经验教训已转化为模式。这些模式使应用程序能够帮助用户更有效地与大型语言模型 (LLM) 交互,协调提示以获得更好的结果,帮助用户浏览错综复杂的对话流程,并整合 LLM 不具备的知识。
2023 年 6 月 29 日

Farooq 是 Thoughtworks 加拿大公司的产品策略负责人。作为一名拥有产品管理、策略和软件开发实践经验的专业通才,Farooq 喜欢与客户合作解决设计、业务和技术交汇处的难题。
Boba 是一个用于产品策略和生成式创意的实验性 AI 协同驾驶程序,旨在增强创意构思过程。它是一个由 LLM 驱动的应用程序,我们正在构建它来了解
- 如何设计和构建超越聊天、由 LLM 驱动的生成式体验
- 如何使用 AI 来增强我们的产品和策略流程,并打造
AI 协同驾驶程序是指一种由人工智能驱动的助手,旨在帮助用户完成各种任务,通常在不同的上下文中提供指导、支持和自动化。其应用示例包括导航系统、数字助手和软件开发环境。我们喜欢将协同驾驶程序视为用户可以与其合作执行特定领域任务的有效合作伙伴。
Boba 作为 AI 协同驾驶程序旨在增强策略构思和概念生成的早期阶段,这些阶段严重依赖于发散性思维的快速循环(也称为生成式创意)。我们通常通过与同行、客户和主题专家密切合作来实施生成式创意,以便我们可以制定和测试解决客户工作、痛点和收益的创新想法。这引出了一个问题,如果 AI 也能参与到同一个过程中会怎样?如果我们能够与 AI 合作,更快地生成和评估更多更好的想法,会怎样?Boba 开始通过使用 OpenAI 的 LLM 生成想法并回答问题来实现这一点,这些想法和问题可以帮助扩展和加速创意思维过程。对于 Boba 的第一个原型,我们决定专注于以下功能的基本版本
1. 研究信号和趋势:搜索网络以获取文章和新闻,以帮助您回答定性研究问题,例如
- 酒店行业今天如何使用生成式 AI?
- 2023 年及以后零售商面临的主要挑战是什么?
- 制药公司如何使用 AI 加速药物发现?
- 耐克最新财报电话会议的主要要点是什么?
- Reddit 上的人们对 Lululemon 的产品有什么看法?"
2. 创意矩阵:创意矩阵是一种概念化方法,用于在不同类别或维度的交叉点激发新想法。这涉及陈述一个战略提示,通常以“我们如何”问题形式,然后针对每个维度交叉点上的每个组合/排列的想法来回答该问题。例如
- 战略提示:“我们如何使用生成式 AI 来改变财富管理?”
- 维度 1 - 价值链阶段:客户获取、财务规划、投资组合构建、投资执行、绩效监控、风险管理、报告和沟通
- 维度 2 - 不同角色:针对员工、客户、合作伙伴
3. 情景构建:情景构建是一个通过研究商业、文化和技术变化信号来生成面向未来的故事的过程。情景用于在情境化的叙述中社交化学习,激发发散的产品思维,进行弹性/可取性测试,或为战略规划提供信息。例如,您可以使用以下内容提示 Boba,并根据不同的时间范围以及乐观程度和现实程度获得一组未来情景
- “酒店行业使用生成式 AI 来改变宾客体验”
- “辉瑞使用生成式 AI 加速药物发现”
- “向我展示 10 年后的支付未来”
4. 策略构思:使用“玩转胜利”策略框架,根据战略提示和可能的未来情景,集思广益“在哪里玩”和“如何获胜”的选择。例如,您可以用以下内容提示它
- 耐克如何使用生成式 AI 来改变其商业模式?
- 《环球邮报》如何增加读者数量和参与度?
5. 概念生成:根据战略提示,例如“我们如何”问题,生成多个产品或功能概念,其中包括价值主张推介和要测试的假设。
- 我们如何让老年人出行更方便?
- 我们如何让购物更社交?
6. 故事板:根据简单提示或基于当前或未来状态情景的详细叙述生成视觉故事板。关键功能是
- 生成插图场景来描述您的客户旅程
- 自定义样式和插图
- 直接从生成的情景中生成故事板
使用 Boba
Boba 是一个 Web 应用程序,它介导人类用户与大型语言模型(目前为 GPT 3.5)之间的交互。一个简单的 LLM Web 前端只是为用户提供了与 LLM 交谈的能力。这很有帮助,但这意味着用户需要学习如何有效地与 LLM 交互。即使在 LLM 引起公众兴趣的短时间内,我们也了解到,构建提示以使 LLM 能够获得有用的答案需要相当大的技巧,从而产生了“提示工程师”的概念。像 Boba 这样的协同驾驶程序应用程序添加了一系列结构化对话的 UI 元素。这允许用户发出简单的提示,应用程序可以对其进行操作,使用来自场景构建任务的一般知识以及用户在 UI 中的选择的元素来丰富简单的请求,从而从 LLM 获得更好的响应。
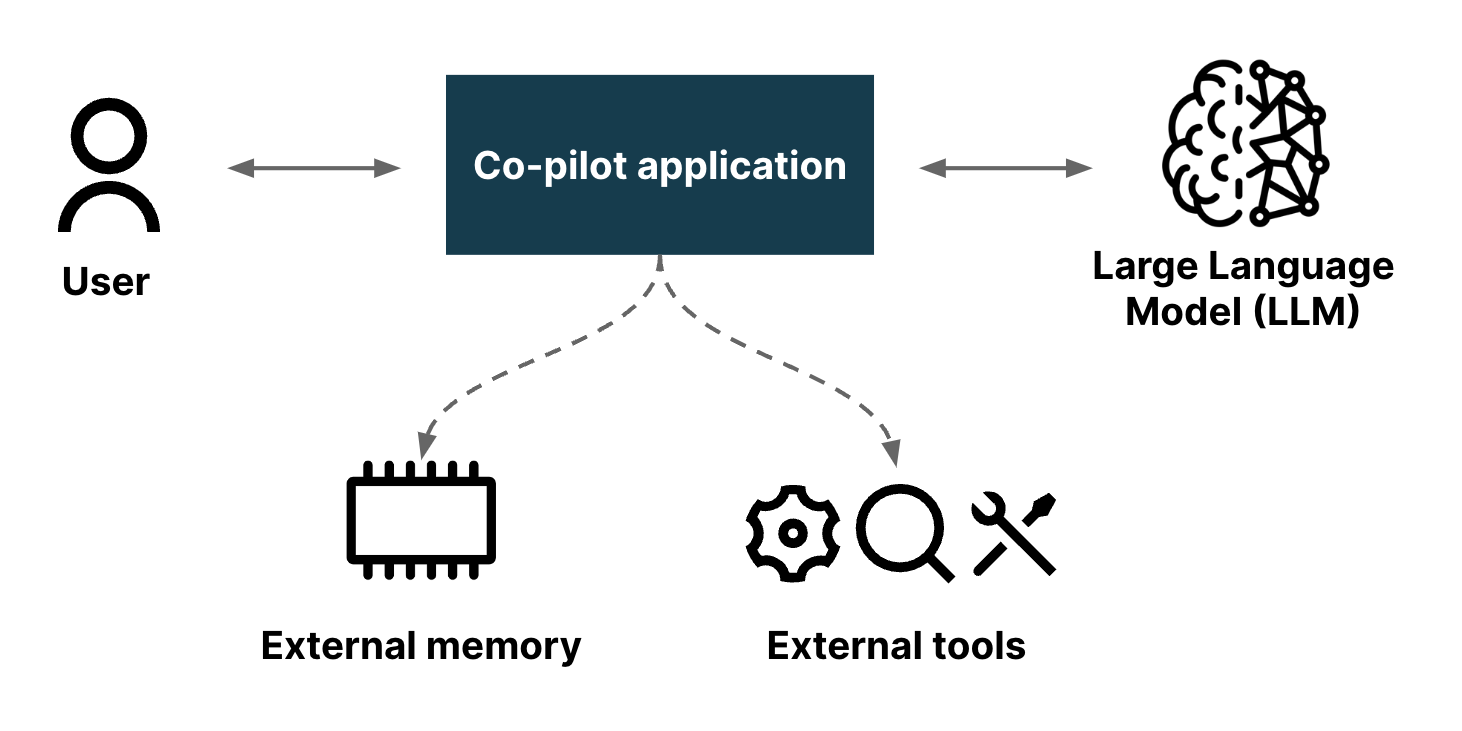
Boba 可以帮助完成许多产品策略任务。我们不会在这里描述所有任务,只描述足以让您了解 Boba 的功能,并为本文后面的模式提供上下文。
当用户导航到 Boba 应用程序时,他们会看到类似于此的初始屏幕
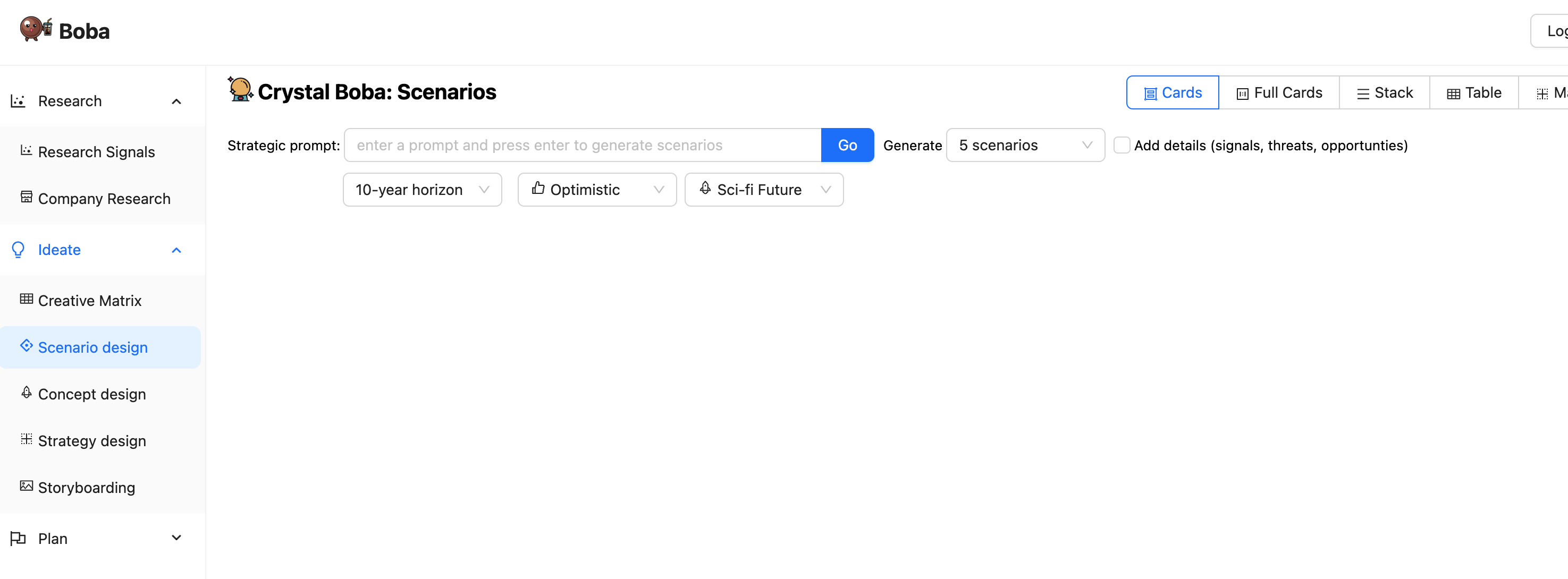
左侧面板列出了 Boba 支持的各种产品策略任务。单击其中一个任务会将主面板更改为该任务的 UI。对于其余的屏幕截图,我们将忽略左侧的任务面板。
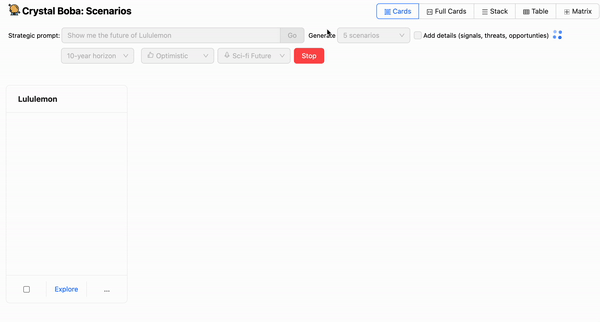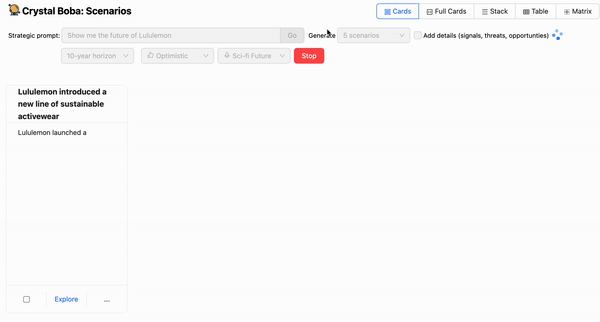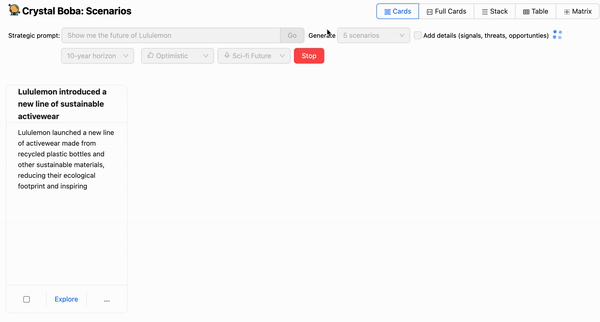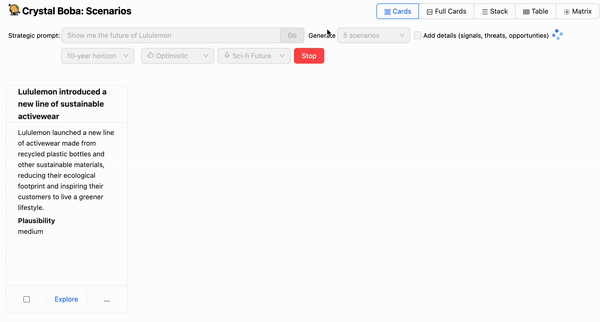
上面的屏幕截图查看了情景设计任务。这邀请用户输入提示,例如“向我展示零售的未来”。
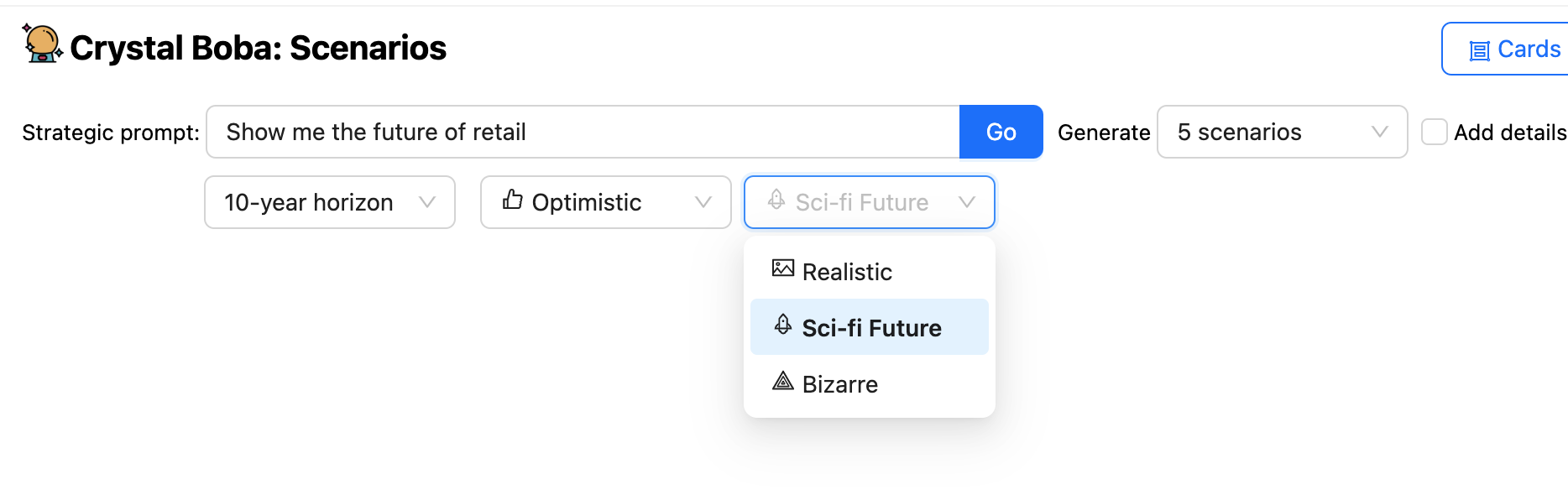
除了提示之外,UI 还提供了一些下拉菜单,允许用户建议时间范围和预测的性质。然后,Boba 会要求 LLM 生成情景,使用 模板提示 来使用来自场景构建任务的一般知识以及用户在 UI 中的选择的元素来丰富用户的提示。
Boba 从 LLM 接收 结构化响应,并将结果显示为每个情景的一组 UI 元素。
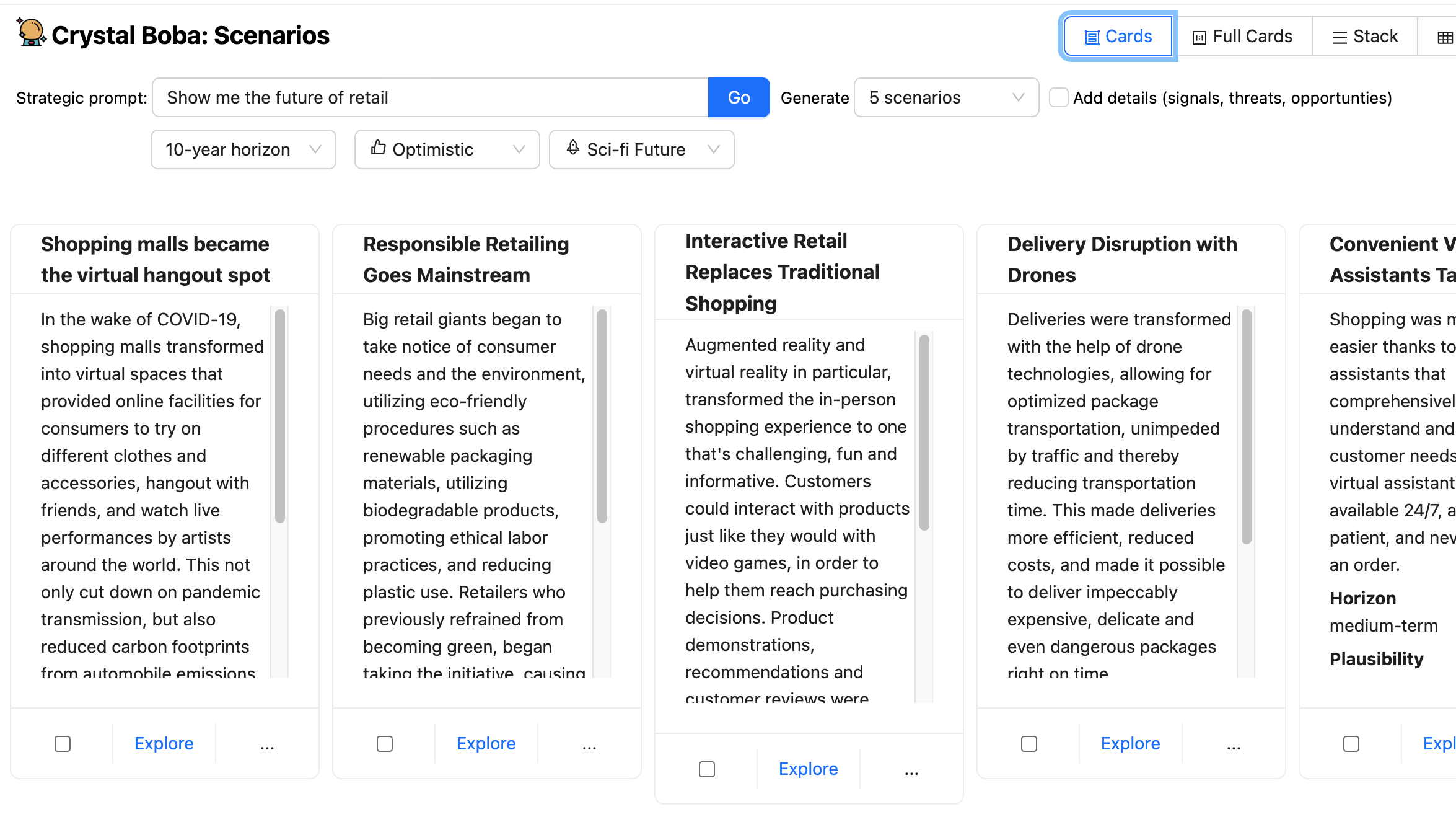
然后,用户可以选择其中一个情景并点击“探索”按钮,打开一个新的面板,其中包含一个进一步的提示,以便与 Boba 进行 上下文对话。
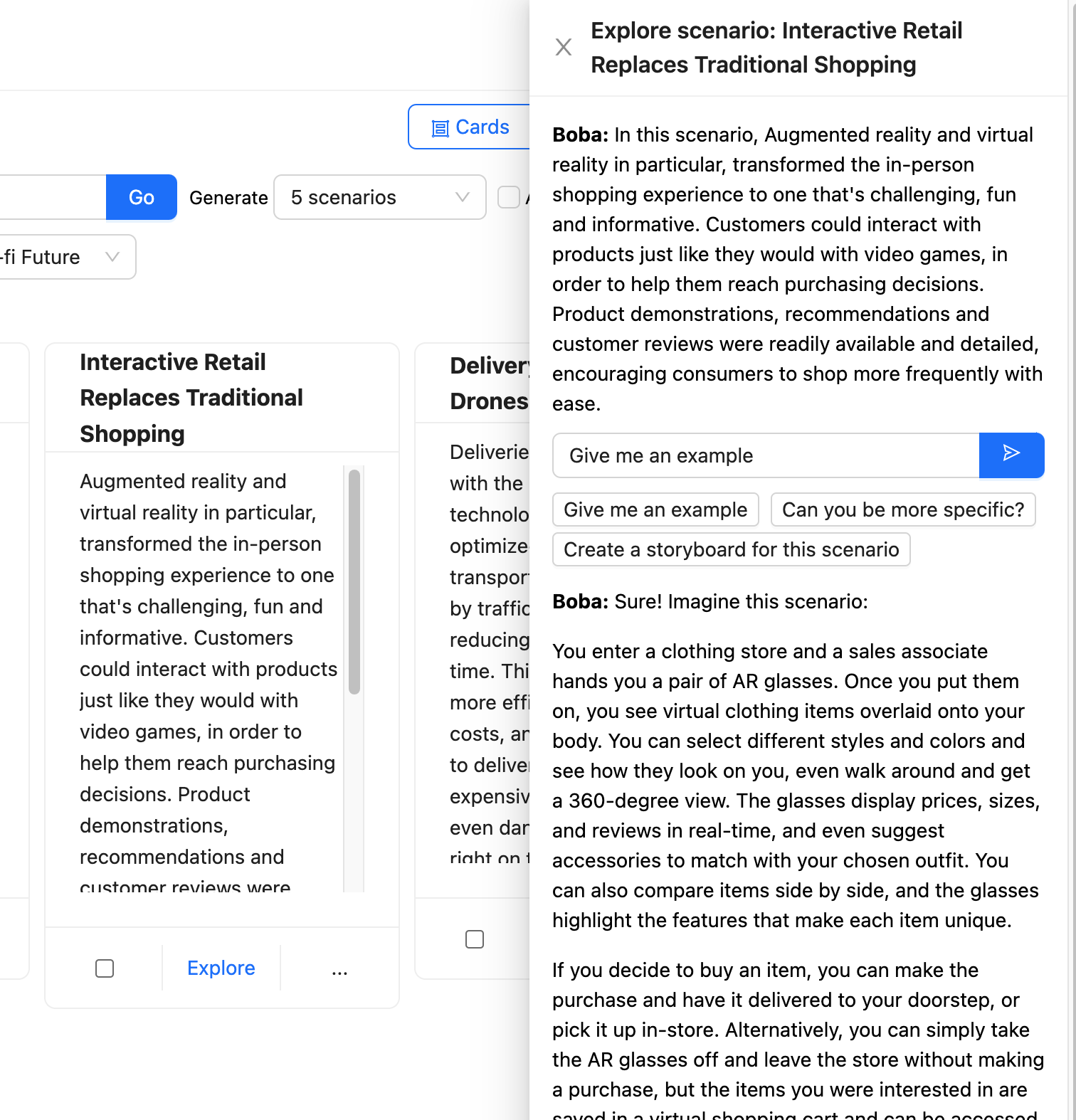
Boba 接受此提示并对其进行丰富以专注于所选情景的上下文,然后将其发送到 LLM。
Boba 使用 选择和携带上下文 来保存用户与 LLM 交互的各个部分,允许用户探索多个方向,而无需担心为每次交互提供正确的上下文。
使用 LLM 的困难之一是,它只在过去某个时间点之前的数据上进行训练,这使得它们不适合处理最新信息。Boba 具有一个名为“研究信号”的功能,该功能使用 嵌入外部知识 来将 LLM 与常规搜索功能结合起来。它接受提示的研究查询,例如“酒店行业今天如何使用生成式 AI?”,将该查询的丰富版本发送到搜索引擎,检索建议的文章,将每篇文章发送到 LLM 以进行摘要。
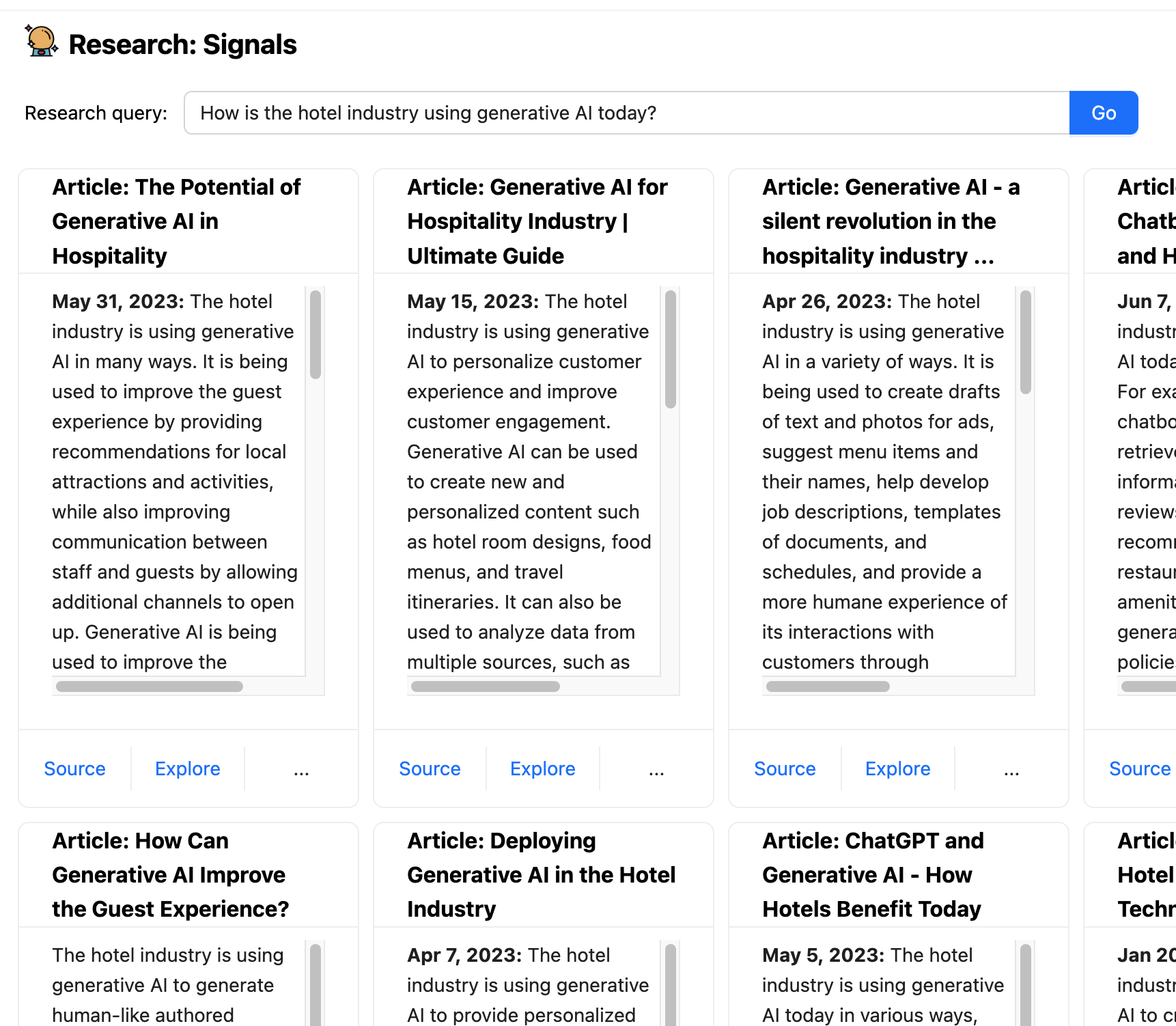
这是一个示例,说明协同驾驶程序应用程序如何处理 LLM 本身不适合的交互活动。这不仅提供了最新信息,我们还可以确保向用户提供源链接,并且这些链接不会是幻觉(只要搜索引擎没有食用错误的蘑菇)。
构建生成式协同驾驶应用程序的一些模式
在构建 Boba 的过程中,我们了解了很多关于在用户与 LLM(特别是 Open AI 的 GPT3.5/4)之间进行对话的不同模式和方法。此模式列表并不详尽,仅限于我们在构建 Boba 期间学到的经验教训。
模板提示
使用文本模板来丰富提示,使其具有上下文和结构
第一个也是最简单的模式是使用字符串模板作为提示,也称为链接。我们使用 Langchain,这是一个库,它为常见应用程序提供链和端到端链的标准接口。如果您以前使用过 Javascript 模板引擎,例如 Nunjucks、EJS 或 Handlebars,Langchain 提供了这些功能,但专门针对常见的提示工程工作流程而设计,包括函数输入变量、少样本提示模板、提示验证和更复杂的可组合提示链等功能。
例如,要在 Boba 中集思广益潜在的未来情景,您可以输入一个战略提示,例如“向我展示支付的未来”,甚至是一个简单的提示,例如公司的名称。用户界面如下所示

为该生成提供支持的提示模板类似于以下内容
You are a visionary futurist. Given a strategic prompt, you will create
{num_scenarios} futuristic, hypothetical scenarios that happen
{time_horizon} from now. Each scenario must be a {optimism} version of the
future. Each scenario must be {realism}.
Strategic prompt: {strategic_prompt}
正如您所料,LLM 的响应只会与提示本身一样好,因此,这就是良好的提示工程需求所在。虽然本文并非旨在介绍提示工程,但您会注意到这里使用了一些技巧,例如从告诉 LLM 采用角色 开始,特别是远见卓识的未来主义者。这是我们在应用程序的各个部分广泛依赖的一种技术,以生成更相关和有用的完成结果。
作为我们测试和学习提示工程工作流程的一部分,我们发现直接在 ChatGPT 中迭代提示提供了从想法到实验的最短路径,并有助于快速建立对提示的信心。话虽如此,我们还发现,我们在用户界面(约 80%)上花费的时间远远超过了 AI 本身(约 20%),特别是在工程提示方面。
我们还尽可能地保持提示模板的简单性,不包含条件语句。当我们需要根据用户输入大幅调整提示时,例如当用户点击“添加详细信息(信号、威胁、机会)”时,我们决定完全运行另一个提示模板,以避免提示模板变得过于复杂和难以维护。
结构化响应
告诉 LLM 以结构化数据格式进行响应
几乎所有使用LLM构建的应用程序都可能需要解析LLM的输出,以创建一些结构化或半结构化数据,以便代表用户进一步操作。对于Boba,我们希望尽可能使用JSON,因此我们尝试了许多不同的方法来让GPT返回格式良好的JSON。我们对GPT根据我们提示中的指令返回格式良好的JSON的良好性和一致性感到非常惊讶。例如,以下是场景生成响应指令可能的样子
You will respond with only a valid JSON array of scenario objects.
Each scenario object will have the following schema:
"title": <string>, //Must be a complete sentence written in the past tense
"summary": <string>, //Scenario description
"plausibility": <string>, //Plausibility of scenario
"horizon": <string>
我们同样惊讶于它可以支持相当复杂的嵌套JSON模式,即使我们在伪代码中描述了响应模式。以下是如何描述策略生成嵌套响应的示例
You will respond in JSON format containing two keys, "questions" and "strategies", with the respective schemas below:
"questions": [<list of question objects, with each containing the following keys:>]
"question": <string>,
"answer": <string>
"strategies": [<list of strategy objects, with each containing the following keys:>]
"title": <string>,
"summary": <string>,
"problem_diagnosis": <string>,
"winning_aspiration": <string>,
"where_to_play": <string>,
"how_to_win": <string>,
"assumptions": <string>
描述JSON响应模式的一个有趣的副作用是,我们还可以引导LLM在输出中提供更相关的响应。例如,对于创意矩阵,我们希望LLM考虑许多不同的维度(提示、行、列以及响应每个行和列交叉点处的提示的每个想法)
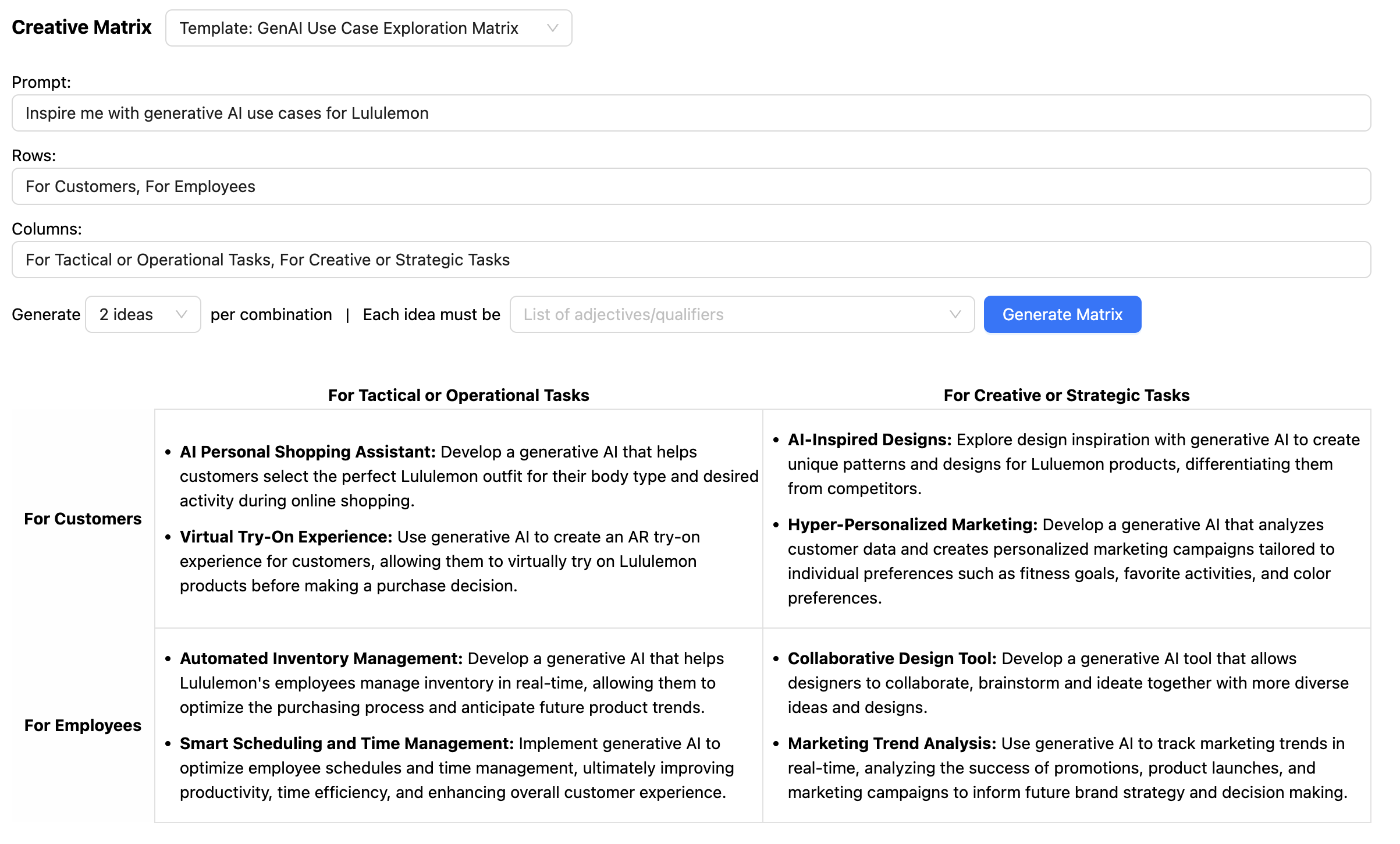
通过提供包含输出模式特定示例的少样本提示,我们能够让LLM在每个想法的正确上下文中“思考”(上下文是提示、行和列)
You will respond with a valid JSON array, by row by column by idea. For example:
If Rows = "row 0, row 1" and Columns = "column 0, column 1" then you will respond
with the following:
[
{{
"row": "row 0",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 0 and column 0",
"description": "idea 0 for prompt and row 0 and column 0"
}}
]
}},
{{
"column": "column 1",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 0 and column 1",
"description": "idea 0 for prompt and row 0 and column 1"
}}
]
}},
]
}},
{{
"row": "row 1",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 1 and column 0",
"description": "idea 0 for prompt and row 1 and column 0"
}}
]
}},
{{
"column": "column 1",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 1 and column 1",
"description": "idea 0 for prompt and row 1 and column 1"
}}
]
}}
]
}}
]
我们也可以更简洁和普遍地描述模式,但通过在示例中更加详细和具体,我们成功地将LLM响应的质量引导到我们想要的方向。我们认为这是因为LLM在“标记”中“思考”,在输出想法之前输出(即重复)行和列值,为生成的想法提供了更准确的上下文。
在撰写本文时,OpenAI发布了一项名为函数调用的新功能,它提供了一种不同的方法来实现格式化响应的目标。在这种方法中,开发人员可以将可调用函数签名及其各自的模式描述为JSON,并让LLM返回一个函数调用,其中包含以JSON格式提供的符合该模式的相应参数。这在您希望调用外部工具(例如,执行网络搜索或调用 API 来响应提示)的情况下特别有用。Langchain 也提供了类似的功能,但我认为他们很快就会在他们的外部工具 API 和 OpenAI 函数调用 API 之间提供原生集成。
实时进度
将响应流式传输到 UI,以便用户可以监控进度
在 LLM 之上实现图形用户界面时,您会意识到的第一件事就是等待整个响应完成需要太长时间。我们没有在 ChatGPT 上注意到这一点,因为它逐个字符地流式传输响应。这是一个重要的用户交互模式,需要牢记在心,因为根据我们的经验,用户只能在旋转器上等待很长时间,然后才会失去耐心。在我们的案例中,我们不希望用户在看到响应(即使是部分响应)之前等待超过几秒钟。
因此,在实现协同驾驶体验时,我们强烈建议在执行需要超过几秒钟才能完成的提示时显示实时进度。在我们的案例中,这意味着将生成流式传输到整个堆栈中,从 LLM 实时返回到 UI。幸运的是,Langchain 和 OpenAI API 提供了执行此操作的功能
const chat = new ChatOpenAI({
temperature: 1,
modelName: 'gpt-3.5-turbo',
streaming: true,
callbackManager: onTokenStream ?
CallbackManager.fromHandlers({
async handleLLMNewToken(token) {
onTokenStream(token)
},
}) : undefined
});
这使我们能够提供创建更流畅的用户体验所需的实时进度,包括在生成的想法不符合用户期望的情况下,能够在生成完成时停止生成
但是,这样做会给您的应用程序逻辑增加很多额外的复杂性,尤其是在视图和控制器方面。在 Boba 的情况下,我们还必须对 JSON 执行尽力解析,并在执行 LLM 调用期间维护时间状态。在撰写本文时,一些新的有希望的库正在问世,这些库使 web 开发人员更容易做到这一点。例如,Vercel AI SDK 是一个用于构建边缘就绪的 AI 驱动的流式文本和聊天 UI 的库。
选择和携带上下文
捕获并添加相关上下文信息到后续操作
聊天界面的最大限制之一是用户仅限于单线程上下文:对话聊天窗口。在设计协同驾驶体验时,我们建议深入思考如何设计 UX 辅助功能,以便在选择的上下文中执行操作,类似于我们在现实生活中指向某物的自然倾向,以作为操作或描述的上下文。
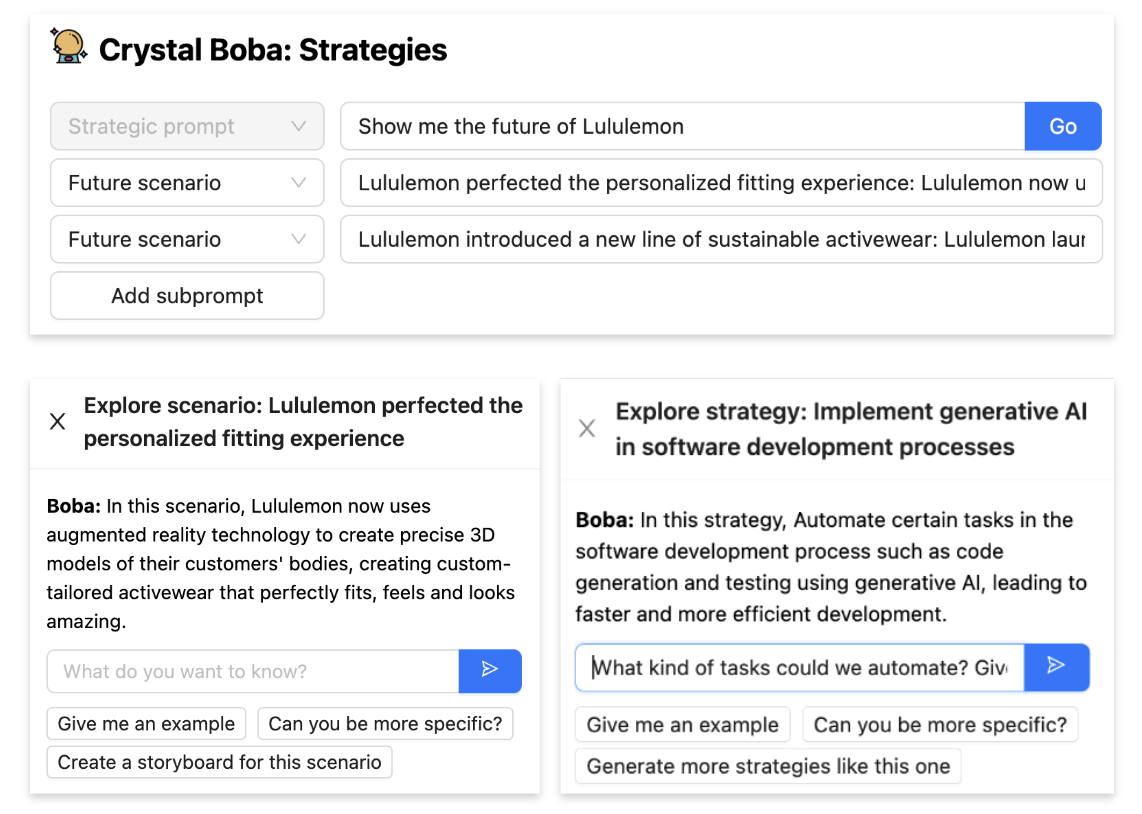
选择和携带上下文 允许用户缩小或扩大交互范围以执行后续任务 - 也称为任务上下文。这通常通过在用户界面中选择一个或多个元素,然后对它们执行操作来完成。例如,在 Boba 的情况下,我们使用此模式来允许用户通过选择它(例如,场景、策略或原型概念)来进行关于想法的更窄、更集中的对话,以及选择和生成概念的变体。首先,用户选择一个想法(通过复选框显式选择,或通过单击链接隐式选择)
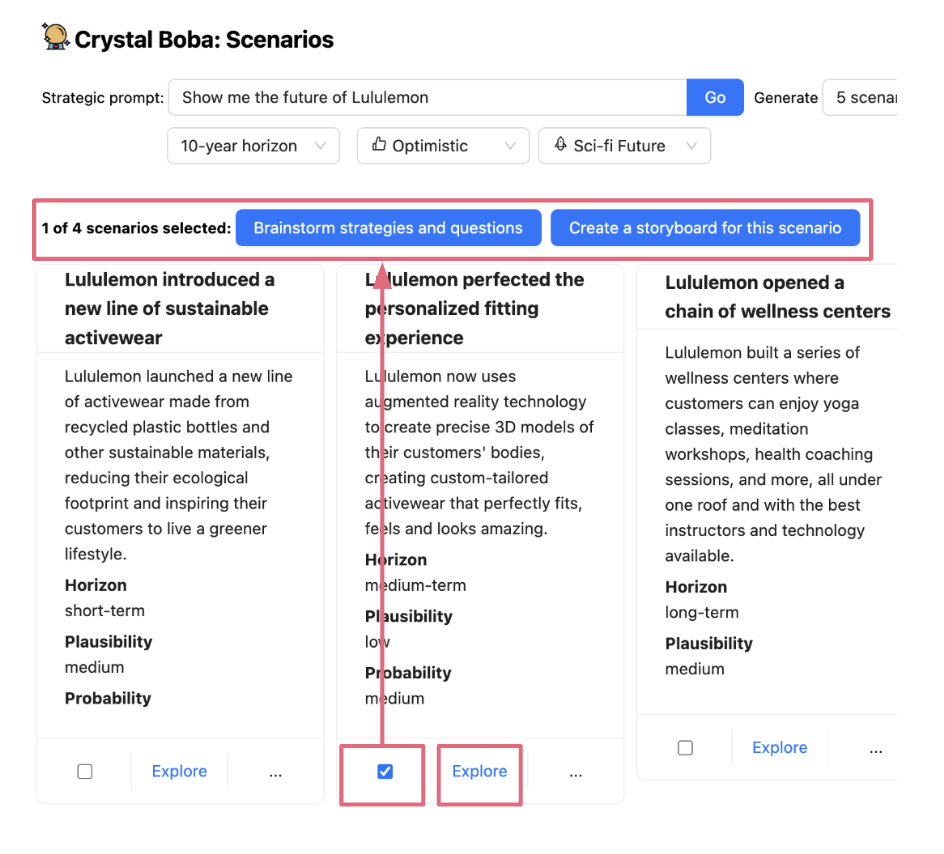
然后,当用户对选择执行操作时,所选项目将作为上下文传递到新任务中,例如,当用户单击“为该场景集思广益策略和问题”时,作为场景子提示用于策略生成,或者当用户单击“探索”时,作为自然语言对话的上下文
根据您希望为一段对话/交互建立的上下文的性质和长度,实现 选择和携带上下文 可能非常容易,也可能非常困难。当上下文很简短并且可以放入单个 LLM 上下文窗口(LLM 支持的提示的最大大小)时,我们只需通过提示工程就可以实现它。例如,在 Boba 中,如上所示,您可以单击某个想法上的“探索”,并与 Boba 就该想法进行对话。我们在后端实现此功能的方式是创建多消息聊天对话
const chatPrompt = ChatPromptTemplate.fromPromptMessages([
HumanMessagePromptTemplate.fromTemplate(contextPrompt),
HumanMessagePromptTemplate.fromTemplate("{input}"),
]);
const formattedPrompt = await chatPrompt.formatPromptValue({
input: input
})
实现 选择和携带上下文 的另一种技术是在提示中通过在标签分隔符内提供上下文来实现,如下所示。在这种情况下,用户选择了多个场景,并希望为这些场景生成策略(这是一种通常用于场景构建和想法压力测试的技术)。我们希望传递到策略生成的上下文是所选场景的集合
Your questions and strategies must be specific to realizing the following
potential future scenarios (if any)
<scenarios>
{scenarios_subprompt}
</scenarios>
但是,当您的上下文超出 LLM 的上下文窗口,或者您需要提供更复杂的过去交互链时,您可能必须诉诸使用外部短期记忆,这通常涉及使用向量存储(内存中或外部)。我们将在 嵌入式外部知识 中提供如何执行类似操作的示例。
如果您想了解如何在生成式应用程序中有效地使用选择和上下文,我们强烈建议您观看 Notion 的 Linus Lee 在“生产中的 LLM”大会上发表的演讲:“超越聊天的生成式体验”。
上下文对话
允许在上下文中与 LLM 直接对话。
这是 选择和携带上下文 的一个特例。虽然我们希望 Boba 尽可能摆脱聊天窗口交互模式,但我们发现,为用户提供一个“回退”通道来直接与 LLM 对话仍然非常有用。这使我们能够为 UI 不支持的交互提供对话体验,并支持在进行文本自然语言对话对用户最有意义的情况下进行对话。
在下面的示例中,用户正在与 Boba 聊天,讨论 Rogers Sportsnet 提供的个性化精彩集锦的概念。完整的上下文作为聊天消息提及(“在这个概念中,发现您喜爱的体育世界...”),用户要求 Boba 为该概念创建一个用户旅程。LLM 的响应以 Markdown 格式化并呈现
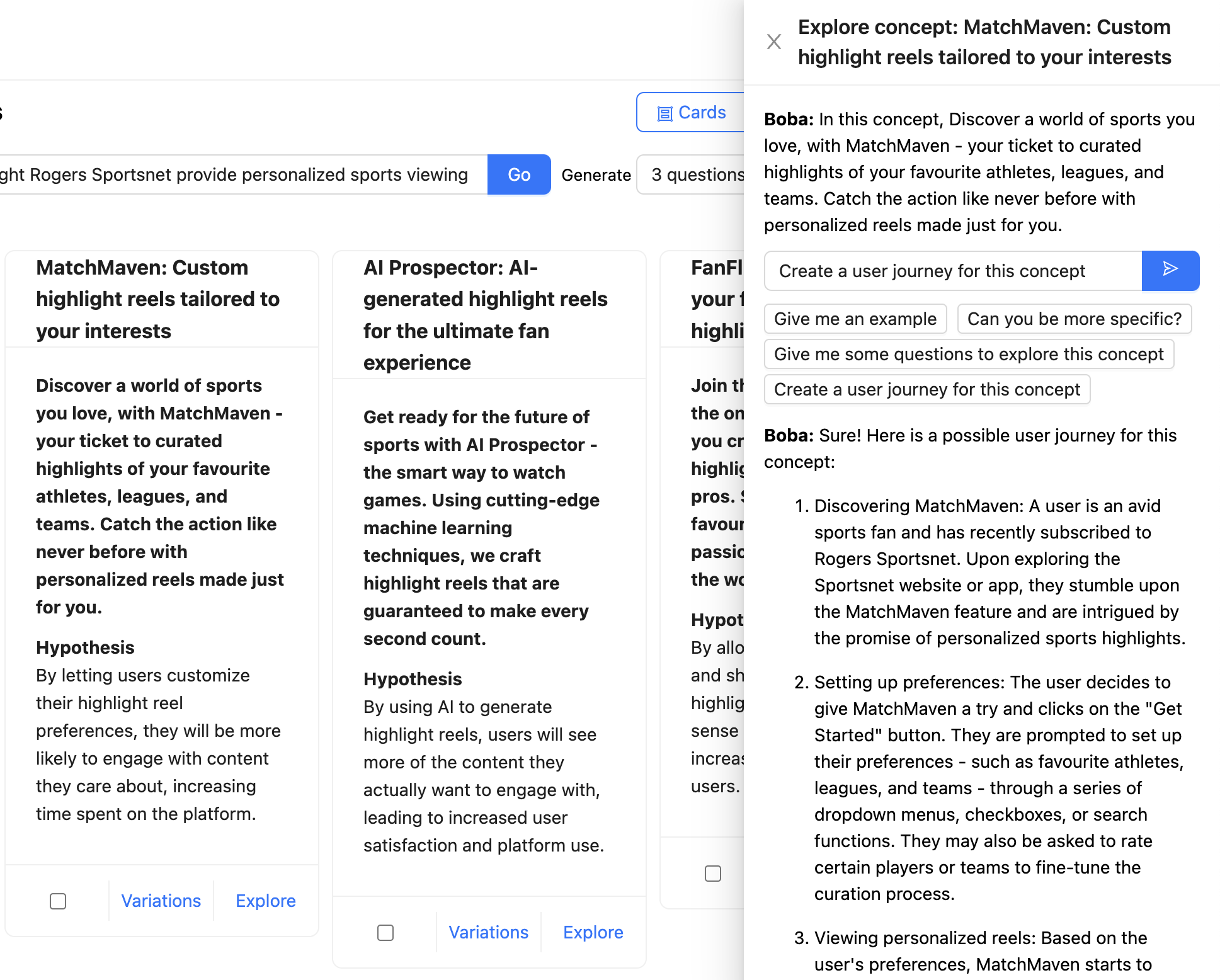
在设计生成式协同驾驶体验时,我们强烈建议支持与您的应用程序进行上下文对话。确保提供用户可以发送到您的应用程序的有用消息的示例,以便他们知道可以进行哪种对话。在 Boba 的情况下,如上面的屏幕截图所示,这些示例作为输入框下的消息模板提供,例如“您能更具体一些吗?”
大声思考
告诉 LLM 在回答时生成中间结果
虽然 LLM 实际上并不“思考”,但值得用 OpenAI 的 Andrei Karpathy 的一句话来比喻地思考:“LLM 在‘标记’中‘思考’。” 他的意思是,GPT 在尝试立即回答问题时,往往会犯更多推理错误,而当你给他们更多时间(即更多标记)来“思考”时,则不会。在构建 Boba 时,我们发现使用“思维链”(CoT)提示,或者更具体地说,在回答之前要求进行推理链,有助于 LLM 推理出更高质量和更相关的响应。
在 Boba 的某些部分,例如策略和概念生成,我们要求 LLM 生成一组问题,这些问题扩展了用户的输入提示,然后生成想法(在这种情况下是策略和概念)。
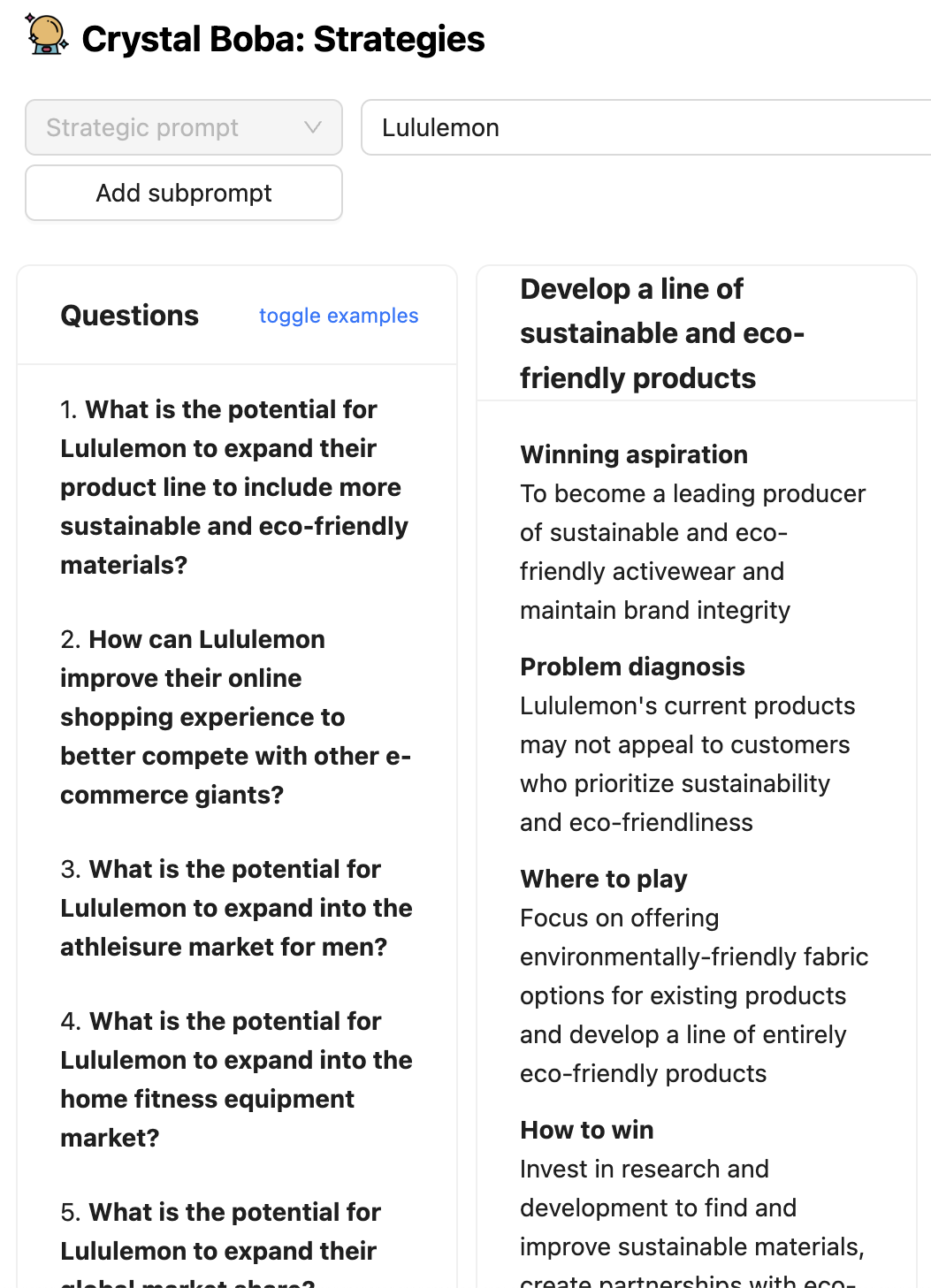
虽然我们显示了 LLM 生成的这些问题,但这种模式的另一个同样有效的变体是实现用户看不到的内部独白。在这种情况下,我们会要求 LLM 思考他们的响应,并将该内部独白放入响应的另一个部分,我们可以解析并忽略该部分,以便在显示给用户的结果中忽略它。OpenAI 的 GPT 最佳实践指南 中的“让 GPT 有时间‘思考’”部分中提供了对此模式的更详细描述
作为生成式应用程序的用户体验模式,我们发现,在适当的情况下,与用户分享推理过程很有帮助,这样用户就可以有额外的上下文来迭代下一个操作或提示。例如,在 Boba 中,了解 Boba 想到的各种问题,可以为用户提供更多关于不同领域进行探索或不进行探索的想法。它还允许用户要求 Boba 在下次迭代中排除某些类别的问题。如果您确实走上了这条道路,我们建议创建一个 UI 辅助功能来隐藏独白或思维链,例如 Boba 的功能,可以切换上面显示的示例。
迭代响应
为用户提供与协同驾驶员进行来回交互的辅助功能
LLM 可能会误解用户的意图,或者仅仅生成不符合用户期望的响应。因此,您的生成式应用程序也是如此。区分 ChatGPT 与传统聊天机器人的最强大功能之一是能够灵活地迭代和细化对话的方向,从而提高生成的响应的质量和相关性。
同样,我们认为,生成式协同驾驶体验的质量取决于用户与协同驾驶员进行流畅的来回交互的能力。这就是我们所说的“迭代响应”模式。这可能涉及几种方法
- 更正提供给应用程序/LLM 的原始输入
- 细化协同驾驶员对用户的响应的一部分
- 提供反馈以将应用程序引导到不同的方向
我们在 Boba 中实现 迭代响应 的一个示例是在故事板中。给定一个提示(简短或详细),Boba 可以生成一个视觉故事板,其中包含多个场景,每个场景都有一个叙事脚本和一个使用 Stable Diffusion 生成的图像。例如,下面是一个描述“未来酒店”体验的部分故事板
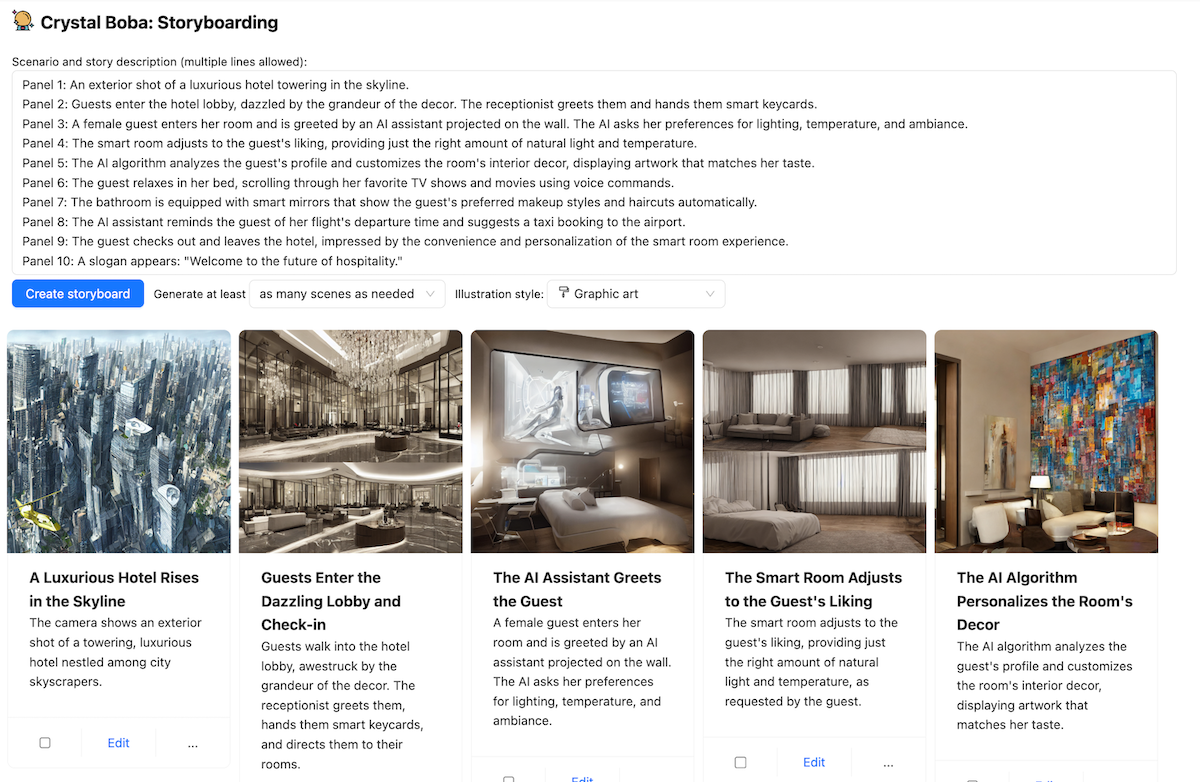
由于 Boba 使用 LLM 生成 Stable Diffusion 提示,我们无法确定生成的图像质量如何,因此此功能有点碰运气。为了弥补这一点,我们决定为用户提供迭代图像提示的功能,以便他们可以针对特定场景优化图像。用户只需点击图像,更新 Stable Diffusion 提示,然后点击“完成”,Boba 就会使用更新后的提示生成新图像,同时保留故事板的其余部分。
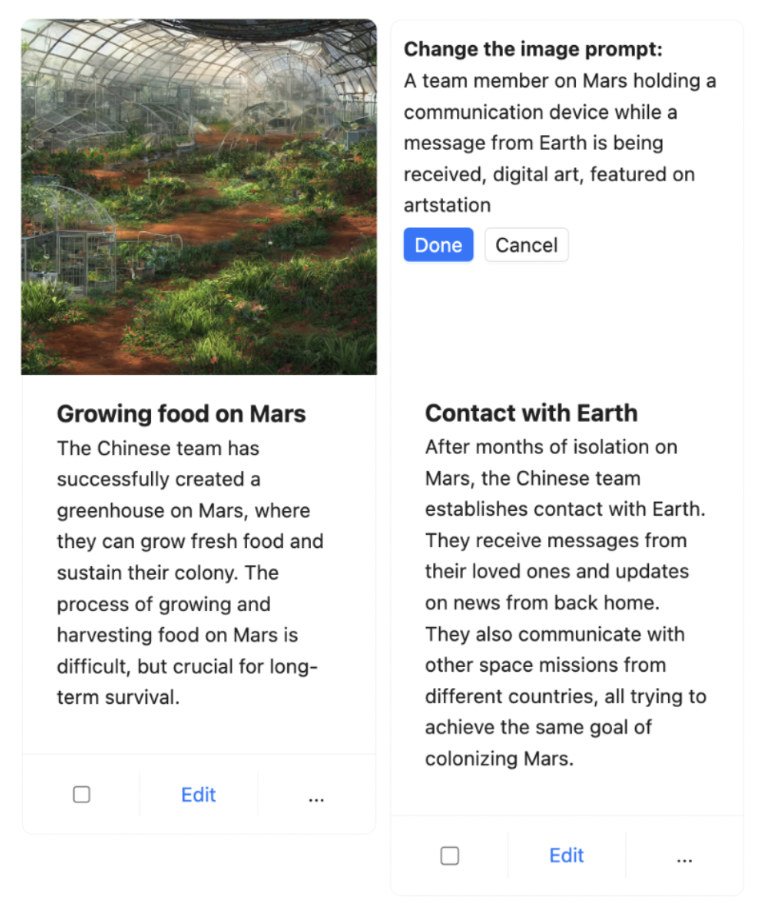
另一个我们正在开发的 迭代响应 示例是允许用户对 Boba 生成的想法质量提供反馈的功能,这将结合 选择和保留上下文 和 迭代响应。一种方法是为想法点赞或点踩,让 Boba 将该反馈纳入新的或下一组建议中。另一种方法是使用自然语言提供对话式反馈。无论哪种方式,我们都希望以支持强化学习的方式进行(随着您提供更多反馈,想法会变得更好)。一个很好的例子是 Github Copilot,它会降低用户忽略的代码建议在下一个最佳代码建议中的排名。
我们认为,这是实现有效生成体验的最重要模式之一,尽管它具有通用性。具有挑战性的是将反馈的上下文纳入后续响应,这通常需要在您的应用程序中实现短期或长期记忆,因为上下文窗口的大小有限。
嵌入外部知识
将 LLM 与其他信息源结合使用,以访问超出 LLM 训练集的数据
正如本文前面提到的,您的生成应用程序通常需要 LLM 整合外部工具(例如 API 调用)或外部记忆(短期或长期)。我们在 Boba 中实现“研究”功能时遇到了这种情况,该功能允许用户根据网络上公开可用的信息回答定性研究问题,例如“酒店行业目前如何使用生成式 AI?”
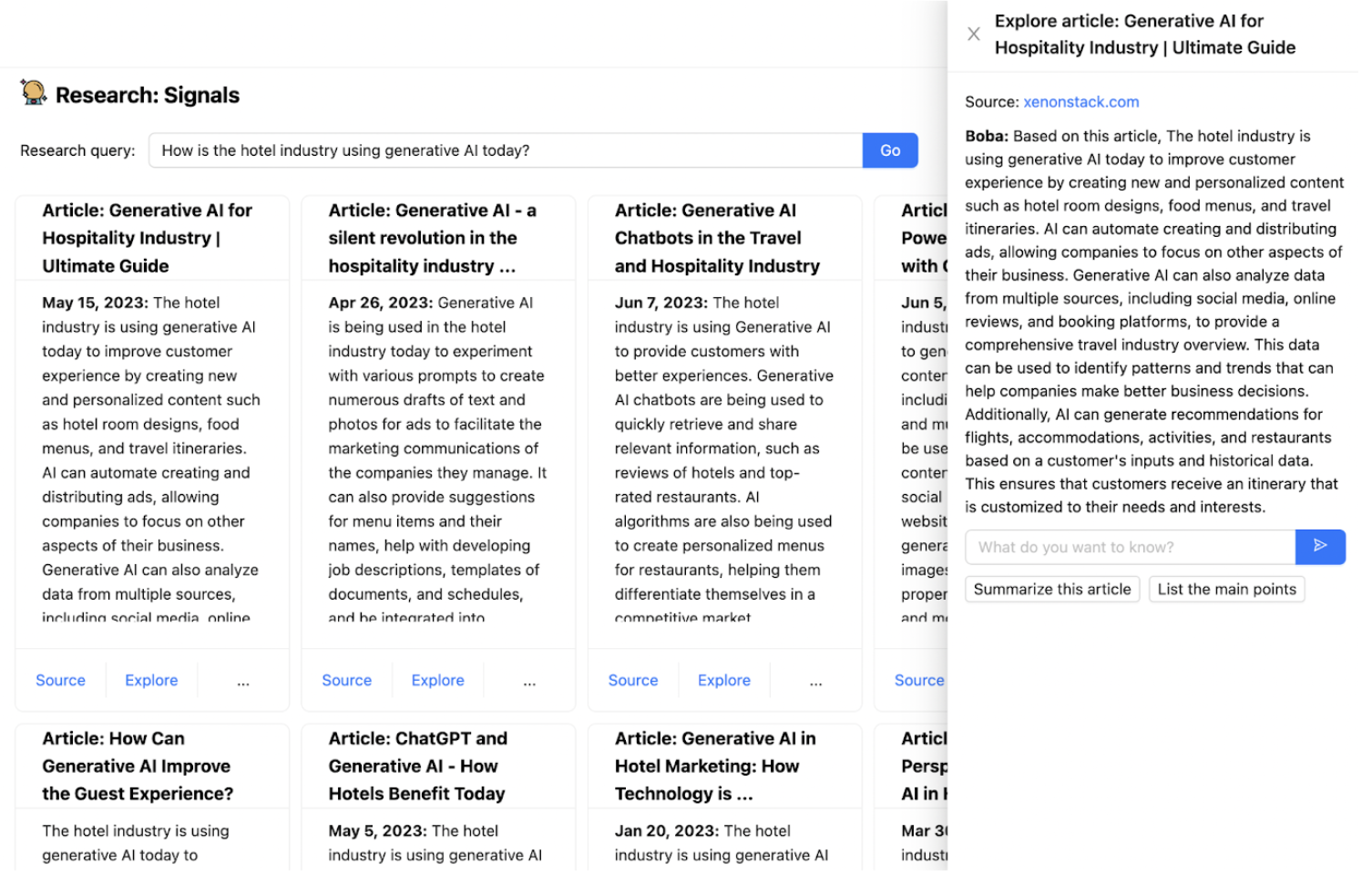
为了实现这一点,我们必须为 LLM “配备” Google 作为外部网络搜索工具,并赋予 LLM 读取可能不适合提示上下文窗口的较长文章的能力。我们还希望 Boba 能够与用户就用户找到的任何相关文章进行聊天,这需要实现某种形式的短期记忆。最后,我们希望为用户提供用于回答用户研究问题的正确链接和参考文献。
我们在 Boba 中实现此功能的方式如下:
- 使用 Google SERP API 根据用户的查询执行网络搜索,并获取前 10 篇文章(搜索结果)。
- 使用 Extract API 读取每篇文章的完整内容。
- 将每篇文章的内容保存在短期记忆中,具体来说是内存中的向量存储。向量存储的嵌入使用 OpenAI API 生成,并基于每篇文章的片段(而不是嵌入整篇文章本身)。
- 生成用户搜索查询的嵌入。
- 使用搜索查询的嵌入查询向量存储。
- 提示 LLM 以自然语言回答用户的原始查询,同时将向量存储查询结果作为上下文添加到 LLM 提示中。
这听起来可能有很多步骤,但这就是使用 Langchain 之类的工具可以加快您的流程的地方。具体来说,Langchain 具有一个名为 VectorDBQAChain 的端到端链,使用它来执行问答在 Boba 中只需要几行代码。
const researchArticle = async (article, prompt) => {
const model = new OpenAI({});
const text = article.text;
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000 });
const docs = await textSplitter.createDocuments([text]);
const vectorStore = await HNSWLib.fromDocuments(docs, new OpenAIEmbeddings());
const chain = VectorDBQAChain.fromLLM(model, vectorStore);
const res = await chain.call({
input_documents: docs,
query: prompt + ". Be detailed in your response.",
});
return { research_answer: res.text };
};
文章文本包含文章的全部内容,这可能不适合单个提示。因此,我们执行上述步骤。如您所见,我们使用了名为 HNSWLib(分层可导航小世界)的内存中向量存储。HNSW 图是用于向量相似性搜索的最佳索引之一。但是,对于更大规模的用例和/或长期记忆,我们建议使用外部向量数据库,例如 Pinecone 或 Weaviate。
我们还可以通过使用 Langchain 的外部工具 API 执行 Google 搜索来进一步简化我们的工作流程,但我们决定不这样做,因为它将过多的决策权交给了 Langchain,并且我们获得了混合的、缓慢的、难以解析的结果。实现外部工具的另一种方法是使用 Open AI 最近发布的 函数调用 API,我们之前在本文中提到了它。
总之,我们结合了两种不同的技术来实现 嵌入外部知识:
- 使用外部工具:使用 Google SERP 和 Extract API 搜索和读取文章。
- 使用外部记忆:使用内存中向量存储(HNSWLib)的短期记忆。
未来计划和模式
到目前为止,我们只触及了 Boba 原型的表面,以及产品策略和生成式构思的生成式协同驾驶员可能包含的内容。关于构建 LLM 支持的生成式协同驾驶员应用程序的艺术,还有很多东西要学习和分享,我们希望在接下来的几个月内做到这一点。这是一个激动人心的时代,可以开发这种新型的应用程序和体验,我们相信许多原则、模式和实践还有待发现!
重大修订
2023 年 6 月 29 日:首次发布